基于卷积神经网络和时域金字塔池化的语音情感分析
一、概述
这是最近学习《Speech Emotion Recognition Using Deep
Convolutional Neural Network and Discriminant
Temporal Pyramid Matching》时所做的笔记和代码实现。
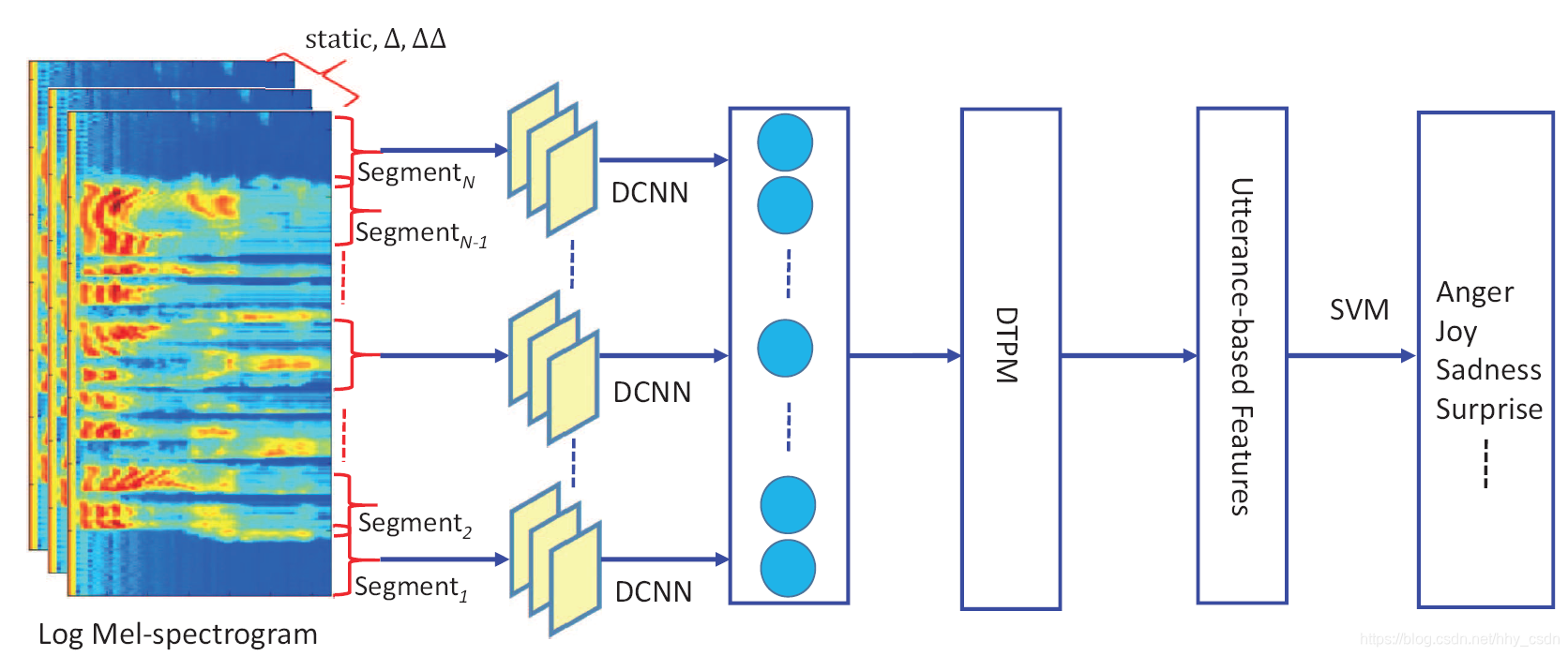
论文使用卷积神经网络和时域金字塔匹配来提取和识别语音信号中的情感特征。主要思路如下:对音频信号提取其梅尔谱图,在时域上有重叠地切割成64*64的图像块;将其送入AlexNet结构的CNN中进行分类,提取到特征向量
;对同一个音频样本的向量集
应用时域金字塔特征池化方法,得到描述整个音频样本的定长特征向量;使用SVM加以分类,完成情感识别。
二、数据集介绍
实验采用的数据集是EMO-DB语音情感数据集,下载地址是 http://emodb.bilderbar.info/download/ 。音频的采样频率16kHz,每一个点用16bit的长度存储。数据集不大,只有535条语音数据,情感的标签在文件名的倒数第二位记录着。如下图,‘F’,‘N’,'W’都是不同的情感标签。
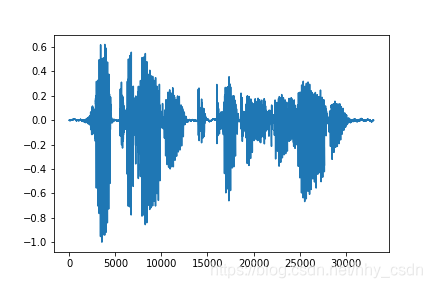
每一条音频文件打开之后,将每点幅值画出来,就是下图。
详细的标签对照如下表,数据集都是以德语单词的首字母标记的,也就是下表的右两列。
| letter | emotion(English) | letter | emotion(German) |
|---|---|---|---|
| A | anger | W | Ärger |
| B | boredom | L | Langeweile |
| D | disgust | E | Ekel |
| F | anxiety/fear | A | Angst |
| H | happiness | F | Freude |
| S | sadness | T | Trauer |
| N | neutral version | N | neutral version |
三、梅尔谱图提取
声谱图(语谱图)、梅尔谱图(Mel Spectrum)、梅尔倒谱(MFCC)是语音信号处理时常用的特征提取手段,在深度学习没有得到应用之前,MFCC等特征和隐马尔科夫模型等传统机器学习模型的结合是语音识别、语音情感识别的常用手段。
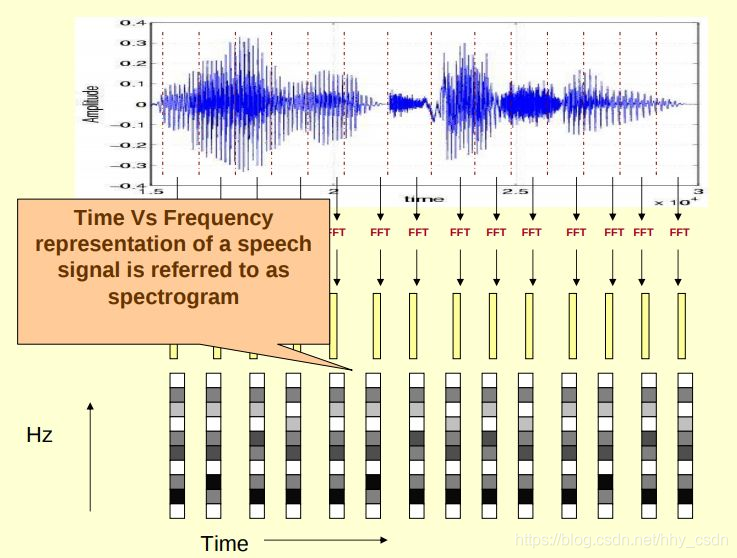
声谱图的生成主要用到短时傅里叶变换(STFT,Short Time Fourier Transform)。假设有一段时域上的语音信号 ,在时域上将其分割成重叠或不重叠的 个片段 ,在每个片段 上做傅里叶变换,得到频域信号 。对 划分为 段量化,就得到一个 维向量,对应到数字图像上,就是用敏感不同的一列像素点来表示 的幅频响应了。
将 个片段的 维向量沿时域拼接起来,就得到了整段音频的声谱图。声谱图的横向表示时间维度,纵向表示频率维度,体现了视频分析的思想,从图中就能读出什么时间声音的高频分量多,什么时候音频的低频段强度高。
梅尔谱图是在声谱图的基础上用一组符合人类听觉系统频响特性的滤波器组进行滤波处理。这组滤波器就叫梅尔滤波器组,这组滤波器在频域上呈现低频段密集(滤波器多),高频段稀疏(滤波器少),低频段幅频响应大,高频段幅频响应小。人类的听觉系统也符合这样的特性,低频段灵敏,高频段不灵敏。用这样的滤波器组对声谱图作进一步处理,是将“客观存在”的声音形式转换成“人耳听到”的声音形式,因为不论是语音识别还是语音情感识别都是以人类的认知系统为基准的,在信号处理的过程中自然也就要做到和人的感知相似。
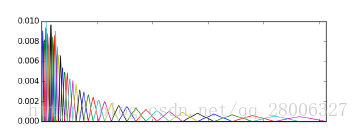
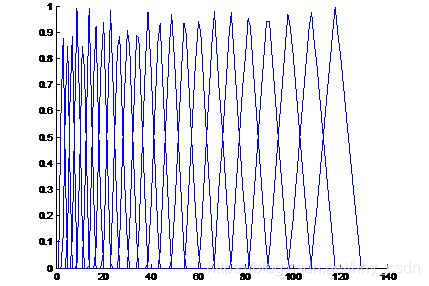
在处理其他声音(比如鸟语)时,就需要登高滤波器组而不是等面积滤波器组。即滤波器组中的各个滤波器的幅频响应强度是一样的,但是滤波器涵盖的频率不一致,即三角形的底边不一样长。如下图。
利用Python实现对语音信号的梅尔谱图的提取非常方便。只需要调用如下程序。
import librosa
# sr=None表示读取音频文件时不指定采样率,按照文件本身的采样率去读取
y, sr = librosa.load(wave_file_dir,sr=None) # y是数字音频信号序列,sr=sampling rate
# 设置滤波器组有64个滤波器,傅里叶变换点数为400,窗函数宽度为401
ps = librosa.feature.melspectrogram(y, sr=sr, n_mels=64,n_fft=400,hop_length=401)
提取特征的细节是这样的。论文中提到,只有约250ms以上的语音信号才包含足够的信息用于识别情感,因此论文中采用长度为25ms的汉明窗,滑动步长10ms的方式(每相邻两次变换有15ms的时域重叠)进行64次STFT-梅尔滤波的处理。总共处理了10*63+25=635ms长的片段。而前面提到,采样频率为16kHz的序列中,16点为1ms,25ms就对应400个点,这也是我选用汉明窗长度为401的原因。
由于语音信号是时域连续的,分帧提取的特征信息只反应了本帧语音(比如25ms的语音片段)的特性,为了使特征更能体现时域连续性,可以在特征维度增加前后帧信息的维度。因此我们还要对梅尔谱图做差分处理,常用的是一阶差分和二阶差分。设
为数字音频信号的数据点,差分计算可写成下式。
mel_spec[:,:,1] = librosa.feature.delta(mel_spec[:,:,0],width=3,order=1) # 一阶差分
mel_spec[:,:,2] = librosa.feature.delta(mel_spec[:,:,0],width=3,order=2) # 二阶差分
通过计算梅尔谱图及其一阶二阶差分,并将其堆叠在一起,我们就得到了一个横向长度和信号持续时间有关、纵向长度和滤波器组有关的三通道彩色图片。这也就是第四部分送入CNN的数据的来源。
参考代码如下
import os,pickle
import numpy as np
import librosa
##############################################
# 从音频文件生成对应标签和梅尔谱图
##############################################
# 数据集路径
wave_file_dir = './data/'
filelist = os.listdir(wave_file_dir)
# 将标签与对应谱图依次存储
mel_and_label = []
for i in range(len(filelist)):
# 读音频文件,不指定采样率
y, sr = librosa.load(wave_file_dir+filelist[i],sr=None)
# number of segments
num_segment = int(np.floor((len(y)-400)/160)) +1
# 生成64*num_segment的梅尔图矩阵
mel_spec = np.zeros((64,num_segment,3))
# 每次生成一列64点的梅尔向量,存到梅尔图矩阵中
for j in range(num_segment):
ps = librosa.feature.melspectrogram(y=y[j*160:j*160+400], sr=sr, n_mels=64,n_fft=400,hop_length=401)
mel_spec[:,j,0] = ps[:,0]
mel_spec[:,:,1] = librosa.feature.delta(mel_spec[:,:,0],width=3,order=1) # 一阶差分
mel_spec[:,:,2] = librosa.feature.delta(mel_spec[:,:,0],width=3,order=2) # 二阶差分
# 每个标签对应一个梅尔图,存到列表中
mel_and_label.append([filelist[i][5]+'_'+str(i),mel_spec])
# 保存数据集
with open('mel_and_label.pkl','wb') as f:
pickle.dump(mel_and_label,f)
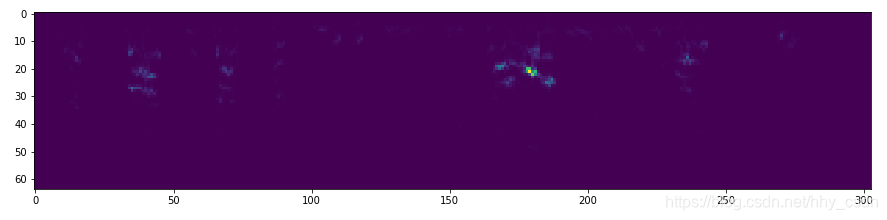
最后我们得到的三通道的梅尔谱图大致是这个样子,注意由于矩阵中有负数,直接用matplotlib.pyplot.imshow()是不行的,需要取一下绝对值再显示。

四、基于卷积神经网络的特征提取
将原始的声音信号转换成梅尔谱图对于情感识别通常是不够的。由于梅尔谱图是二维图像,适合作为CNN的输入。因此,我们在梅尔谱图的基础上继续利用CNN提取高层次的特征。具体地说,是将输入227*227的梅尔谱图映射为一个4096维的特征向量。
完成第三步工作后,还需要对梅尔谱图进行裁剪。图像高度64pixels,宽度也应该是64pixels,通道数为3。需要考虑的是裁切时滑动步长,我取20个pixel。
##############################################
# 从梅尔谱图裁切64*64图像
##############################################
with open('mel_and_label.pkl','rb') as f:
mel_and_label = pickle.load(f)
# 生成梅尔图之后进行裁切,论文中以315ms为滑动步长,生成不了足够多数据
# 以20列pixel为步长进行滑动
crop_stride = 20
# 标签和64*64mel图存储在列表中,标签命名规则 'W_1_1'即 情绪类型+第1段音频+第1个segment
train_and_label_64 = []
# 切图
for i in range(len(mel_and_label)):
temp = mel_and_label[i][1] # mel图
h,w,c =np.shape(mel_and_label[i][1]) # h=64,c=3
# 计算mel图可以切成多少个64*64图
num_crop = int(np.floor((w-64)/crop_stride)) +1
for j in range(num_crop):
# 裁剪64*64*3的区域
temp1 = temp[:,j*20:j*20+64,:]
#temp1 = cv2.resize(temp[:,j*20:j*20+64,:],(227,227))
train_and_label_64.append([mel_and_label[i][0]+'_'+str(j) , temp1])
卷积神经网络采用AlexNet的结构,所以还需要将
的图像resize到
。cv2.resize默认的数据格式是float64,也就是double类型,特别占用内存,容易爆掉。所以要特别小心,这里我采用半精度格式float16,实验证明半精度对最后结果没什么影响。
# resize到227*227*3
# 容易爆内存,分段执行
train_and_label_227 = []
for i in range(len(train_and_label_64)):
temp = cv2.resize(train_and_label_64[i][1],(227,227)).astype('float16')
train_and_label_227.append([train_and_label_64[i][0] , temp])
下一步是网络的搭建和训练。打标签的时候注意,从一个音频文件中生成的
的图像都打成同一个情感标签,采用one-hot编码。train_227是训练集,数据尺寸(N,227,227,3),label_227_one_hot是标签文件,数据格式(N,7),打标签的代码就不写了。网络训练的对应代码如下。
# 参数设置
batch_size = 32
epochs = 50
img_rows, img_cols = 227, 227 # 输入图片尺寸
input_shape = (img_rows, img_cols, 3)
model_name = './model/alexnet_50epoch.h5'
X_train = train_227
y_train = label_227_one_hot
#X_test = train_img[0:900]/train_img[0:900].max()
#y_test = train_label[0:900]
print('X_train shape:', X_train.shape)
print(X_train.shape[0], 'train samples')
#AlexNet
model = Sequential()
model.add(Conv2D(96,(11,11),strides=(4,4),input_shape=(227,227,3),padding='valid',activation='relu',kernel_initializer='uniform'))
model.add(MaxPooling2D(pool_size=(3,3),strides=(2,2)))
model.add(Conv2D(256,(5,5),strides=(1,1),padding='same',activation='relu',kernel_initializer='uniform'))
model.add(MaxPooling2D(pool_size=(3,3),strides=(2,2)))
model.add(Conv2D(384,(3,3),strides=(1,1),padding='same',activation='relu',kernel_initializer='uniform'))
model.add(Conv2D(384,(3,3),strides=(1,1),padding='same',activation='relu',kernel_initializer='uniform'))
model.add(Conv2D(256,(3,3),strides=(1,1),padding='same',activation='relu',kernel_initializer='uniform'))
model.add(MaxPooling2D(pool_size=(3,3),strides=(2,2)))
model.add(Flatten())
model.add(Dense(4096,activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(4096,activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(7,activation='softmax'))
#ZF-Net
#model = Sequential()
#model.add(Conv2D(96,(7,7),strides=(2,2),input_shape=input_shape,padding='valid',activation='relu',kernel_initializer='uniform'))
#model.add(MaxPooling2D(pool_size=(3,3),strides=(2,2)))
#model.add(Conv2D(256,(5,5),strides=(2,2),padding='same',activation='relu',kernel_initializer='uniform'))
#model.add(MaxPooling2D(pool_size=(3,3),strides=(2,2)))
#model.add(Conv2D(384,(3,3),strides=(1,1),padding='same',activation='relu',kernel_initializer='uniform'))
#model.add(Conv2D(384,(3,3),strides=(1,1),padding='same',activation='relu',kernel_initializer='uniform'))
#model.add(Conv2D(256,(3,3),strides=(1,1),padding='same',activation='relu',kernel_initializer='uniform'))
#model.add(MaxPooling2D(pool_size=(3,3),strides=(2,2)))
#model.add(Flatten())
#model.add(Dense(4096,activation='relu'))
#model.add(Dropout(0.5))
#model.add(Dense(4096,activation='relu'))
#model.add(Dropout(0.5))
#model.add(Dense(7,activation='softmax'))
model.summary()
#编译模型
# adam = optimizers.Adam(decay=0.9)
sgd = optimizers.SGD(momentum=0.9,lr=0.001,decay=1e-6)
model.compile(loss='categorical_crossentropy', # model.compile(loss='categorical_crossentropy', #
optimizer=sgd,
metrics=['accuracy'])
model.fit(X_train, y_train,
epochs=epochs,
batch_size=batch_size,
shuffle=True,verbose=1)
#validation_data =(X_test,y_test)
model.save(model_name)
#评估模型
score = model.evaluate(X_train, y_train, verbose=1)
print('Test score:', score[0])
print('Test accuracy:', score[1])
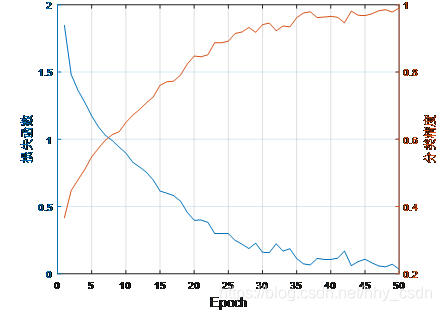
训练结果如下所示,训练到50epoch时已经接近收敛了,但是似乎还可以再多训练几代,毕竟作者用0.001的学习率训练了300个epoch。
将训练好的模型的倒数第二层提取出来构建新的模型,并将之前的训练数据再跑一边前馈,得到每个227*227图的4096D向量。
# 提取模型倒数第二层的4096全连接为输出segment向量
segment_feature_model = Model(inputs=model.input,outputs=model.layers[11].output)
#以这个model的预测值作为输出
segment_feature = segment_feature_model.predict(train_227)
五、时域金字塔特征池化
在提取到描述梅尔谱图的特征向量之后,下面要解决的问题是“对不同时间长度的语音信号怎样得到统一长度的特征”。因为在裁切梅尔谱图的过程中,一个样本能切多少张 的图是由其信号长度决定的,这样我们就可能得到这样两个样本:一个样本持续3s,最终按时间顺序切成10个 的图像,再经过resize得到10个 的图像,最后经过CNN得到10个4096D的特征向量;另一个样本只有2s,最后得到8个4096D的向量。这样不定长度的情感特征是没法进行分类和识别的,所以需要进行特征池化。
论文中用的方法称为时域金字塔匹配(Temporal Pyramid Matching),其实就是一种池化手段,只不过用上了金字塔结构和p参数的学习。它主要包括两部分:金字塔池化、Lp-Norm的参数p的学习。
时域金字塔池化的思想非常简单,也易于理解。读过SPP-Net的可能知道,它借助了空间金字塔池化(Spatial Pyramid Pooling)的思想。在这里有必要先介绍一下空域金字塔池化。
空域金字塔池化是解决不同尺寸的feature map提取定长特征向量的算法。不论feature map的尺寸如何,都可以将其分成44的子区域,22的子区域和1*1的区域(就是不分区域),然后在每个区域上做池化,提取一个定长的特征向量,最后将所有层的所有子区域上提取的特征向量都拼起来,就得到最后的定长向量了。
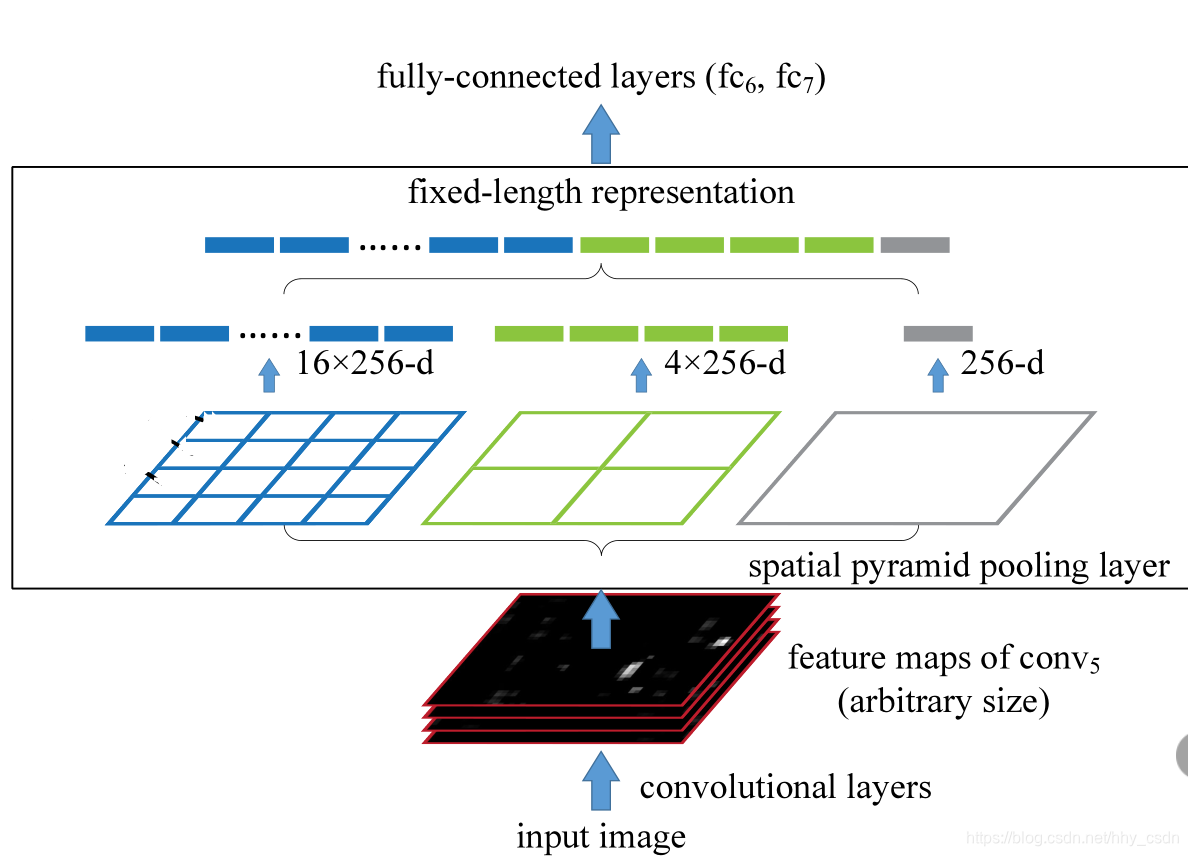
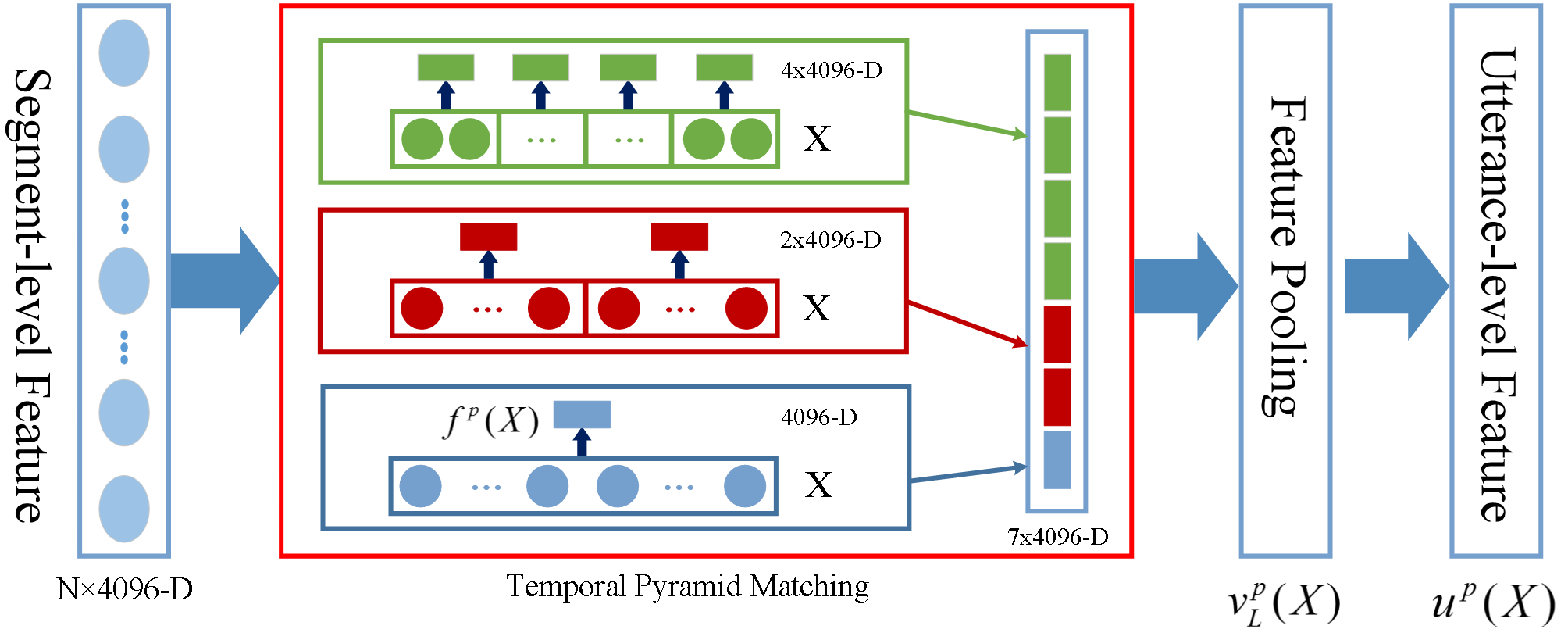
时域金字塔池化是一样的道理。如下图:
1)将同一个音频样本的所有特征向量(
)按时间顺序排列好;
2)将其分成1、2、4等份,对每一等份应用如下公式进行池化,将所有向量拼起来,得到
;
3)对
再应用池化规则,得到
作为最终的全局特征,论文中叫utterance level feature,由于涵盖了整个句子的情感信息,所以我翻译成“话语级特征”;
4)如下的公式中参数
的取值有最优解,论文中采用边界费舍尔分析(MFA,Marginal Fisher Analysis)来优化,不是很懂,就没做代码复现。
下面来看这个公式。式中
代表
个4096维的向量。若
则表示对
个向量的对应维度上相加再取平均,也就是均值池化;若
,则表示在向量每一个维度上取最大值,也就是最值池化。这个公式的理解可以和范数的概念结合起来。
在实验中,我没有对参数
进行优化,而是直接用均值池化来做的,如果有哪位大佬实现了MFA算法,欢迎在下面交流学习,不胜感激。另外一个注意的问题是,实验中会遇到某些音频样本切出来的片段(也就是最后映射成的4096维向量)的数量
不能被4整除。为了能使用时域金字塔池化,我将多余的向量丢弃,以满足要求,感兴趣的朋友可以试一下:将最后一个4096向量重复m次;或对前几个向量进行插值m次 来进行扩充。
# 记录每个音频有几个segment
count = np.zeros((535),np.int16)
for i in range(len(train_and_label_227)):
count[int(train_and_label_227[i][0].split('_')[1])] +=1
# 将每个音频的segment数约化为4的倍数
for i in range(len(count)):
count[i] -= count[i]%4
# 生成一个列表,记录每个segment属于哪个音频
segment_belong = []
for i in range(len(train_and_label_227)):
segment_belong.append(int(train_and_label_227[i][0].split('_')[1]))
# 生成一个列表,记录535个音频各自的第一个segment在5944中的位置(内存寻址)
first_segment_dir = []
flag = 0
for i in range(len(segment_belong)):
if segment_belong[i] == flag:
first_segment_dir.append(i)
flag +=1
# 存储每个utterance的4的整数倍个4096feature以及utterance对应分类标签
utterance_segment_feature_and_label = []
# 遍历所有utterance 循环535次
for i in range(len(count)):
if i == 247: # count[247]==0
# 只拼一个4096向量
utterance_segment_feature_and_label.append([mel_and_label[i][0][0],[ segment_feature[first_segment_dir[i]] ]])
if i != 247:
temp = [] # 包含两个元素,标签、若干个4096向量
temp1 = [] # 存储一个utterance的若干4096向量
temp.append(mel_and_label[i][0][0]) # 字母WFLEATN,情绪标签
# 第i个utterance的第一个segment在segment_feature中的地址
first_dir = first_segment_dir[i]
# 地址偏移量
add_dir = 0
for j in range(count[i]): # count[i]储存每个utterance对应多少个segment
temp1.append(segment_feature[first_dir+add_dir])
add_dir +=1 # 地址指针指向第i个utterance的下一个segment
temp.append(temp1)
utterance_segment_feature_and_label.append(temp)
if i %10==0:
print(i)
##########################################
# 特征池化
##########################################
with open('utterance_segment_feature_and_label.pkl','rb') as f:
utterance_segment_feature_and_label = pickle.load(f)
# 均值池化
layer1 = [] # 金字塔第1层特征,535个,
layer2 = [] # 金字塔第2层特征,535*2个
layer3 = [] # 金字塔第3层特征,535*4个
for i in range(len(utterance_segment_feature_and_label)):
avg_layer1 = np.zeros((4096))
for j in range(len(utterance_segment_feature_and_label[i][1])):
avg_layer1 += utterance_segment_feature_and_label[i][1][j]
avg_layer1 /= len(utterance_segment_feature_and_label[i][1])
layer1.append(avg_layer1)
avg_layer2 = np.zeros((2,4096))
for j in range( int(len(utterance_segment_feature_and_label[i][1])/2) ):
avg_layer2[0] += utterance_segment_feature_and_label[i][1][j]
for j in range( int(len(utterance_segment_feature_and_label[i][1])/2) ):
avg_layer2[1] += utterance_segment_feature_and_label[i][1][j+int(len(utterance_segment_feature_and_label[i][1])/2)]
if i != 247:
avg_layer2 /= int(len(utterance_segment_feature_and_label[i][1])/2)
if i == 247:
avg_layer2 /= len(utterance_segment_feature_and_label[i][1])
layer2.append(avg_layer2)
avg_layer3 = np.zeros((4,4096))
for j in range( int(len(utterance_segment_feature_and_label[i][1])/4) ):
avg_layer3[0] += utterance_segment_feature_and_label[i][1][j]
for j in range( int(len(utterance_segment_feature_and_label[i][1])/4) ):
avg_layer3[1] += utterance_segment_feature_and_label[i][1][j+int(len(utterance_segment_feature_and_label[i][1])/4)]
for j in range( int(len(utterance_segment_feature_and_label[i][1])/4) ):
avg_layer3[2] += utterance_segment_feature_and_label[i][1][j+2*int(len(utterance_segment_feature_and_label[i][1])/4)]
for j in range( int(len(utterance_segment_feature_and_label[i][1])/4) ):
avg_layer3[3] += utterance_segment_feature_and_label[i][1][j+3*int(len(utterance_segment_feature_and_label[i][1])/4)]
if i != 247:
avg_layer3 /= int(len(utterance_segment_feature_and_label[i][1])/4)
if i == 247:
avg_layer3 /= len(utterance_segment_feature_and_label[i][1])
layer3.append(avg_layer3)
# utterance级特征池化
# 均值池化
utterance_feature = np.zeros((535,4096))
for i in range(len(utterance_feature)):
utterance_feature[i] += 0.25*layer1[i] + 0.5*layer2[i][0] + 0.5*layer2[i][1] + layer3[i][0] + layer3[i][1] + layer3[i][2] + layer3[i][3]
utterance_feature[i] /= 7
utterance_label = np.zeros((535))
for i in range(len(utterance_label)):
if utterance_segment_feature_and_label[i][0] == 'W':
utterance_label[i] = 0
if utterance_segment_feature_and_label[i][0] == 'L':
utterance_label[i] = 1
if utterance_segment_feature_and_label[i][0] == 'E':
utterance_label[i] = 2
if utterance_segment_feature_and_label[i][0] == 'A':
utterance_label[i] = 3
if utterance_segment_feature_and_label[i][0] == 'F':
utterance_label[i] = 4
if utterance_segment_feature_and_label[i][0] == 'T':
utterance_label[i] = 5
if utterance_segment_feature_and_label[i][0] == 'N':
utterance_label[i] = 6
六、SVM分类
这一步没什么好说的,对535条样本数据(每一条是4096维向量)进行分类,采用的是Scikit-learn的SVM API。在训练之前,将数据充分混洗(其实对SVM没啥影响,毕竟只是找support vector)。
# 充分混洗数据
utterance_feature_label = []
for i in range(len(utterance_feature)):
utterance_feature_label.append([utterance_label[i],utterance_feature[i]])
for i in range(100):
random.shuffle(utterance_feature_label)
with open('utterance_feature_label_shuffle.pkl','wb') as f:
pickle.dump(utterance_feature_label,f)
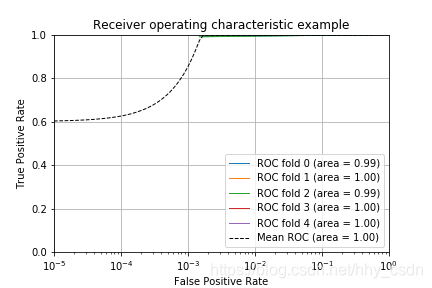
用交叉验证的方式来做SVM超参数的调优。同时画出ROC曲线。我做的结果不太对,以后得改一下。
###############################################################################
# 画ROC曲线
###############################################################################
# 读入数据
with open('utterance_feature_label_shuffle.pkl','rb') as f:
utterance_feature_label = pickle.load(f)
utterance_label = np.zeros((len(utterance_feature_label)))
utterance_feature = np.zeros((len(utterance_feature_label),len(utterance_feature_label[0][1])))
for i in range(len(utterance_feature_label)):
utterance_label[i] = utterance_feature_label[i][0]
utterance_feature[i] = utterance_feature_label[i][1]
# 设置随机数种子
random_state = np.random.RandomState(0)
# 使用n折交叉验证,并且画ROC曲线
# cv是分好了n折的样本序号,分成训练样本的序号、测试样本的序号
cv = StratifiedKFold(utterance_label, n_folds=5)
classifier = svm.SVC(kernel='rbf', #probability=True,
random_state=random_state)#注意这里,probability=True,需要,不然预测的时候会出现异常。另外rbf核效果更好些。
mean_tpr = 0.0 # true positive rate
mean_fpr = np.linspace(0, 1, 100000) # false positive rate
all_tpr = []
for i, (train, test) in enumerate(cv):
# 通过训练数据,使用svm线性核建立模型,并对测试集进行测试,求出预测得分
# probas_ = classifier.fit(X[train], y[train]).predict_proba(X[test]) # 多分类任务无法生成概率值
predict_result = classifier.fit(utterance_feature[train], utterance_label[train]).predict(utterance_feature[test])
# 将预测结果转化为one-hot码矩阵
predict_result_one_hot = to_categorical(predict_result)
# 将正确标签转化为one-hot码矩阵
true_label_one_hot = to_categorical(utterance_label[test])
# 将多分类看做n个二分类任务,画n个ROC曲线
fpr_avg = 0
tpr_avg = 0
for j in range(len(set(utterance_label))):
# Compute ROC curve and area the curve,通过roc_curve()函数,求出fpr和tpr,以及阈值
fpr, tpr, thresholds = roc_curve(true_label_one_hot[:,j], predict_result_one_hot[:,j])
fpr_avg += fpr
tpr_avg += tpr
fpr_avg /= len(set(utterance_label))
tpr_avg /= len(set(utterance_label))
# 对mean_tpr在mean_fpr处进行插值,通过scipy包调用interp()函数
mean_tpr += interp(mean_fpr, fpr_avg, tpr_avg) # interp()返回插值数据维度=mean_fpr的维度
mean_tpr[0] = 0.0 #初始处为0
roc_auc = auc(fpr_avg, tpr_avg)
#画图,只需要plt.plot(fpr,tpr),变量roc_auc只是记录auc的值,通过auc()函数能计算出来
plt.plot(fpr_avg, tpr_avg, lw=1, label='ROC fold %d (area = %0.2f)' % (i, roc_auc))
plt.xscale('log')
plt.xlim((1e-5,1))
#画对角线
#plt.plot([0, 1], [0, 1], '--', color=(0.6, 0.6, 0.6), label='Luck')
plt.xscale('log')
plt.xlim((1e-5,1))
mean_tpr /= len(cv) #在mean_fpr100个点,每个点处插值插值多次取平均
mean_tpr[-1] = 1.0 #坐标最后一个点为(1,1)
mean_auc = auc(mean_fpr, mean_tpr) #计算平均AUC值
#画平均ROC曲线
plt.plot(mean_fpr, mean_tpr, 'k--',label='Mean ROC (area = %0.2f)' % mean_auc, lw=1)
#plt.xlim([-0.05, 1.05])
plt.ylim([0, 1])
plt.grid(True)
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('Receiver operating characteristic example')
plt.legend(loc="lower right")
plt.savefig('ROC.png')
plt.show()
画分类器的混淆矩阵。
###############################################################################
# 画混淆矩阵
###############################################################################
# 读入数据
with open('utterance_feature_label_shuffle.pkl','rb') as f:
utterance_feature_label = pickle.load(f)
utterance_label = np.zeros((len(utterance_feature_label)))
utterance_feature = np.zeros((len(utterance_feature_label),len(utterance_feature_label[0][1])))
for i in range(len(utterance_feature_label)):
utterance_label[i] = utterance_feature_label[i][0]
utterance_feature[i] = utterance_feature_label[i][1]
classifier = svm.SVC(kernel='rbf',gamma='auto')
predict_result = classifier.fit(utterance_feature, utterance_label).predict(utterance_feature)
labels = list(set(utterance_label))
conf_mat = confusion_matrix(utterance_label, predict_result, labels = labels)
drawCM(conf_mat, 'confusion_matrix.png')
from __future__ import division
import numpy as np
from skimage import io, color
from PIL import Image, ImageDraw, ImageFont
import os
def drawCM(matrix, savname):
# Display different color for different elements
lines, cols = matrix.shape
sumline = matrix.sum(axis=1).reshape(lines, 1)
ratiomat = matrix / sumline
toplot0 = 1 - ratiomat
toplot = toplot0.repeat(100).reshape(lines, -1).repeat(100, axis=0)
io.imsave(savname, color.gray2rgb(toplot))
# Draw values on every block
image = Image.open(savname)
draw = ImageDraw.Draw(image)
#font = ImageFont.truetype(os.path.join(os.getcwd(), "draw/ARIAL.TTF"), 15)
for i in range(lines):
for j in range(cols):
dig = str(matrix[i, j])
if i == j:
filled = (255, 181, 197)
else:
filled = (46, 139, 87)
draw.text((100 * j + 20, 100 * i + 20), dig,# font=font
fill=filled)
image.save(savname, 'jpeg')
