问题
《Python Cookbook》中有这么一个问题,给定一个序列,找出该序列出现次数最多的元素。
例如:
words = [ 'look', 'into', 'my', 'eyes', 'look', 'into', 'my', 'eyes', 'the', 'eyes', 'the', 'eyes', 'the', 'eyes', 'not', 'around', 'the', 'eyes', "don't", 'look', 'around', 'the', 'eyes', 'look', 'into', 'my', 'eyes', "you're", 'under' ]
统计出words中出现次数最多的元素?
初步探讨
1、collections模块的Counter类
首先想到的是collections模块的Counter类,具体用法看这里!具体用法看这里!具体用法看这里!https://docs.python.org/3.6/l...,重要的事情强调三遍。
from collections import Counter words = [ 'look', 'into', 'my', 'eyes', 'look', 'into', 'my', 'eyes', 'the', 'eyes', 'the', 'eyes', 'the', 'eyes', 'not', 'around', 'the', 'eyes', "don't", 'look', 'around', 'the', 'eyes', 'look', 'into', 'my', 'eyes', "you're", 'under' ] counter_words = Counter(words) print(counter_words) most_counter = counter_words.most_common(1) print(most_counter)
关于most_common([n]):

2、根据dict键值唯一性和sorted()函数
import operator words = [ 'look', 'into', 'my', 'eyes', 'look', 'into', 'my', 'eyes', 'the', 'eyes', 'the', 'eyes', 'the', 'eyes', 'not', 'around', 'the', 'eyes', "don't", 'look', 'around', 'the', 'eyes', 'look', 'into', 'my', 'eyes', "you're", 'under' ] dict_num = {} for item in words: if item not in dict_num.keys(): dict_num[item] = words.count(item) # print(dict_num) most_counter = sorted(dict_num.items(),key=lambda x: x[1],reverse=True)[0] print(most_counter)
sorted函数:
传送门:https://docs.python.org/3.6/l...
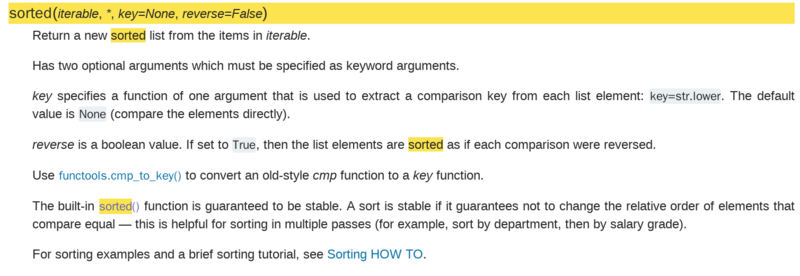
iterable:可迭代类型;
key:用列表元素的某个属性或函数进行作为关键字,有默认值,迭代集合中的一项;
reverse:排序规则. reverse = True 降序 或者 reverse = False 升序,有默认值。
返回值:是一个经过排序的可迭代类型,与iterable一样。
这里,我们使用匿名函数key=lambda x: x[1]
等同于:
def key(x): return x[1]
这里,我们利用每个元素出现的次数进行降序排序,得到的结果的第一项就是出现元素最多的项。
更进一步
这里给出的序列很简单,元素的数目很少,但是有时候,我们的列表中可能存在上百万上千万个元素,那么在这种情况下,不同的解决方案是不是效率就会有很大差别了呢?
为了验证这个问题,我们来生成一个随机数列表,元素个数为一百万个。
这里使用numpy Package,使用前,我们需要安装该包,numpy包下载地址:https://pypi.python.org/pypi/...。这里我们环境是centos7,选择numpy-1.14.2.zip (md5, pgp)进行下载安装,解压后python setup.py install
def generate_data(num=1000000): return np.random.randint(num / 10, size=num)
np.random.randint(low[, high, size]) 返回随机的整数,位于半开区间 [low, high)
具体用法参考https://pypi.python.org/pypi
OK,数据生成了,让我们来测试一下两个方法所消耗的时间,统计时间,我们用time函数就可以。
#!/usr/bin/python # coding=utf-8 # # File: most_elements.py # Author: ralap # Data: 2018-4-5 # Description: find most elements in list # from collections import Counter import operator import numpy as np import random import time def generate_data(num=1000000): return np.random.randint(num / 10, size=num) def collect(test_list): counter_words = Counter(test_list) print(counter_words) most_counter = counter_words.most_common(1) print(most_counter) def list_to_dict(test_list): dict_num = {} for item in test_list: if item not in dict_num.keys(): dict_num[item] = test_list.count(item) most_counter = sorted(dict_num.items(), key=lambda x: x[1], reverse=True)[0] print(most_counter) if __name__ == "__main__": list_value = list(generate_data()) t1 = time.time() collect(list_value) t2 = time.time() print("collect took: %sms" % (t2 - t1)) t1 = t2 list_to_dict(list_value) t2 = time.time() print("list_to_dict took: %sms" % (t2 - t1))
以下结果是我在自己本地电脑运行结果,主要是对比两个方法相对消耗时间。
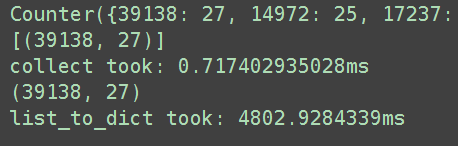
当数据比较大时,消耗时间差异竟然如此之大!下一步会进一步研究Counter的实现方式,看看究竟是什么魔法让他性能如此好。
参考资料
https://blog.csdn.net/xie_0723/article/details/51692806