一、导入示例数据库。
第一篇文章我是在mysql的命令行里导入的数据库。
参考教程 https://www.yiibai.com/mysql/how-to-load-sample-database-into-mysql-database-server.html
二、SQL和MYSQL区别
SQL是结构化查询语言(Structured Query Language)。
MYSQL是一个关系型数据库管理系统。
两者的关系:MYSQL是一种关系数据库,SQL则是操作这种关系数据库的的编程语言。
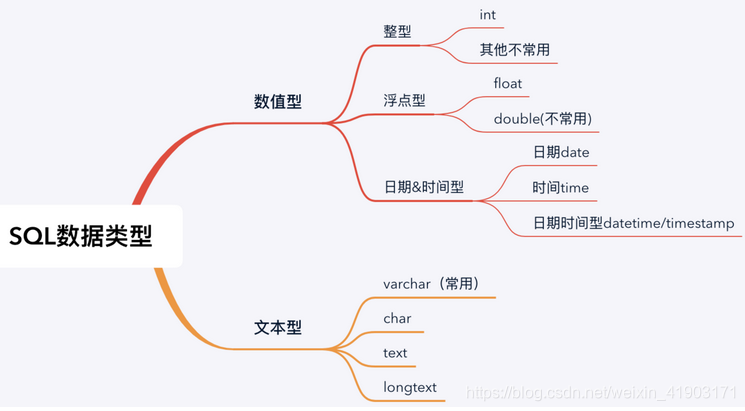
三、SQL数据类型
四、定义命令(DDL)
一 建库
1.create database 数据库名;
2.drop database 数据库名;
命名库名和表名,一般以字母开头,可以包括字母/数字/下划线。
二 建表
1.create table 表名(列名 类型,~~~~~~~~~~~~);
2.drop table 表名;
数据表命名规则:以姓名缩写开头,中间反应表内容,最后以日期结束。
创建表加入约束:
常见的约束:
1)非空约束,not null,针对某个字段设置其值不为空,如学生姓名不为空.
2)唯一约束,unique,它可以使某个字段的值不能重复.
3)主键约束,primary key,主键可以标识记录的唯一性.
三 查库查表
1.show databases;
2.use 库名;
3.show tables;
4.desc 表名;(看字段及类型)
四 增.删.改.更新已有表
Alter table语句用于在已有表中添加,修改或删除列,更新表名,字段类型。
1.增加一列
Alter table 表名 add 列名 新列数据类型;
2.删除一列
Alter table 表名 drop 列名;
3.修改字段名
Alter table 表名 change 旧字段名 新字段名 类型;
4.修改表名
Alter table 旧表名 rename 新表名;
五、操作命令
往往针对行,不是列。
1.insert into 表名(列名)values(各列值);
1.若字符型的,需要用单引号。
2.指定列名时,列的顺序与原表不一致也可,没指定列名时,列的顺序与原表默认一致。
2.dalete from 表名(where列名称=值)
3.upset 表名 set 列名=新值 (where 条件)
不限制where,则更新一列。
upset hy_order_20170410 set order_money=133 where member_id=233;
六、查询命令
1.select 列名 from 表A
1.查询指定要显示的字段。若要查看所有的列,则用*
2.distinct知识点:
为了查询结果不重复;
用在select后;
select distinct member_id from db_order_20170411;
可以对多个字段进行去重(多个字段均相同才会去重);
2.where 查询条件
针对行的各种过滤操作。若过滤的是文本型的,需要单引号。
1.比较:<,>,=,<=,>=,<>
2.指定范围:between and/not between and
3.集合:in,not in
4.空值判断:not null ,null
5.And ,Or
查询条件之模糊查询like
1.%:表示任意长度的字符串,长度可为0。
like 'a%b',表示以a开头,以b结尾任意长度的内容。
2._:一个下划线就表示一个字符。
like 'a_b',以a开头,以b结尾任意长度为3个字符的内容。
例子:查询订单ID中尾号为5的所有订单。
select *from db_order_2017411
where id like ‘%5’;
3.Group by 列名
按指定列名进行分组统计。
对select后面的字段进行汇总。
Group by一定是跟着汇总函数一起使用的。
group by 后面的字段:select后汇总函数前的所有字段都可以作为group by 后面的字段。
汇总函数:
1.sum()
2.min()
3.max()
4.count() 里面可以涉及去重count(distinct l列名) 看到计数,要先去重,再计数。
5.avg()
例子:把订单金额从顾客和订单状态两个维度拆分查询。
select memeber_id
,status
,sum(order_money) as sum_money
from db_order.hy_order_20170411
group by memben_id ,status
order by memben_id;
4.Having 列名
对分组统计后的结果进行过滤。若不是对统计汇总后的结果过滤,我们用的是where。
一定是和group by 一起使用。
例子:统计每个会员累计购买金额,且要求累计购买大于100
select member_id
,sum(order_money) as sum_money
from db_demo.hy_order_20170411
group by member_id
having sum_money >100
order by sum_money desc;
(这个涉及两个逻辑:先统计出来每个会员累计购买金额,再对累计购买金额大于100的过滤。要思考过滤是对统计前还是统计后)
区分:
1.先对会员的订单金额累计汇总后,只取大于100的记录。这个过滤用having.
2.要统计的是订单金额大于100的会员记录,这个用where过滤。
5.order by 列名
对查询结果进行排序(ascending 升序,desc 降序,默认是升序)
6.limit N;
七、SQL函数
一.主要函数类型
时间函数(常用)
文本函数(也叫字符函数)
数学函数
控制函数(常用)
二.时间函数
2.1
DATE_FORMAT() ——函数用于以不同的格式显示日期 / 时间数据。
DATE_FORMAT(date,format)
date 参数是合法的日期或者时间或者日期时间;format 规定日期/时间的输出格式(年月日看需求想要哪个)。
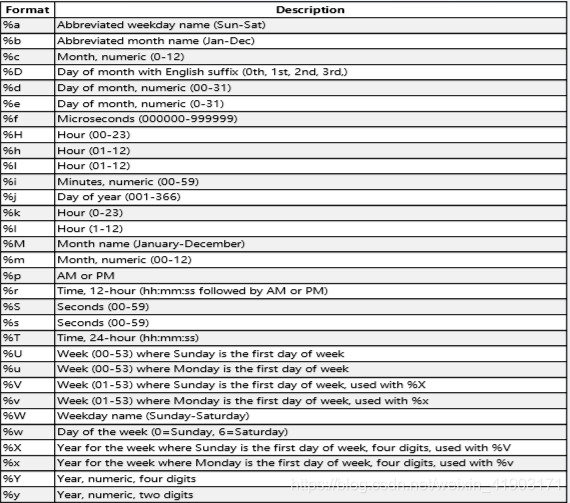
对于一张表中的日期和时间的字段,我们可能有这样的需求,按某个时间参数来统计比如:按年统计,按周统计,按天统计,按每小时统计,都用这个函数。
2.2常用时间函数

2.3常用时间加减函数

要注意:一个日期原本可能是文本型的(在字段的左上小标可以看的出来),要转化成日期时间的format型。
例如:
select create_time
,date_add(create_time,interval,7 day) as day_7
,date_add(create_time,interval,-3 hour) as day_-3
from db_demo.hy_order_20170411;
三.文本函数

concat()拼接函数经常用在百分比。
例如:
select id
,substring(id,2,3) as id_3
from db_order.hy_order_20170411;
例如:
select concat(10.0/30*100,'%');
四.数学函数

例如:
如果订单金额大于等于50就满足了抽奖条件,随机抽取2名作为得奖者,用随机函数构建得奖名单。
select id
,member_id
,order_money
,rand() as flag
from db_demo.hy_order_20170411
where order_money>=50
order by rand() desc;
五.控制函数
控制函数主要两类函数。case when或if
5.1 case when——如果满足某些条件,则进行什么的统计/赋值操作,生成相应的结果;
Case when 条件 then 结果
when 条件 then 结果
when 条件 then 结果
else 结果
end as 列名;
注意:case开始end结束;else不是必须的。
select case when order money <=50 then '低'
when order money>50 and order money<=100 then '中'
when order money >100 then '高'
end as c_type
,sum(order money) as sum_money
,count(distinct member_id) as member_number
from db_demo.hy_order_20170411
where order money is not null
group by case when order money <=50 then '低'
when order money>50 and order money<=100 then '中'
when order money >100 then '高'
end
5.2 if——如果某个条件成立,则选择第二个参数,否则选择第三个参数。
IF(条件,参数1,参数2)
用if的嵌套才能实现上述case when的结果
例如:
select id
,order money
,if(order money >100,if(when order money>50 and order money<=100,‘中’,‘高’),‘低’) as c_type
from db_demo.hy_order_20170411;
- 小实战1:
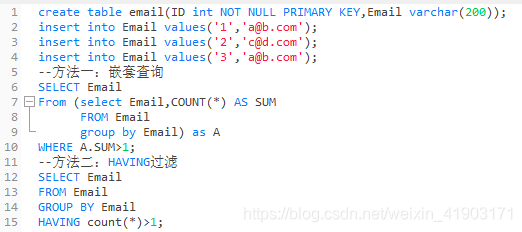
题目:查找重复的电子邮箱(难度:简单)
创建 email表,并插入如下三行数据
±—±--------+
| Id | c |
±—±--------+
| 1 | [email protected] |
| 2 | [email protected] |
| 3 | [email protected] |
±—±--------+
题目要求:编写一个 SQL 查询,查找 Email 表中所有重复的电子邮箱。
根据以上输入,你的查询应返回以下结果:
±--------+
| Email |
±--------+
| [email protected] |
±--------+
说明:所有电子邮箱都是小写字母。
答案:
实现结果:
- 小实战2
题目:查找大国(难度:简单)
创建如下 World 表
±----------------±-----------±-----------±-------------±--------------+
| name | continent | area | population | gdp |
±----------------±-----------±-----------±-------------±--------------+
| Afghanistan | Asia | 652230 | 25500100 | 20343000 |
| Albania | Europe | 28748 | 2831741 | 12960000 |
| Algeria | Africa | 2381741 | 37100000 | 188681000 |
| Andorra | Europe | 468 | 78115 | 3712000 |
| Angola | Africa | 1246700 | 20609294 | 100990000 |
±----------------±-----------±-----------±-------------±--------------+
如果一个国家的面积超过300万平方公里,或者(人口超过2500万并且gdp超过2000万),那么这
题目要求:编写一个SQL查询,输出表中所有大国家的名称、人口和面积。
例如,根据上表,我们应该输出:
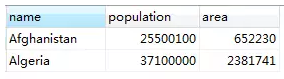
±-------------±------------±-------------+
| name | population | area |
±-------------±------------±-------------+
| Afghanistan | 25500100 | 652230 |
| Algeria | 37100000 | 2381741 |
±-------------±------------±-------------+
答案:
CREATE TABLE World (
name VARCHAR(50) NOT NULL,
continent VARCHAR(50) NOT NULL,
area INT NOT NULL,
population INT NOT NULL,
gdp INT NOT NULL
);
INSERT INTO World
VALUES('Afghanistan','Asia',652230,25500100,20343000);
INSERT INTO World
VALUES('Albania','Europe',28748,2831741,12960000);
INSERT INTO World
VALUES('Algeria','Africa',2381741,37100000,188681000);
INSERT INTO World
VALUES('Andorra','Europe',468,78115,3712000);
INSERT INTO World
VALUES('Angola','Africa',1246700,20609294,100990000);
SELECT
`name`,
population,
area
FROM
World
WHERE
area > 3000000
OR ( population > 25000000 AND gdp > 20000000 );
实现结果:
- 小实战3
题目:超过5名学生的课(难度:简单)
创建如下所示的courses 表 ,有: student (学生) 和 class (课程)。
例如,表:
±--------±-----------+
| student | class |
±--------±-----------+‘’
| A | Math |
| B | English |
| C | Math |
| D | Biology |
| E | Math |
| F | Computer |
| G | Math |
| H | Math |
| I | Math |
| A | Math |
±--------±-----------+
编写一个 SQL 查询,列出所有超过或等于5名学生的课。
应该输出:
±--------+
| class |
±--------+
| Math |
±--------+
Note:
学生在每个课中不应被重复计算。
答案:

结果:
- 小实战4
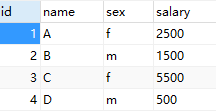
交换工资(难度:简单)
创建一个 salary表,如下所示,有m=男性 和 f=女性的值 。
例如:
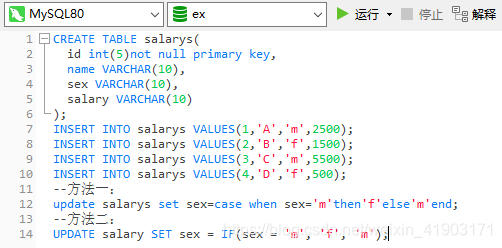
| id | name | sex | salary |
|----|------|-----|--------|
| 1 | A | m | 2500 |
| 2 | B | f | 1500 |
| 3 | C | m | 5500 |
| 4 | D | f | 500 |
交换所有的 f 和 m 值(例如,将所有 f 值更改为 m,反之亦然)。要求使用一个更新查询,并且没有中间临时表。
运行你所编写的查询语句之后,将会得到以下表:
| id | name | sex | salary |
|---|---|---|---|
| 1 | A | f | 2500 |
| 2 | B | m | 1500 |
| 3 | C | f | 5500 |
| 4 | D | m | 500 |
答案:
结果:
- 小实战5
题目:组合两张表 (难度:简单)
在数据库中创建表1和表2,并各插入三行数据(自己造)
表1: Person
±------------±--------+
| 列名 | 类型 |
±------------±--------+
| PersonId | int |
| FirstName | varchar |
| LastName | varchar |
±------------±--------+
PersonId 是上表主键
表2: Address
±------------±--------+
| 列名 | 类型 |
±------------±--------+
| AddressId | int |
| PersonId | int |
| City | varchar |
| State | varchar |
±------------±--------+
AddressId 是上表主键
编写一个 SQL 查询,满足条件:无论 person 是否有地址信息,都需要基于上述两表提供 person 的以下信息:FirstName, LastName, City, State
答案:
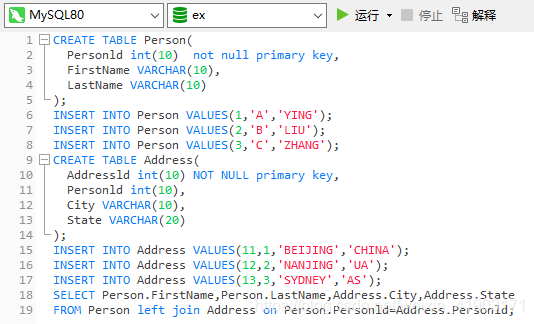
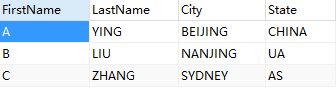
结果:
- 小实战6
题目:删除重复的邮箱(难度:简单)
编写一个 SQL 查询,来删除 email 表中所有重复的电子邮箱,重复的邮箱里只保留 Id 最小 的那个。
±—±--------+
| Id | Email |
±—±--------+
| 1 | [email protected] |
| 2 | [email protected] |
| 3 | [email protected] |
±—±--------+
Id 是这个表的主键。
例如,在运行你的查询语句之后,上面的 Person表应返回以下几行:
±—±-----------------+
| Id | Email |
±—±-----------------+
| 1 | [email protected] |
| 2 | [email protected] |
±—±-----------------+
答案:
逻辑:分组取最小值。
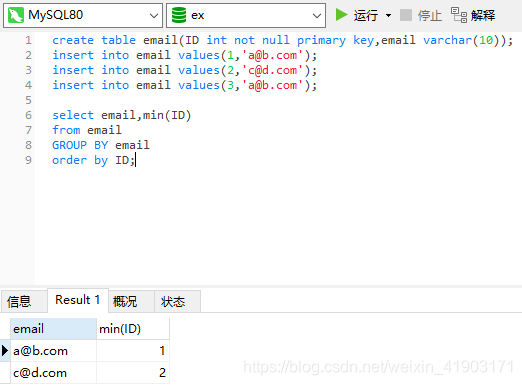
- 小实战7
题目:各部门工资最高的员工(难度:中等)
创建Employee 表,包含所有员工信息,每个员工有其对应的 Id, salary 和 department Id。
±—±------±-------±-------------+
| Id | Name | Salary | DepartmentId |
±—±------±-------±-------------+
| 1 | Joe | 70000 | 1 |
| 2 | Henry | 80000 | 2 |
| 3 | Sam | 60000 | 2 |
| 4 | Max | 90000 | 1 |
±—±------±-------±-------------+
创建Department 表,包含公司所有部门的信息。
±—±---------+
| Id | Name |
±—±---------+
| 1 | IT |
| 2 | Sales |
±—±---------+
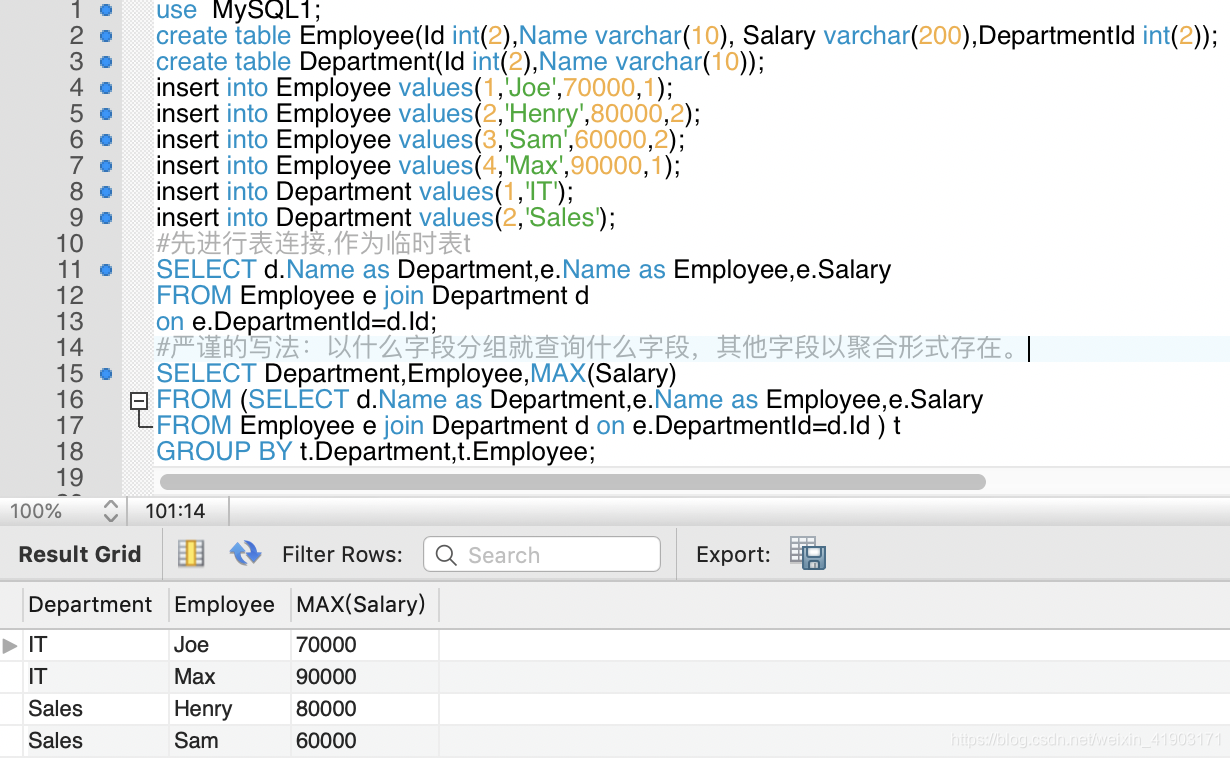
编写一个 SQL 查询,找出每个部门工资最高的员工。例如,根据上述给定的表格,Max 在 IT 部门有最高工资,Henry 在 Sales 部门有最高工资。
±-----------±---------±-------+
| Department | Employee | Salary |
±-----------±---------±-------+
| IT | Max | 90000 |
| Sales | Henry | 80000 |
±-----------±---------±-------+
答案+结果:
- 小实战8
题目:换座位(难度:中等)
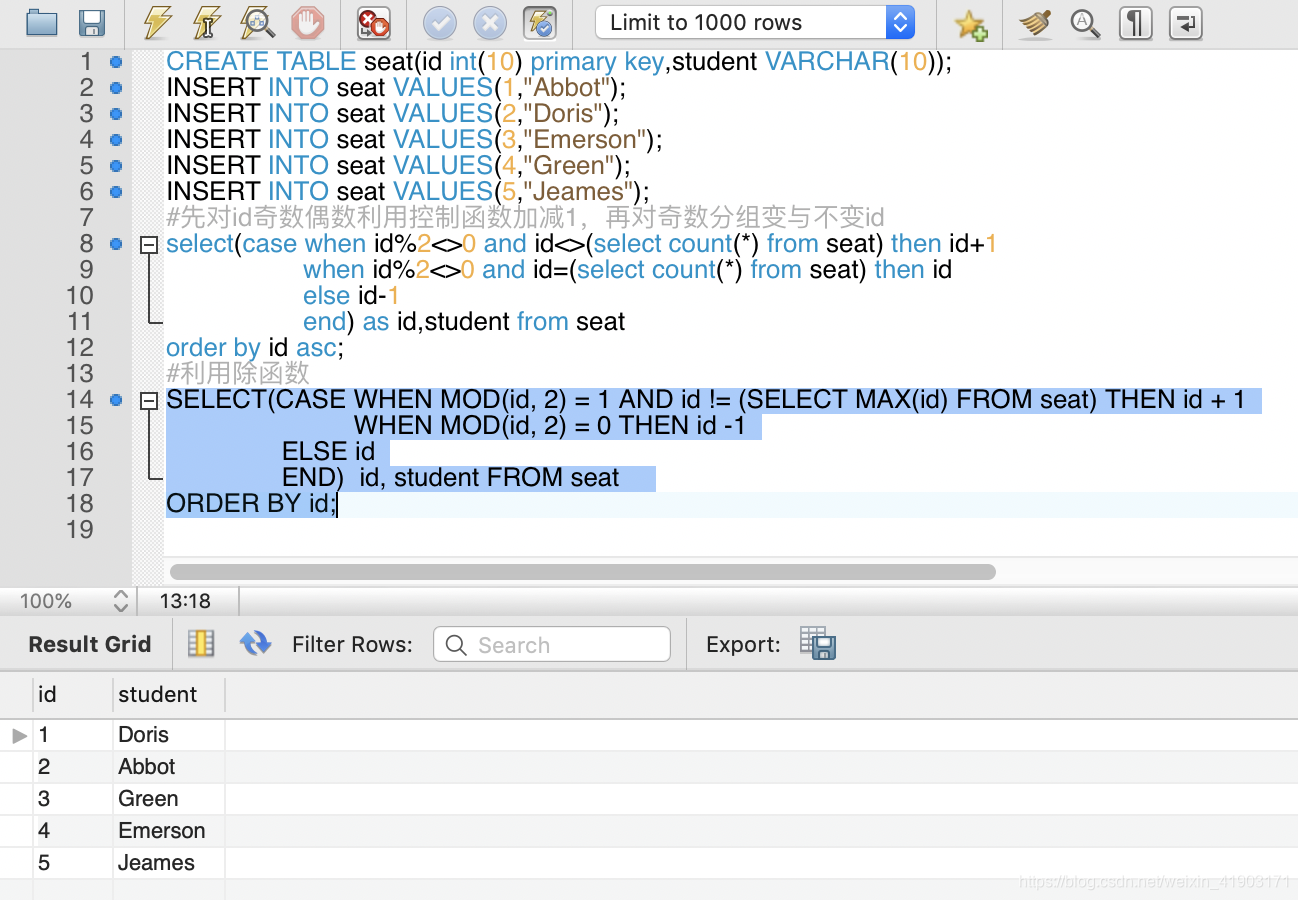
小美是一所中学的信息科技老师,她有一张 seat 座位表,平时用来储存学生名字和与他们相对应的座位 id。
其中纵列的 id 是连续递增的
小美想改变相邻俩学生的座位。
你能不能帮她写一个 SQL query 来输出小美想要的结果呢?
请创建如下所示seat表:
示例:
±--------±--------+
| id | student |
±--------±--------+
| 1 | Abbot |
| 2 | Doris |
| 3 | Emerson |
| 4 | Green |
| 5 | Jeames |
±--------±--------+
假如数据输入的是上表,则输出结果如下:
±--------±--------+
| id | student |
±--------±--------+8
| 1 | Doris |
| 2 | Abbot |
| 3 | Green |
| 4 | Emerson |
| 5 | Jeames |
±--------±--------+
注意:
如果学生人数是奇数,则不需要改变最后一个同学的座位。
答案+结果:
- 小实战9
题目:分数排名(难度:中等)
编写一个 SQL 查询来实现分数排名。如果两个分数相同,则两个分数排名(Rank)相同。请注意,平分后的下一个名次应该是下一个连续的整数值。换句话说,名次之间不应该有“间隔”。
创建以下score表:
±—±------+
| Id | Score |
±—±------+
| 1 | 3.50 |
| 2 | 3.65 |
| 3 | 4.00 |
| 4 | 3.85 |
| 5 | 4.00 |
| 6 | 3.65 |
±—±------+
例如,根据上述给定的 Scores 表,你的查询应该返回(按分数从高到低排列):
±------±-----+
| Score | Rank |
±------±-----+
| 4.00 | 1 |
| 4.00 | 1 |
| 3.85 | 2 |
| 3.65 | 3 |
| 3.65 | 3 |
| 3.50 | 4 |
±------±-----+
答案:
方法一:
MySQL变量法
mysql中变量不用事前申明,在用的时候直接用“@变量名”使用就可以了。
第一种用法 set @num=999; 或set @num:=888; //这里要使用变量来保存数据,直接使用@num变量
第二种用法 select @num:=1; 或 select @num:=字段名 from 表名 where ……
注意上面两种赋值符号,使用set时可以用“=”或“:=”,但是使用select时必须用“:=赋值”,单个=会被解析为where后面的字段值比较
SELECT
Score,
@rank := @rank + (@prev <> (@prev := Score)) Rank
FROM
score,
(SELECT @rank := 0, @prev := -1) init
ORDER BY Score DESC;
解释:(利用变量来实现排名)
1.使用了@rank,@prev两个变量,一个表示排名,一个表示前一名的score分数
2.@rank := 0, @prev := -1 #对变量进行初始化
3.表达式@prev <> (@prev := Score)的取值轨迹为1,0,1,1,0,1,表示当前分数与前一分数进行比较,如果相同则为0,不同则为1
4.@rank := @rank +(@prev <> (@prev := Score)) 这条命令相当于 循环下的sum +=num;类似的原理。
SELECT
Score,
(@prev <> (@prev := Score)) Rank
FROM
Scores,
(SELECT @rank := 0, @prev := -1) init
ORDER BY Score desc
Score Rank
4.00 1
4.00 0
3.85 1
3.65 1
3.65 0
3.50 1
- 小实战10——复杂项目
题目:行程和用户(难度:困难)
Trips 表中存所有出租车的行程信息。每段行程有唯一键 Id,Client_Id 和 Driver_Id 是 Users 表中 Users_Id 的外键。Status 是枚举类型,枚举成员为 (‘completed’, ‘cancelled_by_driver’, ‘cancelled_by_client’)。
±—±----------±----------±--------±-------------------±---------+
| Id | Client_Id | Driver_Id | City_Id | Status |Request_at|
±—±----------±----------±--------±-------------------±---------+
| 1 | 1 | 10 | 1 | completed |2013-10-01|
| 2 | 2 | 11 | 1 | cancelled_by_driver|2013-10-01|
| 3 | 3 | 12 | 6 | completed |2013-10-01|
| 4 | 4 | 13 | 6 | cancelled_by_client|2013-10-01|
| 5 | 1 | 10 | 1 | completed |2013-10-02|
| 6 | 2 | 11 | 6 | completed |2013-10-02|
| 7 | 3 | 12 | 6 | completed |2013-10-02|
| 8 | 2 | 12 | 12 | completed |2013-10-03|
| 9 | 3 | 10 | 12 | completed |2013-10-03|
| 10 | 4 | 13 | 12 | cancelled_by_driver|2013-10-03|
±—±----------±----------±--------±-------------------±---------+
Users 表存所有用户。每个用户有唯一键 Users_Id。Banned 表示这个用户是否被禁止,Role 则是一个表示(‘client’, ‘driver’, ‘partner’)的枚举类型。
±---------±-------±-------+
| Users_Id | Banned | Role |
±---------±-------±-------+
| 1 | No | client |
| 2 | Yes | client |
| 3 | No | client |
| 4 | No | client |
| 10 | No | driver |
| 11 | No | driver |
| 12 | No | driver |
| 13 | No | driver |
±---------±-------±-------+
写一段 SQL 语句查出 2013年10月1日 至 2013年10月3日 期间非禁止用户的取消率。基于上表,你的 SQL 语句应返回如下结果,取消率(Cancellation Rate)保留两位小数。
±-----------±------------------+
| Day | Cancellation Rate |
±-----------±------------------+
| 2013-10-01 | 0.33 |
| 2013-10-02 | 0.00 |
| 2013-10-03 | 0.50 |
±-----------±------------------+
答案:
-- 创建Trips表
CREATE TABLE Trips(
id INT PRIMARY KEY,
Client_id INT,
Driver_id INT,
City_id INT,
Status ENUM('completed','cancelled_by_driver','cancelled_by_client'),
Request_at VARCHAR(50)
);
-- 插入数据
INSERT INTO Trips VALUES ('1', '1', '10', '1', 'completed', '2013-10-01');
INSERT INTO Trips VALUES ('2', '2', '11', '1', 'cancelled_by_driver', '2013-10-01');
INSERT INTO Trips VALUES ('3', '3', '12', '6', 'completed', '2013-10-01');
INSERT INTO Trips VALUES ('4', '4', '13', '6', 'cancelled_by_client', '2013-10-01');
INSERT INTO Trips VALUES ('5', '1', '10', '1', 'completed', '2013-10-02');
INSERT INTO Trips VALUES ('6', '2', '11', '6', 'completed', '2013-10-02');
INSERT INTO Trips VALUES ('7', '3', '12', '6', 'completed', '2013-10-02');
INSERT INTO Trips VALUES ('8', '2', '12', '12', 'completed', '2013-10-03');
INSERT INTO Trips VALUES ('9', '3', '10', '12', 'completed', '2013-10-03');
INSERT INTO Trips VALUES ('10', '4', '13', '12', 'cancelled_by_driver', '2013-10-03');
-- 查看Trips表
SELECT * FROM Trips;
-- 创建Users表
CREATE TABLE Users(
Users_id INT PRIMARY KEY,
Banned varchar(20),
Role ENUM('client','driver','partner')
);
-- 插入数据
INSERT INTO Users VALUES ('1', 'No', 'client');
INSERT INTO Users VALUES ('2', 'Yes', 'client');
INSERT INTO Users VALUES ('3', 'No', 'client');
INSERT INTO Users VALUES ('4', 'No', 'client');
INSERT INTO Users VALUES ('10', 'No', 'driver');
INSERT INTO Users VALUES ('11', 'No', 'driver');
INSERT INTO Users VALUES ('12', 'No', 'driver');
INSERT INTO Users VALUES ('13', 'No', 'driver');
-- 查看Users表
SELECT * FROM users;
-- 实现代码
SELECT t.Request_at AS Day,
ROUND(sum((CASE WHEN t.Status LIKE 'cancelled%' THEN 1 ELSE 0 END))/count(*),2) AS 'Cancellation Rate' -- 如果是取消的就为1,否则为0,sum求和后除以当天的总单数,即为取消率。Round函数用来保留两位小数。
FROM Trips t
INNER JOIN Users u ON u.Users_Id =t.Client_Id AND u.Banned = 'No' -- 连接两张表
GROUP BY t.Request_at; -- 以订单时间分组
- 小实战11
题目:各部门前3高工资的员工(难度:中等)
将项目7中的employee表清空,重新插入以下数据(其实是多插入5,6两行):
±—±------±-------±-------------+
| Id | Name | Salary | DepartmentId |
±—±------±-------±-------------+
| 1 | Joe | 70000 | 1 |
| 2 | Henry | 80000 | 2 |
| 3 | Sam | 60000 | 2 |
| 4 | Max | 90000 | 1 |
| 5 | Janet | 69000 | 1 |
| 6 | Randy | 85000 | 1 |
±—±------±-------±-------------+
编写一个 SQL 查询,找出每个部门工资前三高的员工。例如,根据上述给定的表格,查询结果应返回:
±-----------±---------±-------+
| Department | Employee | Salary |
±-----------±---------±-------+
| IT | Max | 90000 |
| IT | Randy | 85000 |
| IT | Joe | 70000 |
| Sales | Henry | 80000 |
| Sales | Sam | 60000 |
±-----------±---------±-------+
此外,请考虑实现各部门前N高工资的员工功能。
CREATE TABLE IF NOT EXISTS Employee(
Id SMALLINT PRIMARY KEY AUTO_INCREMENT,
Name VARCHAR(20) NOT NULL,
Salary INT NOT NULL,
DepartmentId TINYINT NOT NULL
);
CREATE TABLE IF NOT EXISTS Department(
Id SMALLINT PRIMARY KEY AUTO_INCREMENT,
Name VARCHAR(20) NOT NULL
);
INSERT Employee(Name,Salary,DepartmentId)
Values('Joe',70000,1),
('Henry',80000,2),
('Sam',60000,2),
('Max',90000,1);
INSERT Department(Name)
Values('IT'),
('Sales');
SELECT d.Name as Department,e.Name as Employee,e.Salary
FROM Employee e,Department d
WHERE e.DepartmentId = d.Id
and e.Salary = (SELECT MAX(Employee.Salary)
FROM Employee
WHERE Employee.DepartmentId = d.Id);
- 小实战12
题目:分数排名 - (难度:中等)
依然是昨天的分数表,实现排名功能,但是排名是非连续的,如下:
±------±-----+
| Score | Rank |
±------±-----+
| 4.00 | 1 |
| 4.00 | 1 |
| 3.85 | 3 |
| 3.65 | 4 |
| 3.65 | 4 |
| 3.50 | 6 |
±------±-----
SELECT
Score,
@rank := @rank + (@prev <> (s.Score)) * @count Rank,
(CASE
WHEN (@prev <> (@prev := Score)) THEN @count := 1
ELSE @count := @count + 1 END) Count
FROM
score s,
(SELECT @rank := 0, @prev := -1, @count := 1) init
ORDER BY Score DESC;