查询功能是SQL语句最重要的功能,查询操作也是数据库系统最常用的操作。学习SQL查询语句,首先要弄清楚的是查询语句用到的关键字以及查询语句的执行顺序。SQL语言的一个特点在于,它是一种声明式语句,执行顺序并不按照语法顺序执行,所以不了解SQL执行顺序的话会在进行比较复杂的查询时很容易产生错误,在嵌套子查询时很容易发生别名错误、查询表错误的问题。
SQL的常用函数:
- AVG(可计算属性):求某个可计算属性的平均数
- SUM(可计算属性):求某个可计算属性的总和
- COUNT(属性):求某个属性在中间表中出现的次数
- MAX(可计算属性):求某个可计算属性的最大值
- MIN(可计算属性):求某个可计算属性的最小值
- ......
SQL查询语言可以使用的内置函数非常多,而且不同的数据库支持的函数有微小的差别,具体还要在实践中学习,只要知道SQL语言提供了丰富强大的可用函数即可,而且函数经常和GROUP BY分组配合使用以达成查找目的。
查询语句的语法顺序:
- SELECT [DISTINCT]:用于从表中选取需要的数据,返回的结果为一个结果集(是一个查询表),DISTINCT可选关键字表示不显示重复元组
- FROM:用于指定表查询SELECT的目标,与SELECT连用,表示从什么地方进行数据选取
- WHERE:用于规定表查询的条件,条件语句
- GROUP BY:用于进行分组查询,按指定的属性的值进行分组,之后的SELECT、HAVING子句也按分组后进行处理
- HAVING:用于对分组后的表查询进行过滤,对SELECT结果进行一次过滤再输出,只出现在GROUP BY后面
- UNION [ALL]:用于对两个结果集进行交运算,ALL可选关键字表示保留合并后的重复内容
- ORDER BY:用于对查询结果进行排序
查询语句的执行顺序:
- FROM
- WHERE
- GROUP BY
- HAVING
- SELECT [DISTINCT]
- UNION [ALL]
- ORDER BY
可见SQL语句的执行顺序和语法顺序是不同的,执行一条SQL查询语句的顺序应该是:
- 通过FROM子句将数据从硬盘加载到内存中,或者将内存中的表提取出来。先把数据的来源取出才能进行后续查询
- 通过WHERE子句对FROM得到的表进行初步筛选
- GROUP BY语句将初步筛选得到的表进行分组(所以同一层的WHERE子句是无法对分组后的内容进行筛选的)
- HAVING语句对分组后的数据进行过滤,即进行了进一步的筛选(WHERE筛选分组前的数据,HAVING筛选分组后的数据)
- SELECT子句从上面步骤产生的临时表中选取目的数据生成查询表
- UNION子句将多个SELECT查询结果进行集合交运算
- ORDER BY对查询结果按照某个属性进行排序
其中SQL查询语句有几点是要注意的:①执行语句首先执行的是FROM子句,SELECT子句是在查找基本完成时用于产生结果集的;②GROUP BY子句是一个值得注意的关键字SQL查询经常需要对数据进行分组计算操作,要注意区分哪里是分组后,哪里是分组前;③并非所有的SQL都按照以上顺序执行但是大同小异,SELECT语句会在主要的筛选操作完成之后才会执行。
查找示例:
##SQL_Server
SELECT [Customer],SUM([OrderPrice]) FROM [Orders] WHERE [Customer]='Bush' OR [Customer]='Adams' GROUP BY [Customer] HAVING SUM([OrderPrice])>1500
示例解析:
- 从项目表(Orders)中查找Bush、Adams两位客户(Customer)的项目总金额(SUM(OrderPrice))是否超过1500元,并显示满足要求的客户的名称和项目总金额
- 执行FROM语句:将Order表导入到内存
- 执行WHERE语句:筛选Order表中的Customer属性 ,将Customer的值为'Bush'、'Adams'的元组筛选出来
- 执行GROUP BY语句:将WHERE筛选结果按Customer的值进行分组,分为'Bush'、'Adams'两组
- 执行HAVING语句:分组结果分别求每一组的OrderPrice的和,选取SUM(OrderPrice)的值大于1500的元组
- 执行SELECT语句:在上面步骤得到的中间表选择其中的Customer、SUM(OrderPrice)两个属性组成一个结果表并显示出来
所谓“实践出真知”,接下来通过练习学习SQL查询语句的设计方法:
(博主使用的是MySql+HeidiSQL进行实验)
构建一个Lebery数据库,代码如下:


#MySQL CREATE DATABASE Labery USE Labery #MySQL CREATE TABLE `book` ( `bno` CHAR(8) NOT NULL, `category` VARCHAR(10) NULL DEFAULT NULL, `title` VARCHAR(40) NOT NULL, `press` VARCHAR(30) NOT NULL, `book_year` INT(11) NOT NULL, `author` VARCHAR(20) NULL DEFAULT NULL, `price` DECIMAL(7,2) NOT NULL, `book_title` INT(11) NOT NULL, PRIMARY KEY (`bno`)) CREATE TABLE `card` ( `cno` CHAR(7) NOT NULL, `cname` CHAR(8) NOT NULL, `department` VARCHAR(40) NULL DEFAULT NULL, `type` CHAR(1) NOT NULL, PRIMARY KEY (`cno`)) CREATE TABLE `borrow` ( `cno` CHAR(7) NOT NULL, `bno` CHAR(8) NOT NULL, `borrow_date` TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP, `return_date` TIMESTAMP NULL DEFAULT NULL, PRIMARY KEY (`cno`, `bno`, `borrow_date`), INDEX `bno` (`bno`), CONSTRAINT `borrow_ibfk_1` FOREIGN KEY (`cno`) REFERENCES `card` (`cno`), CONSTRAINT `borrow_ibfk_2` FOREIGN KEY (`bno`) REFERENCES `book` (`bno`))
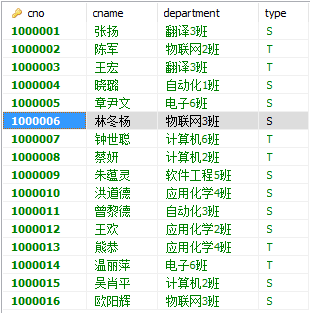
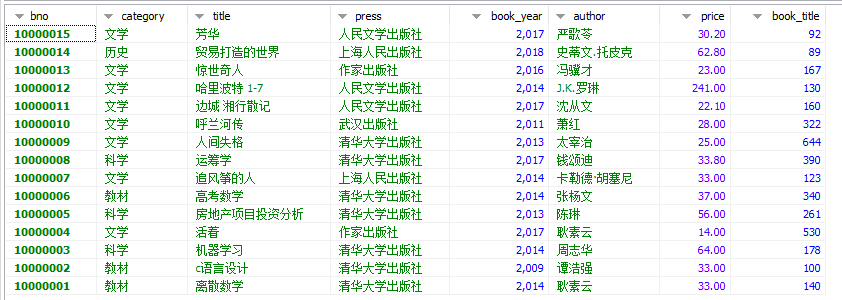
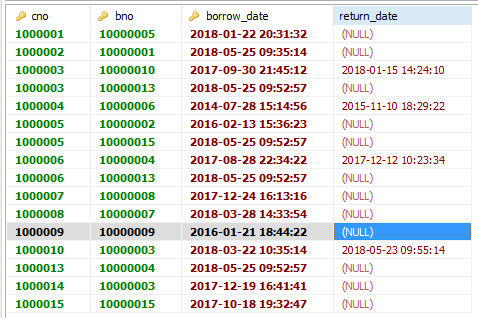
(Labery数据库中有三个表借书证表(Card)、图书表(Book)、借阅表(Borrow))
为构建的表添加数据:
#Book表 INSERT INTO Book VALUES(10000001,'教材','离散数学','清华大学出版社',2014,'耿素云',33,140) INSERT INTO BooK VALUES(10000002,'教材','c语言设计','清华大学出版社',2009,'谭浩强',33,100) INSERT INTO BooK VALUES(10000003,'科学','机器学习','清华大学出版社',2014,'周志华',64,178) INSERT INTO BooK VALUES(10000004,'文学','活着','作家出版社',2017,'耿素云',14,530) INSERT INTO BooK VALUES(10000005,'科学','房地产项目投资分析','清华大学出版社',2013,'陈琳',56,261) INSERT INTO BooK VALUES(10000006,'教材','高考数学','清华大学出版社',2014,'张杨文',37,340) INSERT INTO BooK VALUES(10000007,'文学','追风筝的人','上海人民出版社',2014,'卡勒德·胡塞尼',33,123) INSERT INTO BooK VALUES(10000008,'科学','运筹学','清华大学出版社',2017,'钱颂迪',33.8,390) INSERT INTO BooK VALUES(10000009,'文学','人间失格','清华大学出版社',2013,'太宰治',25.0,644) INSERT INTO BooK VALUES(10000010,'文学','呼兰河传','武汉出版社',2011,'萧红',28,322) INSERT INTO BooK VALUES(10000011,'文学','边城 湘行散记','人民文学出版社',2017,'沈从文',22.1,160); INSERT INTO BooK VALUES(10000012,'文学','哈里波特 1-7','人民文学出版社',2014,'J.K.罗琳',241,130); INSERT INTO BooK VALUES(10000013,'文学','惊世奇人','作家出版社',2016,'冯骥才',23,167); INSERT INTO BooK VALUES(10000014,'历史','贸易打造的世界','上海人民出版社',2018,'史蒂文.托皮克',62.8,89); INSERT INTO BooK VALUES(10000015,'文学','芳华','人民文学出版社',2017,'严歌苓',30.2,92); #Card表 INSERT INTO Card VALUES(1000001,'张扬','翻译3班','S'); INSERT INTO Card VALUES(1000002,'陈军','物联网2班','T'); INSERT INTO Card VALUES(1000003,'王宏','翻译3班','T'); INSERT INTO Card VALUES(1000004,'晓璐','自动化1班','S'); INSERT INTO Card VALUES(1000005,'章尹文','电子6班','S'); INSERT INTO Card VALUES(1000007,'钟世聪','计算机6班','T'); INSERT INTO Card VALUES(1000008,'蔡妍','计算机2班','T'); INSERT INTO Card VALUES(1000009,'朱蕴灵','软件工程5班','S'); INSERT INTO Card VALUES(1000010,'洪道德','应用化学4班','S'); INSERT INTO Card VALUES(1000011,'曾黎德','自动化3班','S'); INSERT INTO Card VALUES(1000012,'王欢','应用化学2班','S'); INSERT INTO Card VALUES(1000013,'熊恭','应用化学4班','T'); INSERT INTO Card VALUES(1000014,'温丽萍','电子6班','T'); INSERT INTO Card VALUES(1000015,'吴肖平','计算机2班','S'); INSERT INTO Card VALUES(1000016,'欧阳辉','物联网3班','S'); #Borrow表 INSERT INTO Borrow VALUES(1000006,10000004,'2017.8.28 22:34:22','2017.12.12 10:23:34'); INSERT INTO Borrow(cno,bno,borrow_date) VALUES(1000001,10000005,'2018.1.22 20:31:32'); INSERT INTO Borrow(cno,bno,borrow_date) VALUES(1000005,10000002,'2016.2.13 15:36:23'); INSERT INTO Borrow VALUES(1000004,10000006,'2014.7.28 15:14:56','2015.11.10 18:29:22'); INSERT INTO Borrow VALUES(1000010,10000003,'2018.3.22 10:35:14','2018.5.23 9:55:14'); INSERT INTO Borrow(cno,bno) VALUES(1000002,10000001); INSERT INTO Borrow(cno,bno,borrow_date) VALUES(1000009,10000009,'2016.1.21 18:44:22'); INSERT INTO Borrow VALUES(1000003,10000010,'2017.9.30 21:45:12','2018.1.15 14:24:10'); INSERT INTO Borrow(cno,bno,borrow_date) VALUES(1000007,10000008,'2017.12.24 16:13:16'); INSERT INTO Borrow(cno,bno,borrow_date) VALUES(1000008,10000007,'2018.3.28 14:33:54'); INSERT INTO Borrow(cno,bno,borrow_date) VALUES(1000014,10000003,'2017.12.19 16:41:41'); INSERT INTO Borrow(cno,bno) VALUES(1000013,10000004); INSERT INTO Borrow(cno,bno) VALUES(1000006,10000013); INSERT INTO Borrow(cno,bno,borrow_date) VALUES(1000015,10000015,'2017.10.18 19:32:47'); INSERT INTO Borrow(cno,bno) VALUES(1000003,10000013); INSERT INTO Borrow(cno,bno) VALUES(1000005,10000015);
获得的表如图所示:(分别为Card、Book、Borrow三张表)
查询练习:
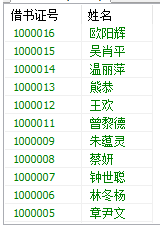
1、查询借过书并且尚未归还的学生的借书证号、借阅者姓名,并按借书证号降序排列。
SELECT `Card`.cno `借书证号`,cname `姓名` FROM `Card` LEFT JOIN `Borrow` ON `Card`.cno = `Borrow`.cno WHERE `return_date` IS NULL ORDER BY `借书证号` DESC 首先从Card、Borrow两个表中提取数据并进行cno相等的左连接,得到的结果 再筛选归还时间为NULL的记录,最后选取cno(设置别名为借书证号)和cname (设置别名为姓名)生成结果表,显示结果通过ORDER BY...ON...语句设置 为以借书证号倒序排列
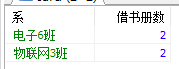
2、查询哪个系的同学借书数量最多
SELECT department 系,COUNT(department) 借书册数 FROM `Card` JOIN `Borrow` ON `Card`.cno = `Borrow`.cno WHERE `type` = 'S' GROUP BY `department` HAVING COUNT(department) >= ALL(SELECT COUNT(department) FROM `Card` JOIN `Borrow` ON `Card`.cno = `Borrow`.cno WHERE `type` = 'S' GROUP BY `department`) 思路: 首先通过 SELECT COUNT(department) FROM `Card` JOIN `Borrow` ON `Card`.cno = `Borrow`.cno WHERE `type` = 'S' GROUP BY `department` 获得每个系的学生借书总量 然后用各个系的学生的借书总量和所有系的借书总量分别比较,可以找到那个系借书最多。
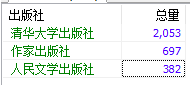
3、查询藏书中那些出版社的书籍超过350本
SELECT `press_totle`.出版社,`press_totle`.总量 FROM (SELECT `press` `出版社`,SUM(`book_totle`) 总量 FROM `Book` GROUP BY `press`) AS `press_totle` WHERE 总量 >= 350 思路: 首先获得每个出版社的藏书总量 SELECT `press` `出版社`,SUM(`book_totle`) 总量 FROM `Book` GROUP BY `press` 获得一个中间表命名为press_totle,然后使用这个中间表作建立查询,筛选总量在350以上的出版社。
以上三道题目对初学者来讲都是很好的练习题,主要通过题目来分析SQL语言的执行顺序,中间表的生成位置与能够调用中间表的位置都和SQL的执行有关。在SELECT子查询中出现的中间表不能在FROM中使用,因为FROM是先于SELECT执行的。
SQL查询语言和编程语言的设计思路有很大不同,首先是因为SQL查询语言的运行顺序和语法顺序不同,其次是应为SQL查询语言在设计思路和语法逻辑上更贴近自然语言,初学者如果抛弃程序语言的思路来学习SQL,才能事半功倍。但是也正因为SQL查询语言贴合自然语言思路的特点,数据库的查询语句才那么简单易用。