目录
最新版本
hibernate5.x以上
写hql语句,在?号的后面需要加上数字,0代表第1个参数,1代表第2个参数

前言
本篇讲解hibernate基础知识,不会涉及到hibernate的应用,应用在另一篇里
hibernate概念和知识点总结 https://www.cnblogs.com/Java-web-wy/p/6533672.html
Hibernate框架
Hibernate是持久层的框架,它对JDBC做了轻量级的封装,而我们java程序员可以使用面向对象的思想来操纵数据库
从而到达不需要写sql语句的目的,当前目前来说,Hibernate已经快被淘汰了,写sql语句是主流
使用的时候必须导入jdbc的驱动包

hibernate的目录结构


日志包

hibernate配置
使用hibernate操作数据库,对应的Bean必须要有映射文件
表的结构

对应Bean类里的字段也要相同(最好是相同的),会方便很多

Bean的xml配置文件
因为不需要我们自己写sql语句,所以需要对应的配置
引入xml约束



配置文件内容
类的属性和表的字段名相同,不需要写column
需要注意的id需要另外处理,一般我们会叫它主键
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE hibernate-mapping PUBLIC
"-//Hibernate/Hibernate Mapping DTD 3.0//EN"
"http://www.hibernate.org/dtd/hibernate-mapping-3.0.dtd">
<hibernate-mapping>
<!-- 建立类与表的映射,name是类名,table是数据库表名 -->
<class name="com.bean.Customer" table="Customer">
<!-- 建立类中的属性与表中主键对应,主键比较特殊需要单独处理 -->
<id name="cust_id" column="cust_id">
<!-- generator是策略的意思,native表示本地策略 -->
<!-- 如果主键是String类型的,那么应该用uuid -->
<generator class="native"></generator>
</id>
<!-- 建立类中普通属性和表字段的对应关系 -->
<!-- 如果类中属性名和表字段名称相同,那么不需要写column -->
<property name="cust_name" column="cust_name"></property>
<property name="cust_phone"></property>
</class>
</hibernate-mapping> 可以指定数据库,不过一般会在核心配置文件里配置

主键的生成策略
自然主键(上面我们使用的是自然主键)
主键本身就是表中的一个字段,比如id,是bean类里的一个具体的属性
比如身份证号,每个人的身份证id,使用了身份证id作为主键,其他属性是名字,地址,在bean类里,是需要写id属性的
代理主键(在开发中尽量使用此主键)
主键本身并不在表中,在bean类里是不需要写的
就好比excle表格中,最前面有编号,是表示第几行的,但是还有一个编号,是人员编号,二者并不相干
在generator的class里有如下几个选择
increment : hibernate中提供的自动增长机制,适用于short,int,long类型主键,在单线程中使用
会发送一点语句 selec max(id) from 然后让id+1,作为下一条数据的主键,支持mysql和oracle
identity : ,适用于short,int,long类型主键,使用的是数据库本身的增长机制,适用所有自动增长型数据库,
如mysql,sqlserver,但是oracle并没有自动增长机制
sequence : 适用于short,int,long类型主键,采用的是序列的方法,oracle支持序列,但是mysql不支持
uuid :适用于字符串类型主键,使用的是hibernate随机方式生成字符串主键
native : 本地策略,可以在identity和sequence之间自动切换,如果是mysql,那就是identity,如果是oracle
那就是sequence
hibernate核心配置文件
上面只是配置bean的配置文件,hibernate还有核心配置文件,用于配置hibernate自身
以及数据库的一些连接参数,在src路径下创建
hibernate核心配置约束文件
就是bean配置文件的上面一点

核心配置内容
hibernate自带了实例

在hibernate.properti里

在hibernate.cfg.xml里

localhsot:3306/test 这个test数据库名
<hibernate-configuration>
<session-factory>
<!-- 数据库的基本参数 -->
<property name="hibernate.connection.driver_class">com.mysql.jdbc.Driver</property>
<property name="hibernate.connection.url">jdbc:mysql://localhost:3306/test</property>
<property name="hibernate.connection.username">root</property>
<property name="hibernate.connection.password">root</property>
<!-- 配置方言,指定hibernate生成哪种sql语句,因为各种数据库的sql语句不一样 -->
<property name="hibernate.dialect">org.hibernate.dialect.MySQLDialect</property>
<!-- 可选配置 -->
<!-- 打印sql -->
<property name="hibernate.show_sql">true</property>
<!-- 格式化sql,这样我们看控制台的时候就更容易理解 -->
<property name="hibernate.format_sql">true</property>
<!-- 配置bean的映射路径 -->
<mapping resource="com/bean/Customer.hbm.xml"></mapping>
</session-factory>
</hibernate-configuration>核心配置文件的其它内容

自动创建表
如果使用自动创建表,那么上面的那些配置里,就必须把属性写全,type,length这些都需要指定


了解java利用hibernate的流程
浅显的了解一下,业务代码并没有写
@Test
public void demo1()
{
//加载hibernate核心配置文件,默认是加载src目录下
Configuration configuration=new Configuration().configure();
//创建sessionFactory工厂,类是JDBC连接池的那种工厂
SessionFactory sessionFactory=configuration.buildSessionFactory();
//获取到session事务对象
Session session=sessionFactory.openSession();
//手动开启事务,增,删,改才需要事务
Transaction transaction=session.beginTransaction();
//编写业务代码,后面会讲
//事务提交
transaction.commit();
//资源释放
session.close();
}hibernate的连接池配置
hibernate是一个持久层的框架,自然需要用到数据库连接池
在hibernate里有一个SessionFactory(事务工厂),SessionFactory在里面维护了连接池
一般来说,一个项目里SessionFactory只需要一个,负责创建session对象
写一个工具类来确保一个项目里只有一个SessionFactory
需要注意的是,这里的session对象并不是线程安全的,就是说并不是单例对象,所以写在工具类的内部
不然资源共享的时候会触发线程session的安全问题
public class hibernateUtils
{
public static final Configuration cfg;
public static final SessionFactory sf;
static
{
cfg=new Configuration().configure();
sf=cfg.buildSessionFactory();
}
public static Session openSession()
{
return sf.openSession();
}
}但是SessionFactory只是维护了连接池,它自己并不是连接池,所以需要用到第三方连接池,这里使用c3p0做例子
导入c3p0的jar包以及依赖包,在hibernate目录下的lib/option(可选)里文件里有
并且在hibernate的核心配置文件里加入c3p0连接池的配置
下面这些内容在hibernate的\project\hibernate-c3p0\src\test\resources 有参考,但是没有讲具体作用
<!-- 配置C3P0连接池 -->
<!-- 从c3p0连接词中获取数据库连接,因为我们上面已经配置连接了,按道理来说,其实这句是不需要的 -->
<!-- <property name="connection.provider_class">org.hibernate.connection.C3P0ConnectionProvider</property> -->
<!--在连接池中可用的数据库连接的最少数目 -->
<property name="c3p0.min_size">5</property>
<!--在连接池中所有数据库连接的最大数目 -->
<property name="c3p0.max_size">20</property>
<!--设定数据库连接的过期时间,以秒为单位, 如果连接池中的某个数据库连接处于空闲状态的时间超过了timeout时间,就会从连接池中清除 -->
<property name="c3p0.timeout">120</property>
<!--每3000秒检查所有连接池中的空闲连接 以秒为单位 -->
<property name="c3p0.idle_test_period">3000</property>配置日志文件log4j
下面这些在hibernate下project的任何一个项目中都有,且内容都差不多
唯一需要注意的就是最后一行
如果写的info,就会显示info,error warnning 信息,写error,就会输出error和warnning 级别的信息,这是一个层级关系
stdout是标准输出,表示输出到控制台,如果想输出到文件,需要写file
### direct log messages to stdout ###
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.Target=System.err
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%d{ABSOLUTE} %5p %c{1}:%L - %m%n
### direct messages to file mylog.log ###
log4j.appender.file=org.apache.log4j.FileAppender
log4j.appender.file.File=c\:mylog.log #日志文件的路径
log4j.appender.file.layout=org.apache.log4j.PatternLayout
log4j.appender.file.layout.ConversionPattern=%d{ABSOLUTE} %5p %c{1}:%L - %m%n
### set log levels - for more verbose logging change 'info' to 'debug' ###
# error warn info debug trace
log4j.rootLogger= info, stdouthibernate操作数据库
保存方法
save方法,提交完事务后便会把数据插入进数据库,返回的是序列化的id
这个id是我们插入到数据库的id
@Test
public void demo1()
{
//获取到session事务对象
Session session=hibernateUtils.openSession();
//手动开启事务,增,删,改才需要事务
Transaction transaction=session.beginTransaction();
//编写业务代码
Customer customer=new Customer();
customer.setCust_name("lover");
customer.setCust_phone("123456");
//需要保把我们操作的对象存到session里
session.save(customer);
//事务提交
transaction.commit();
//资源释放
session.close();
}查询方法
查询有2个方法,一个get,一个是load

二者的使用方法和结果都是一样的
get(立即加载)和load(懒加载)的区别
似乎get和load方法没有区别,但是用调试模式去看就知道
load方法采用的延迟加载,当使用了数据库里除了id以外的属性的时候才会去发送语句
load返回对象的时候,返回的是代理对象,不是真正的Customer对象,虽然数值都一样
get 只要执行完这行代码,就会去发送sql语句,get返回对象的时候,返回的是真正的对象
上面 customer2.toString会使用到其它属性,所以执行toString的时候就会发送sql语句
但是,当get方法查询了id为1的时候数据后,再去执行load方法,也去查询id为1的数据
会发现,sql语句不会发送,同理,先执行load,再执行get方法,sql语句同样只会发送一次
这里面涉及到的hibernate的缓存机制,同一条数据不会重复查询,这个后面再详解

更新方法
推荐先查询,再修改,这时候之前的数据都查询出来了
而直接更新,数据库现在cust_phone是有数值的,如果这里没有指定,也就是null
那么更新后数据库那边就会变成空
而先查询出来就不会出现这种情况

删除方法
同样是推荐先查询后删除,因为多表查询的时候可能还需要查询映射关系,有映射关系的,不能直接删除

更新或保存
设置了id,那么就是更新,没有设置id,那么就是保存

查询所有数据
这里涉及到了简单的HQL(hibernate query language)
利用HQL查询所有数据,需要注意的是,HQL里所有的表名,其实是类名
也就是说Customer其实是类名,如果说表名不是Customer,而类名是Customer
也是可以查询的,因为我们设置的映射关系的

当然也可以写sql语句
需要注意的是list返回的是List<Object []>, 把属性变成Object数组

条件查询
这里使用的是hql,所以也是对类里的属性进行条件判断,而不是表的字段

分页查询

Criteria条件查询
Criteria可以用面向对象的语言进行条件查询

like还能写第3个参数,anywhere,就是相当于 %u% 不管出现在字符串哪个地方都匹配到,还有end,start

持久化类的规则
1 hibernate因为会把对应字段的数据映射到数据库中,所以需要用到反射,
而反射就需要一个无参的构造函数,类中默认有一个无参的构造,但是如果写了有参构造
那么无参构造就失效了,所以还是需要提供无参构造,保险起见
2 需要提供一个id,也就是类里面必须写一个id属性,因为hibernate是通过这个id来判断是否是同一个java对象
3 类里的属性,必须使用包装类的类型,比如integer,Long
4 这个java类不能用final修饰,因为被final修饰的类,不能被继承,而hibernate内部是有延迟加载的
延迟加载是一种增强技术,产生对应的代理类返回给我们,而代理类是需要继承我们的类的,所以不能被final修饰
持久化类的3种状态
瞬时态
这种对象没有唯一的标识OID,也就是id没有数值,没有被session,也就是session并没有操作这个对象
这种对象被称为瞬时态对象
持久态
这种对象有唯一的标识OID,也就是id有数值,被session管理,也就是被session被操作了
托管态
这种对象有唯一的标识OID,也就是id有数值,没有被session管理,也就是没有被session操

自动更新数据库
hibernate不仅不需要写sql语句,还能自动更新数据库,但是使用自动更新数据库必须要了解上面的3种时态
可以看到,即使我们不写update语句,还是会向数据库发送语句,这就是持久态的特征
持久态的数据会和hibernate的缓存数据进行比较,如果相同,那么不会发送sql语句
如果不同,只要检测到不同,提交事务后,就会发送语句

hibernate的缓存机制
我们在一开始使用get和load方法的时候就发现,如果要查询的id相同,那么第二遍是不会发送sql语句的
为什么这样,根据上面持久化的3种状态可以解释,因为查询出来的数据是持久态数据,会优先和hibernate
的缓存数据进行比较


hibernate的事务管理
事务最复杂的就是读的问题,各种问题的理解详情https://blog.csdn.net/yzj17025693/article/details/81219928 最后面的事务部分


配置事务级别
从上到下,级别分别是 1 2 4 8


线程绑定session
之前我们说了,session并不是线程安全的,所以我们要绑定session在当前线程上,当前线程结束,session就结束
而不需要我们自己关闭,也就是不需要写session.close(),这样就不会被其它线程使用


hibernate内部已经帮我们绑定好了对象,我们只需要返回对应绑定的session即可
这个hibernateUtils工具类是在最开始的时候写的,往上能翻到

还需要在核心配置文件里配置

多表映射关系
之前我们使用了简单的增删改查,但是如果是多表查询,因为不需要写sql语句
那么就需要配置多表的映射关系

多的一方是员工,一的一方是部门,多个员工对应一个部门,多个部门不能对应一个员工,因为一个员工只能有一个部门
在多的一方建立外键对应一的一方



一对多关系案例
一个部门,一个员工


设置外键约束

建立bean类
需要在一的一方,写多的一方的集合,这里是set集合

man表的最后一个字段是dept_id,但是bean类必须写的是一的一方的对象,hibernate会给你处理

建立多对一映射

建立一对多映射
我们一的一方填写的是set集合,那么这里就要用<set>
要注意的就是key那里,那里填的是多的一方的外键,并不是一的一方的主键
只有2方都指定了外键,那么才能建立外键关系

记得还需要在核心配置文件里假如2个文件的映射

保存数据
执行完后,我们发现总共发送了11条sql语句(包含了update外键),但是我们session.save也就只使用了5次,所以这里面肯定有猫腻
是否因为设置了关联.保存一次会发送2条语句?
@Test
public void demo1()
{
//获取到session事务对象
Session session=hibernateUtils.getCurrentSession();
//手动开启事务,增,删,改才需要事务
Transaction transaction=session.beginTransaction();
//保存2个部门,3个员工
Dept dept=new Dept();
dept.setDept_name("销售部");
Dept dept2=new Dept();
dept2.setDept_name("技术部");
Man man=new Man();
man.setMan_name("小红");
Man man2=new Man();
man2.setMan_name("小明");
Man man3=new Man();
man3.setMan_name("小军");
//建立关系,man 和man2 都是销售部的,man3是技术部
man.setDept(dept);
man2.setDept(dept);
man3.setDept(dept2);
//把人员添加进来,对应的部门添加对应的人
dept.getMans().add(man);
dept.getMans().add(man2);
dept2.getMans().add(man3);
//保存数据
session.save(man);
session.save(man2);
session.save(man3);
session.save(dept);
session.save(dept2);
//事务提交
transaction.commit();
}
}通过只保存一边来测试,只保存一的一方
发现,不管是只保存多的一方还是只保存一的一方,都会出错,报错的是瞬时态对象异常,持久态对象关联了一个瞬时态对象
也就是一个保存了,一个没保存
这里就要涉及到级联操作了

级联操作
级联操作,顾名思义,就是执行一个事物,顺带会执行相关联的事务
需要在一的一方配置cascade(串联),因为我们想只保存一的一方,所以在一的一方配置
如果想只保存多的一方,那就在多的一方配置cascade
save-updae的意思,保存和更新都使用级联操作,delete是级联删除

保存一条数据做测试,这时候只会发送2条插入语句,还有1条更新外键的语句
2条插入语句,一个是保存dept2,一个是dept2关联的man3

下面这情况会发送5条插入语句,3条update 更新外键的语句,更新外键的条数,根据我们添加了几个员工来算,因为
每个员工都要有外键

级联删除
删除一边的数据,另一边也跟着删,因为如果2个表通过外键关联了,那么有外键的一方,必须要先删除,不然没外键的一方删除不了
我们在一的一方设置了级联删除,这样就可以删除一的一方,并且会把多的一方对应的数据也删了

放弃外键维护
我们发现级联删除的时候,会多产生一条update更新外键的语句
这条语句是将外键置为空,其实不用置为空,因为它会先删除与外键关联的多的一方数据
删除了之后,再删除一的一方的数据,而这条update是多余的,

可以设置一的一方放弃外键维护权利,因为一的一方没有外键
保存外键的时候,是多的一条发送语句保存的,一的一方只会产生多余的数据
inverse
这样的话,最好就是只保存多的一方,这是合理的

多对多关联映射
一个用户表,一个角色表,1个用户可以选多个角色(部门经理兼职技术员),1个角色也可以被多个用户使用
这时候就需要一个中间表
2张表的设计

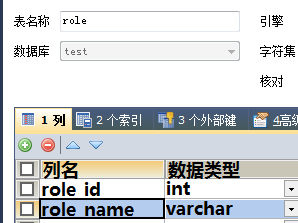
中间表的设计
相等于是2个一对多的关系,多的一方其实是中间表,一的一方是角色表和用户表

外键的配置
应该是在多的一方设置外键, 也就是在中间表设置外键
这里中间表的user_id对应的应该是user的user_id,中间表的role_id对应的是role的role_id

bean类
一的一方放多的一方的集合
中间表是多的一方,但是中间表不用建立bean类


多对多的配置
拆分成一对多配置,注意的是,因为我们并没有写中间表的bean类,所以需要指定中间表名
虽然是一对多,但是本质上还是多对多,所以需要写上many-to-many


保存数据
@Test
public void demo1()
{
//获取到session事务对象
Session session=hibernateUtils.getCurrentSession();
//手动开启事务,增,删,改才需要事务
Transaction transaction=session.beginTransaction();
User user1=new User();
user1.setUser_name("小明");
User user2=new User();
user2.setUser_name("小军");
User user3=new User();
user3.setUser_name("小红");
Role role1=new Role();
role1.setRole_name("经理");
Role role2=new Role();
role2.setRole_name("洗完工");
//设置双向关系
user1.getRoles().add(role1);
user2.getRoles().add(role1);
user3.getRoles().add(role2);
role1.getUsers().add(user1);
role1.getUsers().add(user2);
role2.getUsers().add(user3);
session.save(user1);
session.save(user2);
session.save(user3);
session.save(role1);
session.save(role2);
//事务提交
transaction.commit();
}报错,重复的主键,因为设置了双向关系,那么2者都会去操作同一个主键,所以会有问题
需要让一方放弃外键的维护权

用户选者角色,角色是被动选的,所以角色放弃外键维护权,用户的主动权更强

hibernate的查询方式

OID查询

对象导航检索

HQL查询

简单查询

设置别名查询

排序查询

条件查询
位置绑定从0开始

按名称绑定
可以写一些直观的字符串

投影查询
注意,这里是Object
其实直接写cust_name也是可以的


封装查询
询到的同时封装到对象中,这个对象必须有一个无参的构造,而且要有相应的构造函数

分页查询

聚合函数,单一结果获得
使用.list().get(0)也可以获得第1个结果,用uniqueResult同养可以获得唯一的结果

分组查询

QBC
query by criteria 条件查询




聚合函数和排序查询
rowCount其实就是count(*)

离线条件查询
这个等参数多了就很方便,因为可以在任何地方添加参数

离线查询并不支持多表的语句
需要设置别名

多表查询
建议参考 https://blog.csdn.net/xlecho/article/details/79725967


