| 本科毕业设计(论文)
|
||||
| 《基于神经网络算法在智能医疗诊断中的应用探索》 |
||||
| 《Exploration of Electronic Intelligent Medical diagnosis based on Machine Learning and Neural Network according to pathological characteristics》 |
||||
| 院(系) |
: |
计算机科学与技术系 |
||
| 专 业 |
: |
软件工程 |
||
| 班 级 |
: |
15级本科3班 |
||
| 学 号 |
: |
15210120331 |
||
| 学生姓名 |
: |
吴裕雄 |
||
| 指导教师 |
: |
李强 |
||
| 提交日期 |
: |
2019-04-25 |
||
内容摘要
机器学习决策树、K-NN算法等技术能够使得电脑等电子设备从原始的数据集中学习和发现数据存在一般知识规律,利用这门技术来处理医疗数据,研发对应的智能诊断医疗系统和设备,将会极大的改善国民生活健康水平。与机器学习密切相关的一门技术是神经网络,神经网络具备自主学习、组合已有特征的特性,经过神经网络处理的医疗记录数据集,将会得到对应高度抽象的诊断特征集,利用这个诊断特征集结合采集到的用户输入数据,神经网络模型使用激活函数、优化器、损失函数、正向传播、反向传播等数据处理技术,便能够实现电子自主学习并能高智能分析、诊断功能。基于机器学习和神经网络的类型、及其搭建的方式、相应参数的配置等诸多因素都会对诊断特征集产生影响,有些地方稍微不同,甚至就会得到完全不一样的结果。本次通过实验探索更一般的医疗智能诊断模式。
关键字:机器学习;决策树;K-NN算法;智能诊断;神经网络;自主学习;激活函数;优化器;损失函数;正向传播;反向传播
Abstract
Machine learning decision tree, K-NN algorithm and other technologies can enable electronic equipment such as computers to learn from the original data set and discover the general knowledge of data, and use this technology to process medical data. Research and development of the corresponding intelligent diagnostic medical system and equipment, will greatly improve the national standard of living health. A technique closely related to machine learning is the neural network, which has the characteristics of autonomous learning, combining the existing features, and the data set of medical records processed by the neural network will get a highly abstract diagnostic feature set. Using this diagnostic feature set combined with collected user input data, neural networks Using activation function, optimizer, loss function, forward propagation, back propagation and other data processing techniques, the complex model can realize electronic autonomous learning and high intelligent analysis and diagnosis function. Many factors such as the type of machine learning and neural network, the way they are built, the configuration of corresponding parameters and so on, will affect the diagnostic feature set. In some places, they will be slightly different, or even get completely different results. This time through the experiment to explore the more general medical intelligent diagnosis mode.
Keywords: machine learning; decision tree; K-NN algorithm; intelligent diagnosis; neural network; autonomous learning; activation function; optimizer; loss function; forward propagation; back propagation
目录
第一章 引言 5
第二章 研究现状 6
第三章 探索机器学习和神经网络内部结构数学运算原理实现过程 8
3.1 softmax函数 8
3.2深度学习的理论基础——机器学习 9
3.2.1机器学习的算法流程 9
3.2.2基本算法的分类 10
3.3机器学习基本算法 10
1、关联:Apriri算法 10
2、聚类:k-means、k-medoids、聚焦、分裂算法、视觉聚类算法 10
3、预测(分类、回归):决策树、支持向量机、正则化方法 10
3.4回归算法 11
3.4.1逻辑回归 11
3.5决策树算法的基础——信息熵 12
3.5.1ID3算法 12
3.6数据标准化 13
3.6.1 0-1标准化(0-1 normalization) 13
3.6.2 Z-score标准化(Zero-mean normalization) 13
3.7 BP神经网络算法 13
3.7.1 神经网络常用算法——最小二乘法(LS算法) 13
3.7.2 神经网络常用算法——随机梯度下降算法 14
3.8反馈神经网络反向传播算法 15
3.8.1链式求导法则 16
3.8.2反馈神经网络原理与公式推导 16
第四章 基于机器学习和神经网络探索电子智能医疗诊断 21
4.1数据集说明和获取 21
4.2使用K-NN算法探索数据集 23
4.2.1分类函数 23
4.2.2数据归一化 23
4.2.3启动和检测模型 24
4.2.4探索不同的K值对算法的影响 24
4.3使用决策树算法探索数据集 25
4.3.1定义计算属性熵值函数 25
4.3.2划分数据集 26
4.3.3选择最好的属性作为根节点 26
4.3.4投票机制 27
4.3.5创建决策树模型 27
4.3.6打印决策树 28
4.3.7使用决策树模型进行决策分类函数 28
4.3.8启动和测试模型 29
4.3.9比较K-NN算法与决策树算法的优劣 30
4.4使用神经网络探索数据集 31
4.4.1将标签转one-hot编码 31
4.4.2定义输入数据集变量 31
4.4.3权重和偏置的处理 31
4.4.4建立模型 31
4.4.5定义损失函数 32
4.4.6训练模型 32
4.4.7启动模型 32
4.4.8模型评估 32
4.4.9模型的使用 33
4.4.10使用一百条原数据进行模型的训练与测试 33
4.4.11使用AdamOptimizer优化器 33
4.4.12使用MomentumOptimizer优化器 33
4.4.13分析选定神经网络更新参数优化器 34
4.4.14损失函数的修正 34
4.4.15激活函数的修正 34
4.4.16增加神经网络更多的深度 34
第五章 比较决策树与神经网络的优劣 35
第六章 结果可视化和结论 36
6.1 统计各种算法处理模型数据 36
6.2 结果可视化 38
6.2.1 K-NN算法 38
6.2.2 K-NN算法耗时散点图 38
6.2.3 神经网络算法对应各种有用的模型设计耗时曲线图 40
6.2.4 K-NN、决策树以及神经网络算法对比 40
6.3 结论 41
参 考 文 献 42
致谢 42
表附录 43
图附录 43
第一章 引言
由于现在世界许多国家或地区公共医疗管理系统的不完善,医疗成本高、渠道少、覆盖面低等问题困扰着大众民生。尤其以“效率较低的医疗体系、质量欠佳的医疗服务、看病难且贵的就医现状”为代表的医疗问题为社会关注的主要焦点。大医院人满为患,社区医院无人问津,病人就诊手续繁琐等等问题都是由于医疗信息不畅,医疗资源两极化,医疗监督机制不全等原因导致,这些问题已经成为影响社会和谐发展的重要因素。所以有必要研究探索出一些新的理论方案和建立对应的模型来应对这些困扰我国甚至世界全人类文明发展多年的问题。基于现代最新的人工智能领域里程碑式的神经网络算法研究,表明它强大的自我学习能力能够在计算机视觉、图片识别、语音识别、自然语言处理等诸多领域实现智能化取得了许多可喜可贺的成功,有的甚至具有划时代意义,标志着新一代人工智能的到来。全世界许多医院都具备大量的医疗数据记录,但由于疾病的类型症状交叉以及所涉及的学科知识更是多种多样,没有医生能够把这些知识都理解和记忆,现在许多具备高价值的医疗数据都尘封在各自的医院数据库里面,要是能够把这些医疗数据通过高效的神经网络模型处理,实现电子高智能分析、诊断疾病,为主治医生提供有效的医疗建议,这将大大提高世界医疗和人们健康的水平,我们人类在医疗领域也将会迎来一个新时代的春天。基于神经网络探索高智能分析、诊断模型技术由此展开。
第二章 研究现状
近年来,AI医疗研究正快速渗透到包括CT图像疾病诊断、眼疾、癌症、假肢等各个医疗领域。李开复在《人工智能》一书中认为:人工智能对人类最有意义的帮助之一就是促进医疗科技的发展,让机器、算法和大数据为人类自身的健康服务,让智慧医疗成为未来地球人抵御疾病、延长寿命的核心科技。随着人工智能应用领域的推广,语音交互、计算机视觉和认知计算、云计算等技术的逐渐成熟,人工智能在医疗领域的各项运用变成了可能。这其中主要包括:语音录入病历、医疗影像智能识别、辅助诊疗/癌症诊断、医疗机器人、个人监看大数据的智能分析等。比如,利用AI来辅助疾病诊断,可以减少因为医生经验欠缺而造成的误诊,并节省医生诊断癌症所花费的时间,提高癌症早期诊断效果,大大降低癌症的死亡率。再比如,影像是重要的诊断依据,但是如何高质量的获取医疗影像数据,在医疗领域是个难题,而深度学习可以提高医学影像的品质,利用人工智能的深度学习技术就能从医学影像中提取有用的信息,帮助医生做到精准判断。
表 2-1 人工智能在医疗领域的应用
| 智能医疗领域 |
人工智能技术 |
具体应用或方法 |
| 电子病历 |
语音识别/合成、自然语言处理 |
语音识别医生诊断语录,并对信息进行结构化处理,得到可分类的病历信息 |
| 影像诊断 |
机器视觉 |
图像预处理,抓取特征等 |
| 辅助治疗 |
语音识别/合成、自然语言处理、机器视觉、机器学习 |
通过语言、图像识别技术以及电子病历信息进行机器学习,为主治医生提供参考意见 |
| 医疗机器人 |
机器人 |
手术机器人/导诊机器人 |
| 个人健康大数据分析 |
自然语言处理 |
日常健康数据分析/病情监控 |
| 精准医疗 |
语音识别、机器学习 |
DNA序列分析,疾病预防 |
表 2-2 具有重要影响的神经网络
| 神经网络名称 |
特定 |
局限性 |
典型应用领域 |
| 感知器 |
有学习能力,只能进行线性分类 |
不能识别复杂字符与输入模式的大小、平移和旋转敏感 |
文字识别、声音识别和学习记忆等 |
| 自适应线性单元 |
学习能力较强,较早开始商业应用 |
要求输入、输出之间是线性关系 |
雷达天线控制、自适应回波抵消等 |
| 小脑自动机 |
能调和各种指令系列,按需要缓慢地插入动作 |
需要复杂的控制输入 |
控制机器人的手臂运动 |
| 误差反传网络 |
多层前馈网络,采用最小均方误差学习方式,是目前应用最广泛的网络 |
需要大量输入、输出数据,训练时间长,易陷入局部极小 |
语音识别、过程控制、模式识别等 |
| 自适应共振理论 |
可以对任意多个和任意复杂的二维模式进行自组织学习 |
受平移,旋转和尺度的影响,系统较复杂 |
模式识别、擅长识别复杂、未知模式 |
| 盒中脑BSB网络 |
具有最小均方误差的单层自联想网络,类似于双向联想记忆,可对片段输入补全 |
只能作一次性决策,无重复性共振 |
解释概念形成、分类和知识处理 |
| 新认知机 |
多层结构化字符识别网络与输入模式的大小、平移和旋转无关,能识别复杂字型 |
需要大量加工单元和联系 |
手写字母识别 |
| 自组织特征映射网络 |
对输入样本自组织聚类,可映射样本空间的分布 |
模式类型数需要事先知道 |
语言识别、机器人控制,图像处理等 |
| Hopfield网络 |
单层自联想网络,可从缺损或有噪声输入中恢复完整信息 |
无学习能力,权值要预先设定 |
求解TSP问题,优化计算及联想记忆等 |
| 玻尔兹曼机、柯西机 |
采用随机学习算法的网络,可训练实现全局最优 |
玻尔兹曼机训练时间长,柯西机在某些统计分布下产生噪声 |
图像、声呐和雷达等的模式识别 |
| 双向联想记忆网 |
双向联想式单层网络,有学习功能,简单易学 |
存储的密度低,数据必须能编码 |
内容寻址的联想记忆 |
| 双向传播网 |
一种在功能上作为统计最优化和概率密度函数分析的网络 |
需要大量处理单元和连接要高度准确 |
神经网络计算机图像处理和统计分析 |
2006年以后的深度学习模型主要包括:受限玻尔兹曼机(RBM)、深层自编码器(deep AE)、深层信念网络(deep belief net)、深层玻尔兹曼机(DBM)、和积网络(SPN)、深层堆叠网络(DSN)、卷积神经网络(CNN)、循环神经网络(RNN)、长短期记忆网络(LSTM network)、强化学习网络(RLN)、生成对抗网络(GAN)。
以上各种神经网络算法或模型是世界目前研究沉淀的精华,在AI医疗影像诊断、远程患者监控、药品开发、肿瘤研究等方面应用也取得了一定成功,如Google基于开源图像识别深度学习模型Inception-v3开发的LYNA,在转移性乳腺癌的检测精度测试中,LYNA的准确率达到99%,超过人类的检测准确率;在 2016 年,Google 旗下科研机构 Google Research 宣布已经成功让人工智能检测糖尿病造成的视网膜病变,如今这项研究率先在印度展开了临床试验;各种基于神经网络的互联网AI诊断平台,最近也如雨后春笋般暂露头角。但所用的神经网络算法大都只是局限于某个医疗项目,比如:诊断肿瘤项目的算法对眼疾诊断不适应,而眼疾的诊断算法也只是针对眼疾这一种疾病,应用到其它疾病诊断就不再适合了。要开发相应的AI诊断系统,就要增加大量的人力物力财力等资源,并且这样分散的诊断系统整合成具备诊断多种疾病的高效、高智能平台,也大大增加了系统复杂度,更不易于后期系统的维护。本文的研究特点是探索更一般的神经网络模型,具备高效提取医疗数据抽象特征能力,实现高智能诊断疾病的功能。
第三章 探索机器学习和神经网络内部结构数学运算原理实现过程
3.1 softmax函数
表 3-1 softmax函数说明
| 函数名称 |
函数表达式 |
函数理解 |
| softmax |
这是深度学习中最为常见的函数,其中,是长度为j的数列V中的一个数,带入softmax的结果其实就是先对每个取e为底的指数计算变成非负数,然后除以所有项之和进行归一化,之后每个就可以理解成观察到的数据属于某个类别的概率,或者称作似然(Likelihood)。Softmax用以解决概率计算中概率结果大占绝对优势的问题。例如,函数计算结果中有两个值A和B,且A>B。如果简单地以值的大小为单位衡量,那么在后续的使用过程中A永远被选用,而B由于数值较小则不会被选择。但是有时也需要数值小的B被使用,此时softmax就可以解决这个问题。 |
3.2深度学习的理论基础——机器学习
3.2.1机器学习的算法流程
一个完整的机器学习项目包含以下内容:
a、输入数据:这是算法最开始就要进行的步骤,通过输入原始的数据集,其中数据集可以包括标签和不包括标签两种情况。这些数据要有一定的格式,只有把数据处理成算法能够读取的格式,算法才能进行后续的数据学习进一步和处理。这一部分也是作为最基础的一部分。
b、特征提取:当数据正常输入到算法之后,算法将会数据集的每一条记录进行特定流程的处理,并且会保存一些从原来数据集提出来的新的数据,并且这部分新的数据在后续的数据输入的时候可能会进一步地修改或者是影响着后面数据的处理。这部分算法中间过程从原数据提出来的新的数据作为原始数据记录的电脑能够知道和识别的特征。当原始数据特征量很多的时候,处理起来需要消耗的计算资源会很大,所有当出现数据集特征过多的时候,一般要使用其它类似PCA这样的降维技术处理。
c、模型设计:模型设计是算法用来模拟或者处理数据的的一个抽象的模式,输入到算法里面的数据主要就是按照这个模式来进行数据处理、特征提取的。训练模型一般是依靠大量可靠的数据和对应数据特征的提取。
d、数据预测:通过使用大量数据训练过了的模型,一般就具备了回答某些特定问题抽象的知识和规律,当需要被回答的问题输入到算法模型的时候,这个模型就会根据之前学习到的知识和规律,给出特定问题的回答,从而完成算法预测这样的一个过程。我们可以使用这个训练好的模型来进行模拟和拓展一些人的行为,从而能够开发出具备一定智商处理特定问题的人工智能产品。
3.2.2基本算法的分类
根据基本算法的训练模式,可将算法分成以下几类:
a、无监督学习:数据集没有特定的分类标签,只要明确的一些特征,而怎么把这些无标签的数据怎么处理进行分类的过程,完全由机器运行特定的算法来决定,所有这样的分析结果往往也是不可控的,在算法运行结束前,原始的数据具体会被划分为多少类没有办法提前预知。
b、有监督学习:算法最开始输入的数据记录是有特定的分类标签的,算法根据数据的特征和它对应的标签来进行学习,通过这样的数据不断地输入,算法不断地修正和改进模型,使得算法能够在很大程度上能够对这类的数据进行正确的预测和分类,从而达到算法分类的标准。
c、半监督学习:通过混合有标识数据和无标识数据,创建同一模型对数据进行分析和识别,算法的运行介于有监督和无监督之间,最终使得全部输入数据能够被分区。如果数据集有特征值缺失的话,那么使用半监督学习这种数据处理方式会在一定程度上减少缺失值给模型处理数据带来的影响。
d、强化学习:通过输入不同的标识数据,使用已有的机器学习数据模型,进行学习、反馈修正现有模型,从而建立一个新的能够识别输入数据的模型算法。
3.3机器学习基本算法
1、关联:Apriri算法
2、聚类:k-means、k-medoids、聚焦、分裂算法、视觉聚类算法
3、预测(分类、回归):决策树、支持向量机、正则化方法
3.4回归算法
回归分析(regression analysis)是数学上将特征量化后,确定两种或两种以上变量之间的相互关系的一种数理统计分析方法。按照自变量和因变量相互之间的关系,一般可以分为线性回归分析和非线性回归分析。如果只有一个自变量和因变量,并且二者可以用一条直线表示近似拟合表示的话,这种便是一元线性回归分析。。如果回归分析中包含两个或两个以上的自变量,且因变量和自变量之间是线性关系,则称为多元线性回归分析。
3.4.1逻辑回归
表 3-2 逻辑回归函数说明
| 名称 |
逻辑回归分析 |
| 应用 |
主要应用在分类领域 |
| 作用 |
是对不同性质的数据进行分类标识 |
| 说明 |
逻辑回归是在线性回归的算法上发展起来的,它提供一个系数θ,并对其进行求值。基于这个,便可以较好地提供支持不同的算法,从而完成对数据集的分类等功能。 |
| 公式 |
|
| 参数说明 |
与线性回归相同,这里的θ是逻辑回归的参数,即回归系数。 |
| 公式变形 |
,这个公式可以反映二元分类问题。这个y值是基于数据集中的数据和θ一起决定的。其实这个公式求的是满足一定条件的最终取值的对数概率,也就是通过数据集的可能性的比值做对数变换得到。这是的通用公式表示为: 通过这个逻辑回归推导公式可以看到,最终逻辑回归的计算可以转化成由数据集的特征向量与系数θ共同完成,然后求得的加权和,得到最终的判断结果。由前面的数学分析来看,最终逻辑回归问题又称为对系数θ求值的问题。 |
3.5决策树算法的基础——信息熵
表 3-3 信息熵公式说明
| 名称 |
信息熵 |
| 含义 |
用来度量信息的不确定性 |
| 说明 |
信息熵越大,说明某个事件或者属性中,其包含的不确定信息越大,从而反映出它对数据分析的计算就越有好处。所以当需要选择某一事件或属性来进行分析时,总是首先选择那些对应信息熵值大的事件或者属性作为待测试用,比如:决策树根节点的选择等。 |
| 公式定义 |
在一个事件中,需要了解和度量出所有属性发生可能的平均不确定性,这样才能计算出各个属性的不同信息熵值。如果其中有n种属性,其对应的概率为P1,P2,P3...Pn,且各属性之间出现时间彼此互相独立无相关性,则某一个属性的信息熵就可以定义为这个属性的对数平均值。即: |
3.5.1ID3算法
表 3-4 ID3算法函数说明
| 名称 |
ID3算法 |
| 特性 |
把信息熵的下降速度最快对应的那个属性选取为测试属性的标准 |
| 实现思路 |
选取还未被划分的具有最高信息增益的属性作为划分标准,然后继续这个过程,一直到算法生产出的决策树能够很好地拟合分类训练的样例。 |
| 核心 |
信息增益的计算 |
| 计算 |
计算一个事件中前后发生不同顺序所对应包含不同信息量的差值。比如:在决策树的生产过程中,对于根节点每个属性的选择划分,进而计算每种不同划分情况对映不同的信息熵差值。 |
| 公式 |
3.6数据标准化
3.6.1 0-1标准化(0-1 normalization)
0-1标准化也叫离差标准化,是对原始数据的线性变换,使结果落到[0,1]区间,公式如下:
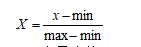
其中,max为样本数据的最大值,min为最小值。
3.6.2 Z-score标准化(Zero-mean normalization)
Z-score标准化也叫标准差标准化,经过处理的数据符合标准正态分布,即均值为0,标准差为1,其公式为:

其中,为所有样本的均值,为所有样本数据的标准差。
3.7 BP神经网络算法
BP算法(反向传播算法)的学习过程,由信息的正向传播和误差的反向传播两个过程组成。数据集所包含的信息通过事先定义好的神经网络层次结构进行纵向和横向的计算过程,这个过程从前往后,一直运算到神经网络最后输出层,这个过程称之为神经网络的前向传播过程。输入层各神经元负责接收来自外界的输入信息,并传递给中间层(隐藏层)各神经元;隐藏层主要进行数据内部信息的处理,负责将数据变形、整合、计算等信息变换过程。根据信息变换能力的需求,中间层对应地设计为单隐层或者更为复杂的多隐层结构;最后一个隐层传递信息到输出层各神经元,之后这些信息经过进一步处理后,就完成一次学习的正向传播处理过程,由输出层向外界输出信息处理结果。但是如果输出层的期望输出与其对应的实际输入不一样的时候,将会进入到神经网络的误差反向传播过程。误差从输出层开始,并按照一定的数据处理方式修正神经网络各层神经元正向传播运算时使用的权值,并且向各层隐藏层和输入层各个层次的神经元反传。 神经网络算法运行训练数据的过程,就是周而复始地信息进行正向传播和误差反向传播的过程,也是各层权值不断调整的过程。当神经网络的训练过程输出的误差减少到一定的程度又或者是达到了神经网络内部结构预先设定的循环次数,神经网络这个训练过程才结束。
3.7.1 神经网络常用算法——最小二乘法(LS算法)
表 3-5 最小二乘法说明
| 名称 |
最小二乘法 |
| 定义 |
对于给定的数据,在确定的假设空间H中,求解,使得残差的2-范数最小。 |
| 说明 |
定义中的f(x)是一条多项式曲线: ,从公式可以看出最小二乘法就是要寻找一组权值使得最小。通过微积分中求极限的处理方法,依次对权值进行求偏导数,最后令偏导数为0,即可求出极值点,过程如下: |
| 原理 |
确定预测值与真实值的差值再平方后求和,通过这样的计算和比较寻找到已知数据集的最佳匹配函数。 |
| 用途 |
可以通过最小二乘法简便地求得未确定的数据值,并且求得的这个值与对应的真实数据值之间的差的平方和最小。 |
| 差值另称 |
残差 |
| 残差表达式1 |
范数:残差绝对值的最大值,即所有数据点中残差距离的最大值。 |
| 残差表达式2 |
L1-范数:绝对残差和,即所有数据点残差距离之和。 |
| 残差表达式3 |
L2-范数:残差平方和。 |



3.7.2 神经网络常用算法——随机梯度下降算法
表 3-6 随机梯度下降说明
| 名称 |
随机梯度下降 |
| 定义 |
随机梯度下降算法通过不停地迭代数据集来寻找数据节点中数据下降幅度最大的那个趋势,一直迭代到数据在某个符合要求的范围收敛为止。 |
| 公式 |
,对于系数需要通过不停地求解出当前位置下最优化的数据,这是通过不停地对系数求偏导数,其求解公式如下: |
| 的求解 |
公式中的会向着梯度下降最快方向减少,从而推断出的最优解。因此随机梯度下降算法最终可以归结为:通过迭代计算特征值从而求出合适的值,的求解公式如下: ,公式中的a值称为下降系数,在神经网络中称之为学习率,也称为步长,是用来计算每次下降的幅度大小的,这个系数a越大则每次计算中差值也会较大,相反如果这个系数较小的话,计算的差值也会较小,但计算要花的时间也相对要延长。 |

3.8反馈神经网络反向传播算法
反向传播算法就是复合函数的链式求导法则的一个强大应用,而且实际上的应用比起理论上的推导强大许多。神经网络本质就是一个多元复合函数,通过增加神经网络的层次和神经单元,可以更好地表达函数的复合关系。如下图所示:
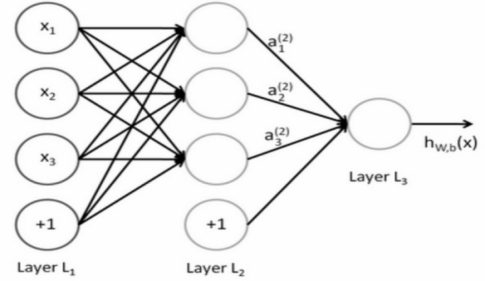
图 3-1 多层神经网络的表示
事实上,通过设置输入层、隐藏层与输出层可以形成一个多元函数求解相关问题。上图通过数学表达式将多层神经网络模型表达出来,如下:

其中x是输入的值,而w是相邻神经元的权重。
3.8.1链式求导法则
把前面损失函数以向量的形式表示为:
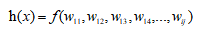
那么其梯度向量则为:

3.8.2反馈神经网络原理与公式推导
反馈神经网络算法将训练误差E看作以权重向量中每个元素为变量的高维函数,通过不断更新权重,寻找训练误差的最低点,按误差函数梯度下降的方向更新权值。
首先求得最后输出层与真实值的差距:
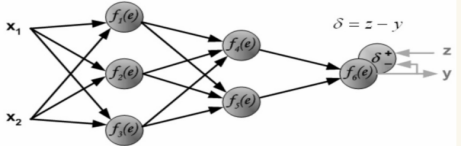
图 3-2 反馈神经网络最终误差的计算
之后计算出的测量值与真实值为起点,反向传播到上一个节点,并计算出节点的误差值:

图 3-3 反馈神经网络输出层误差的传播
接下来的计算就以节点误差重新设置为起点,依次向后传播。对于隐藏层,误差并不是像输出层一样由单个节点确定,而是由多个节点确定,因此对其的计算要求得所有的误差之和:
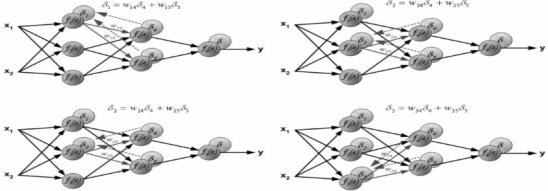
图 3-4 反馈神经网络隐藏层误差的计算
一般情况下误差的产生是由于输入值与权重的计算产生了错误,而对于输入值来说,输入值往往是固定不变的,因此对于误差的调节,则需要对权重进行更新。而权重的更新又是以输入值与真实值的偏差为基础,当最终层的输出误差被反向一层层地传播回来后,每个节点被相应地分配适合其在神经网络地位中所担负的误差,即只需要更新其所需要承担的误差量:

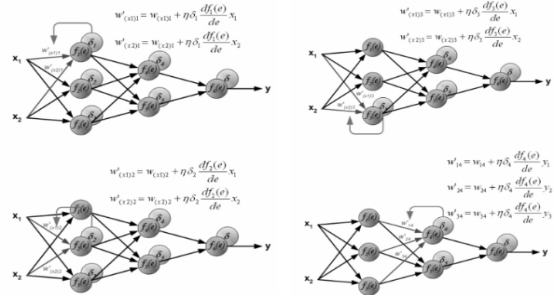
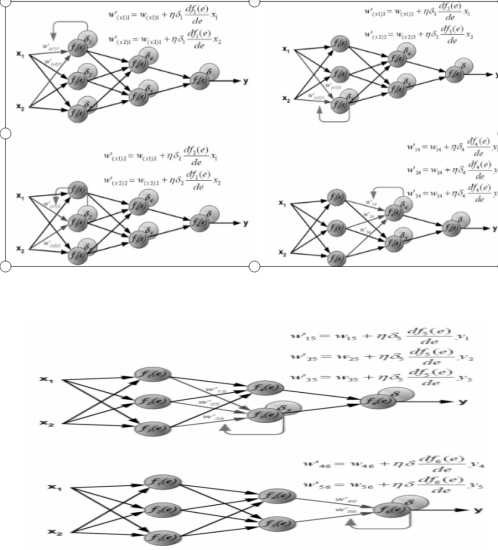

图 3-5 反馈神经网络权重的更新
即在每一层需要维护输出对当前层的微分值,该微分值相当于被复用于之前每一层里权值的微分计算。因此空间复杂度没有变化,同时也没有重复计算,每一个微分值都在之后的迭代中使用。
3.8.2.1前向传播算法
对于前向传播的值传递,隐藏层输出值定义如下:
其中是当前神经元的输入值,是连接到此神经元的权重,是输出值。f是对应当前阶段的激活函数,为当前神经元的输入值经过计算后被激活的值。
而对于输出层,定义如下:
其中为输入的权重,为输入到输出节点的输入值,这里对所有输入值进行权重计算后得到的值,作为神经网络的最后输出值。
3.8.2.2反向传播算法
与前向传播类似,需要首先定义两个值与:
其中为输出层的误差项,其计算值是真实值与模型计算值之间的差值。Y是计算值,T是真实值。为输出层的误差。
由前面的分析可以得到,神经网络反馈算法就是逐层将最终误差进行分解,即每一层只与下一层打交道。介于此可以假设每一层均为输出层的前一个层级,通过计算前一个层级与输出层的误差得到权重的更新,如下图所示:
图 3-6 反馈神经网络权重逐层的反向传导
因此反馈神经网络计算公式定义为:
即当前层输出值对误差的梯度可以通过下一层的误差与权重和输入值的梯度乘积获得。公式:中若为输出层则可以通过求得,而为非输出层时,则可以使用逐层反馈的方式求得值。或者换一种表述方式,将前面的公式表示为:
通过更为泛化的公式可以看到,把当前层的输出对输入的梯度计算转化成求下一层级的梯度计算值。
3.8.2.3权重的更新
反馈神经网络计算的目的是对权重的更新,因此与梯度下降算法类似,其更新可以仿照梯度下降对权值的更新公式:
即:
其中a表示反向传播时对应的节点系数,通过对的计算,就可以更新对应的权重值。
3.8.2.4反馈神经网络的激活函数
生物学中的神经元的突触接收信号是有一定强弱的,并且只会对超过一定范围的电信号进行处理和反馈,也就是神经元接收的信号必须要大于某个强度值,这个神经元才会对这种神经冲动做出反应。类似的,在神经网络算法中,输入的数据信息经过训练模型处理之后得到新的信号,这个信号也要大于某个设置的阀值,这样对应的神经元才会被激活从而引起数据信号后续的传递。在神经网络模型中,这种能够确定是否当前神经元节点的函数被称为激活函数。
图 3-7 反馈神经网络激活函数示意图
激活函数代表了生物神经元中接收的信号强度,目前应用范围较广的是sigmoid函数。因为其在运行过程中只接受一个值输出,也为一个值的信号,且其输出值为0到1之间。sigmoid函数表达式为:
对应的图形如下:
图 3-8 sigmoid激活函数图
而sigmoid的导函数也较为简单,即:
,换一种表达方式:
Sigmoid接收一个数值,之后将其转变成范围在0~1之间。如果是较大的负数输入的话,sigmoid函数处理后将变成0,而较大的正数sigmoid函数处理后将变成1。
第四章 基于机器学习和神经网络探索电子智能医疗诊断
4.1数据集说明和获取
数据集来源于好医生、好大夫等各类的医疗卫生系统,采用爬虫技术获胸外科胸壁结咳这种疾病诊断数据,把经过数据清洗处理后数据集当成最终的数据集,该数据集包含呼吸急促,持续性脉搏加快,畏寒,血压降低,咳血五个特征。随机抽取数据集总数的十分之一作为测试数据集,剩下的作为训练集。算法获取训练数据集和测试数据集函数:
获取训练数据集合测试数据集的这两个函数都是只接收两个参数,第一个参数是门诊类型,第二个参数是这个门诊类型里面对应的具体哪个科室。根据这两个参数获取到相应的数据集,并且通过append方法保存在列表里面,无论是训练集数据还是测试集数据,都把特征数据与标签数据分开,并保存到两个不同的列表之中。
4.2使用K-NN算法探索数据集
4.2.1分类函数
K-NN算法这个分类函数接收共要接收四个参数,第一个参数inX是待确定的数据向量,第二个参数dataSet是K-NN算法本次预测分类所要使用到的训练数据集,第三个参数labels是对应第二个参数dataSet每条数据记录的标签,第四个参数是常数k,根据这k个与未知数据inX最近的距离的各个类占比来决定未知的第一个参数inX数据属于哪个类。
4.2.2数据归一化
autoNorm函数只接收dataSet一个参数,这个参数就是原数据集。该归一化函数主要是用来将数据集的数据进行归一化处理,去除数据之间的差异性。如果数据集中的数据由于单位的不同或者是数据特征代表的范围差异很大,这时就要把原数据集进行归一化处理,并且经实践检验证明:大多数情况下,算法使用经过归一化处理后的数据集来训练模型,将会得到比原先数据没有归一化处理的好许多。这里使用常用的0-1归一化,使得数据的范围落在[0,1]之中。
4.2.3启动和检测模型
该函数datingClassTest主要用来训练和测试上面设计好的算法模型,这里算法使用的k值为3。并且计算出最后算法的错误率和准确率。
4.2.4探索不同的K值对算法的影响
K-NN算法的处理结果,很大程度上受限于分类时要使用到的那个常数K,所以很有必要分析当K值取不同的值时,算法的处理效果是如何变化的,从而才能最终确定读取最优的K值,使得算法的处理模型效果达到最好。当K分别取3,5,7,9时,对应的准确率和错误率变化如下图:
图 4-1 K取不同值时算法准确率和错误率的变化
由上图可以看到:当k=3时,算法的准确率是最高的,随着K值的增大,准确率反而降低了。
4.3使用决策树算法探索数据集
4.3.1定义计算属性熵值函数
定义calcShannonEnt函数来计算数据集中,这个函数只接收一个参数,这个参数是训练原始数据集。每个特征对应用来划分数据集之后的熵值是多少,通过计算各个属性的熵值来获取每个属性对应的信息增益,然后算法会统计、比较、记录信息增益最大的数据特征项,从而最终确定当前数据集那个最佳属性作为决策树新的根节点。
4.3.2划分数据集
定义splitDataSet函数来进行决策树模型构建过程中完成对数据集的逻辑划分,这个函数接收三个参数,第一个参数是需要被进一步被划分的数据集dataSet,第二个参数是这次划分的最优特征下标,第三个参数是对应第二个参数也就是这个信息增益最大的特征中的某个具体值,根据这个最优的数据特征的各个具体值来进行完成对数据的逻辑划分。算法会递归计算出每个特征的熵值,然后再统计计算对应特征的信息增益,然后再递归调用这个函数来对原始数据完成逻辑划分。
4.3.3选择最好的属性作为根节点
定义chooseBestFeatureToSplit函数来完成选择数据集当中最优的划分属性作为根节点。该函数主要是通过循环的方式对需要选择最优属性的数据集每个特征进行逐个地计算对应的熵值,然后再进一步计算对的信息增益,通过比较记录下信息增益最大的那个特征所对应的下标值,并且返回这个最优属性的下标值。
4.3.4投票机制
定义一个投票机制majorityCnt这样的一个函数,这个函数只接收classList一个参数,主要用这个函数来处理这样的情况:当未知分类数据遍历完整棵决策树时,还未能决策出该未知数据到底该属于哪个类别时,只剩下标签一列时,通过统计剩下的这些类别种类,然后计算哪个类别占的比例最大,那么决策树就按照这个类别来对这个未知数据进行决策分类。
4.3.5创建决策树模型
定义createTree函数来进行决策树算法模型的创建,这个函数接收两个参数,第一个参数是原始数据集dataSet,第二个参数labels是数据集的特征向量。该函数主要是通过调用上面的函数来进行模型的创建,首先是判断数据集是否是可以直接明确得出分类的结果,如果不能就选择出当前这个数据集的最优特征来作为根节点,并且取出这个特征和这个特征里面所有不同的值,然后在此基础上再进行数据量的逻辑化分,从而确定下一个根节点和叶子节点,所以这个函数主要是通过回归调用此方法创建决策树。
4.3.6打印决策树
因为是以字典的形式保存整个决策树模型的,以数据集特征作为根节点,对应位于字典的key位置,每个特征的具体值是属于决策树边上的判决条件,最后的末尾值就是对应着每个叶子节点,也就是数据集中具体的类别标签。
4.3.7使用决策树模型进行决策分类函数
定义classify函数来进行决策树模型的使用和完成预测功能。这个函数接收三个参数,第一个参数inputTree是训练得到的决策树模型,第二个参数是featLabels当前数据集的特征列表,最后一个参数testVec是未知分类的数据向量。该函数主要就是根据未知的数据向量来遍历整棵决策树,从而得到最后的分类结果。首先是获取决策树的根节点并且根据这个根节点取出对应的特征属性,然后再根据这个属性作为决策树的key值,得到当前根节点下的子树,然后一直持续这个遍历决策树的过程,直到决策树的key对应的值不再是子树而是叶子节点为止,记录并返回这个叶子节点值作为未知数据向量的最终的分类结果。
4.3.8启动和测试模型
定义datingClassTest函数来进行决策树模型的创建和模型的测试,该函数首先是获取到训练数据和测试数据,然后再分别调用上面的各个功能函数来处理、创建决策树模型,并把测试数据集输入到模型里面,并且统计模型的准确率、错误率以及算法运行的时间代价,用来衡量和判断该决策树模型的优良的一个标准。
4.3.9比较K-NN算法与决策树算法的优劣
图 4-2 K-NN算法与决策树准确率比较直方图
从准确率上看,决策树算法要比K-NN算法的高出1.7个百分点,并且时间少用了1.19秒,由此可以得出:使用决策树算法比K-NN算法来处理的效果会更好些。
4.4使用神经网络探索数据集
4.4.1将标签转one-hot编码
定义onehot函数用来转变数据集标签的编码(表示方式),该函数只接收labels一个参数,这个参数就是数据集原来的标签值。经过onehot编码处理后的结果作为新的数据集标签,这样进行处理和转换的目的是为了方便神经网络的优化器反向传播处理更新参数和统计比较模型的准确率表达式函数的参数格式。
4.4.2定义输入数据集变量
定义神经网络接收数据集的变量x_data和y_data,数值类型是小数float32类型,数据集变量有五个特征项,标签变量有三个特征项(转onehot编码之后)。神经网络后面的输入层各个神经元的数据来源便是由此代入模型,并且训练神经网络模型。
4.4.3权重和偏置的处理
定义该层神经元的权重变量和偏值变量,都初始化为1,这两个变量的数值会随着神经网络训练的正向传播过程和反向传播过程的进行而发生更改,更改后的权重和偏值将会更加能够拟合、抽象原数据的特征,从而使得最终的神经网络模型的准确率更高。
4.4.4建立模型
定义该层神经网络的运算判断模型,并且这里使用softmax作为模型的激活函数。
4.4.5定义损失函数
定义该神经网络用来计算损失的函数,神经网络模型的反向传播过程,就是根据这个损失函数计算得到的误差值来进行反向链式求导,进而来寻求最优的权值参数,并完成各层神经元的权值的更新,这里使用最小二乘法计算损失。
4.4.6训练模型
定义GradientDescentOptimizer作为神经网络的优化器,结合上面定义的计算神经网络损失的函数,并且设置该优化器的学习率为1e-4来进行模型的训练。
4.4.7启动模型
首先把模型的各层神经元参数实例化,然后把数据集进行分块处理,将训练数据集按每块100条记录添加到神经网络进行模型的训练。然后开始执行神经网络的训练过程,并且统计计算该神经网络模型的准确率和消耗的时间代价的大小,用来进行该神经网络模型优良的评估。
4.4.8模型评估
在这里找出在模型训练过程中模型计算正确的结果。Tensorflow提供了tf.argmax函数,它能给出计算张量在某一维度上的最大值的索引,即通过比较模型标签取得最大值的位置和真实值标签最大值(1)的位置(one-hot编码的作用结果),从而检测模型值与真实值是否相互匹配,tf.equal函数返回的是一系列的布尔值。为了更好地对这些值进行描述,之后将其转化成浮点值,而这些浮点值可以将其转化成数值类型通过求取平均值来描述模型的准确率。
4.4.9模型的使用
这里已经存储了训练的模型和其中的参数weight和bias,它的作用是通过feed-dict函数将数据集放入神经网络模型从而获得最终的结果。
4.4.10使用一百条原数据进行模型的训练与测试
首先通过更改训练数据的数据量的方式探索该神经网络模式,然后再次运行该神经网络模型。
4.4.11使用AdamOptimizer优化器
然后继续使用上面的数据集来更进一步进探索优化器对该神经网络模型的影响,这里使用的是AdamOptimizer优化器,并且学习率是1e-4,损失函数是最小二乘法计算得到。
4.4.12使用MomentumOptimizer优化器
还是使用上面的数据集来更进一步进探索优化器对该神经网络模型的影响,不过这里使用的是MomentumOptimizer优化器,并且学习率是1e-4,损失函数是最小二乘法计算得到。
4.4.13分析选定神经网络更新参数优化器
在相同的训练数据量和测试数据量下,GradientDescentOptimizer、AdamOptimizer、MomentumOptimizer这三种优化器得到神经网络模型的最终准确率都是一样的,但在时间消耗代价上取有所不同,这三类优化器它们的时间代价分别是:0.06秒、0.08秒、0.09秒。可以看到,该神经网络模型使用GradientDescentOptimizer优化器时,时间消耗代价最少。所有该神经网络模型后面的修正都是基于应用该优化器来进行,以探索出处理原始数据集最优的神经网络模型。
4.4.14损失函数的修正
更换计算损失函数,这里使用交叉熵作为新神经网络模型的损失函数。
可以得出:与交叉熵损失函数相比较,最小二乘法的效率更高些。
4.4.15激活函数的修正
更换神经网络的激活函数,这里使用tf.nn.relu函数作为新神经网络模型激活函数。
可以得出:与relu激活函数相比,softmax激活函数的处理效率高出了0.33秒。
4.4.16增加神经网络更多的深度
改变原神经网络模型的隐藏层层数来探索新的神经网络模型来处理原数据集的效果,这里通过将原来神经网络的一个隐藏层增加到两个,从而得到一个新的神经网络模型。
可以得到:在得到相同的准确率下,一个隐藏层的处理效率高出了0.36秒。
第五章 比较决策树与神经网络的优劣
这两种算法在相同的数据量情况下,模型准确率和耗时如下:
图 5-1 决策树与神经网络准确率和耗时比较
决策树耗时0.05秒,而神经网络耗时0.36秒,但神经网络的准确率比决策树的要高出0.3个百分点。由此可见在数据量相同的情况下,决策树与神经网络各有优劣。
在不确定算法训练数据量的情况下,根据前面分析神经网络使用一百条数据就可以将所有的数据情况进行学习和拟合,使用同样的一百条训练数据决策树却做不到这一点,这说明:神经网络比决策树算法更具学习抽象和概括知识的能力,并且这时的神经网络耗时只需0.06秒,并且还比决策树高出了0.3个百分点。
第六章 结果可视化和结论
6.1 统计各种算法处理模型数据
6.2 结果可视化
6.2.1 K-NN算法
当K取3、5、7、9、11、13时的准确率饼图分布显示如下:
图 6-1 当K取不同值时算法准确率占比情况
从图6-1可以得出:当K=3时,K-NN算法的准确率占的比重是最高的。
6.2.2 K-NN算法耗时散点图
当K取3、5、7、9、11、13时的耗时情况显示如下:
图 6-2 K取不同值时算法耗时情况
从上面6-2的的散点图可以得出:当K取3时,算法的效率相对于其它的情况是最高的。
结合图6-1和图6-2很容易得到:当K=3时,K-NN算法的性能是最好的。
结合前面的分析也很容易得出:虽然当K=3时,K-NN算法性能是最好的,但相对于决策树来说,其在准确率和效率上,还是不如决策树算法优良的。
6.2.3 神经网络算法对应各种有用的模型设计耗时曲线图
图 6-3 成功神经网络模型耗时曲线图
从上图6-2可以得出:准确率一定时,第八个模型耗时是最少的,也就是说:第八个神经网络模型的设计是比较能够快速地学习和拟合这个医疗数据集,是相对于其它的神经网络模型,它是最好的。
6.2.4 K-NN、决策树以及神经网络算法对比
当K-NN、决策树、神经网络设计模式不一样时的准确率对比饼图分布显示如下:
图 6-4 不同K-NN、决策树、神经网络算法准确率占比情况
结合上面的分析,由上图6-3和图6-4很容易得出:这次基于神经网络算法在智能医疗诊断中的应用探索得到的最优处理方案是神经网络模型8,也就是上面的 交叉熵 softmax MomentumOptimizer 模型 。用这个模型来处理对应这部分医疗诊断数据的话,准确率将能够达到87.4%,总耗时为0.06秒,也是在各种算法中效率最高的。
6.3 结论
机器学习算法中相对K-NN算法,决策树的准确率更高,并且运行效率也比K-NN算法要优越许多。在数据量相同的情况下,决策树算法的效率比神经网络要高些,但准确率比神经网络要低些;在不确定训练数据量的情况下,神经网络算法相对于决策树只需要少量的数据量便能学习和抽象概括到数据集更多隐藏的知识,这时的神经网络的学习效率不仅与决策树不相上下,而且准确率比决策树还要高些。所以可以探索得出:相对于传统的机器学习算法,神经网络算法具有更一般的强抽象学习和概括能力,并且对处理这方面的医疗数据更适合使用神经网络算法处理。
参 考 文 献
[1]Pang-Ning Tan,Michael Steinbach,Vipin Kumar著,范明,范宏建等译。数据挖掘导论(完整版)。2011年01月。人民邮电出版社。
[2]Peternal Harrington著,李锐、李鹏、曲亚东、王斌译。机器学习实战。2013年06月01日。人民邮电出版社。
[3]李玉鑑 ,张婷, 单传辉 ,刘兆英著,深度学习 卷积神经网络从入门到精通。2018年07月。机械工业出版社。
[4]郑泽宇,梁博文,顾思宇著。TensorFlow:实战Google深度学习框架(第2版)。2018年,电子工业出版社。
[5]李兴华,王月清著,Java Web开发实战经典。2010年08月。清华大学出版社。
[6]李刚著。轻量级Java EE企业应用实战(第5版)。2018年3月。电子工业出版社。
致谢
从开始筹备毕业设计开始,一直到现在完成整个毕业论文定稿,智能医疗是一个未来很有活力和竞争力的一个大市场、也是未来人工智能时代发展的一个大方向,在这个全新的技术领域,我为有幸接触到这方面技术的探索,而感到高兴和自豪。在这长达四个多月的毕业设计中,虽然过程进展得不是那么顺利,也遇到过非技术性的各种困难与挫折,甚至也怀疑过自己是否真的能够完成这个全新的大方向课题...但在自己内心不断默默地坚持着,查看国内外相关的资料、做笔记、思考学习、反思、再思考学习、再反思.......就是这样反反复复,修修改改...积累到了一定的程度后来慢慢地整个课题思路才逐渐地清晰浮现,并最终完成了这整个课题的设计。
就像前面述说的那样毕业设计过程遇到了困难,在这里我要非常感谢广东东软学院计算机系的李强老师,因为是她给了我这么一个机会,让我接触到智能医疗这个未来充满机遇的课题,同样也是她在我遇到困难的时候,给予我理解和肯定,更是十分感激她给了我很多的建议和要求,使得我鼓足干劲地按照老师的要求完成好......除此之外,我还要感谢大学本科四年期间学院那些兢兢业业的教师们,是他们把知识传授给了我,让我可以缘着计算机程序设计、计算机网络、计算机系统、人工智能等多个方向前行。
最后也非常感谢广大的书本作者和网上计算博客的博主们,有许多的知识也来源是他们,有许多问题也依靠他们无私地公开分享知识,让我少走了许多弯路。
表附录
表 2-1 人工智能在医疗领域的应用 7
表 2-2 具有重要影响的神经网络 8
表 3-1 softmax函数说明 9
表 3-2 逻辑回归函数说明 12
表 3-3 信息熵公式说明 12
表 3-4 ID3算法函数说明 13
表 3-5 最小二乘法说明 14
表 3-6 随机梯度下降说明 15
图附录
图 3-1 多层神经网络的表示 16
图 3-2 反馈神经网络最终误差的计算 17
图 3-3 反馈神经网络输出层误差的传播 17
图 3-4 反馈神经网络隐藏层误差的计算 17
图 3-5 反馈神经网络权重的更新 18
图 3-6 反馈神经网络权重逐层的反向传导 19
图 3-7 反馈神经网络激活函数示意图 21
图 3-8 sigmoid激活函数图 21
图 4-1 K取不同值时算法准确率和错误率的变化 25
图 4-2 K-NN算法与决策树准确率比较直方图 30
图 5-1 决策树与神经网络准确率和耗时比较 35
图 6-1 当K取不同值时算法准确率占比情况 38
图 6-2 K取不同值时算法耗时情况 39
图 6-3 成功神经网络模型耗时曲线图 40
图 6-4 不同K-NN、决策树、神经网络算法准确率占比情况 41