一、防火墙基本原理及网络安全相关技术的引入
Firewall:防火墙,隔离工具;
做一个不太正式但容易让人理解的定义:防火墙是工作于主机或网络的边缘处,对于进出本主机或本地网络的报文,根据事先定义好的检查规则作匹配检测,对于那些能够被检查规则所匹配到的报文做出处理的组件;
需要注意的是:
- 网络攻击当中的网络的不安全潜在的危险因素通常都是一些攻击报文,对于主动攻击的无非就是发送一些经过特殊伪造的报文来对主机或网络发起攻击窃取资料。需要注意的是,防火墙和杀毒软件是两回事,防火墙主要是跟网络攻击相关,而对于本地的程序病毒是没有太大的关联性的或者严格意义上来讲并不是同一个东西;
- 到底是主机防火墙还是网络防火墙,这取决于是工作在主机边缘为一个主机提供服务还是工作在网络边缘为网络提供服务的;
防火墙分为两类:
主机防火墙:
网络防火墙:
防火墙工作在边缘位置,这个边缘一定是报文进出的地方才可以。对于Linux主机来讲,TCP/IP协议栈是在内核中实现的,那防火墙对于一个主机来讲应该工作在内核空间,因为所有进出本主机的报文都肯定是通过TCP/IP协议栈来实现的。因为我们现在互联网上所用到的或者所用于实现通信的组件无非就是TCP/IP协议的实现,而能够接受报文的硬件设备就是网卡而已,网卡作为一个硬件设备来讲也只有内核通过驱动程序能访问到,所以说一个主机防火墙对于Linux而言应该放在内核空间的什么地方呢?如果在网卡的驱动程序上的话那就简单,但问题是网卡的驱动程序仅仅只能用来做驱动不能做防火墙,而且我们也不应该让驱动做防火墙,因为驱动本身只是让硬件工作的,它对于报文本身没有任何在协议层的理解。
刚刚说过防火墙是对于进出本主机的报文根据事先定义好的规则做匹配检测的,那么这个规则是什么呢?简单来讲,检查一个报文的源IP、目标IP、源端口、目标端口等等。这些其实就是是我们写检查规则基于的基本标准,那么很显然在驱动程序上它是无法理解协议本身具备的意义的。由此,我们这里的防火墙应该在那些协议层次上能够理解协议的位置进行,因此在内核中TCP/IP协议栈上去放防火墙就可以了。
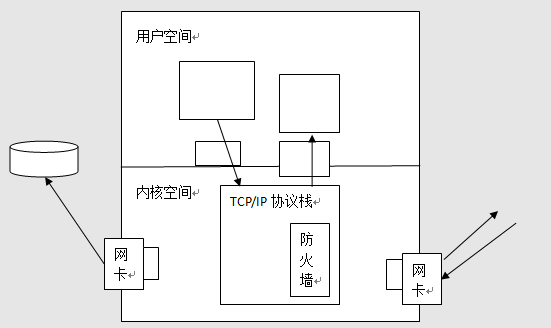
但是TCP/IP协议栈很多,其中有TCP协议、IP协议等等,那我们应该把防火墙放在哪个对应的位置做检测呢?首先我们来分析一下,对于本机而言报文有几种走向呢?对于一台主机来讲,我们所能接受到的报文是别人发送过来进入到主机内部的报文,那么接收进来的报文有两种不同的走向。如果有报文发到本机上来了那就意味着目标地址可能是本机,这是一种可能,目标地址是本机的所有报文本机的TCP/IP协议栈就应该拆封装最终把这个请求根据对方所访问到的目标端口送给注册监听在这个目标端口上的应用程序,所以这是第一种走势;

第二种走向,对方发送的报文的目标地址不是本机,但如果不是本机它为什么会把报文发送到本机上来呢?因为有可能一个主机把网关设为了本机的网卡IP地址,这个时候主机把它的报文交给下一跳,由下一跳负责转发,所以其目标地址不是本机,Linux网络协议栈中有一个功能叫核心转发(ipforward),若打开了核心转发,那这个报文会根据我们本机所理解的、所记录的路由表选路以后有可能通过另外一个网卡,也有可能通过本网卡重新发送出去了,这叫做转发。收到以后只要本机打开了核心转发功能并通过检查本机路由表知道到达目标IP大概会经过下一个主机是谁,因此,他将转发给下一跳,这就意味着有可能这个报文通过另外一块网卡出去了,那这个时候它并没有进入本地的用户空间因此跟本地用户空间没有关系。
所以从上述分析我们可以知道,一个报文到达本机后可能有两种不同的走向,一种是到本机内部来,另外一种是通过本机的另外一个接口甚至有可能是本机的同一个接口(因为同一个接口上可以配置n个IP地址)重新发送出去,在同一网络中可能多个不同的网关或主机实现报文转发的。这是报文到达本机的可能性。
那考虑另外一种情形,本机有没有可能向外发送报文呢?像上述报文到达本机是别人访问我们或者经过我们转发的,那我们作为本机访问别的主机是一种什么样的场景和情形呢?比如说本地打开浏览器访问一个网站就是本机访问别的主机的情形,这就是所谓的出去的报文,出去的报文不能直接通过用户空间出去,而应该通过内核空间中的TCP/IP协议栈发出去。而发往TCP/IP协议栈后,这个主机发现本机有多个网络接口,那就需要通过路由选择一条通路最终决定从哪个接口发出去。
所以对于单个主机来讲,报文就有这样几种流向,进入本主机的可以到本地用户空间的某个应用程序,也可以经由本主机内核核心转发经过其它接口发出去,还有一种情形就是本机内部的某个应用进程试图跟外部的其它主机发起通信时,它将通过本地的TCP/IP协议栈与其它主机通信,那基于这几种情形我们应该把防火墙放在什么位置呢?其实只放在一个位置是不能解决所有问题的,所以说我们需要在整个TCP/IP协议栈上根据报文的不同流向分别进行不同情形下的检查。例如:所有到达本机内部的就专门对这种报文做检查、凡是从本机内部出去的我们给它做检查、凡是经由本机转发的不会经过用户空间这种情况也需要在一个特定位置做检查,所以虽然叫一个防火墙,但在TCP/IP协议栈内部我们需要在三个报文不同流经的位置分别做检查,这个我们把它称作防火墙框架,整个框架可能并不会由一个组件组成。
所以所谓防火墙机制就是在内核由防火墙的设计者在TCP/IP协议栈上精心选择了几个卡点或者说报文必然流经的位置给它设置了多个钩子函数,可以想象一下钩子函数就是一个吊钩的意思,可以想象成所有进出的人流都必然经由的这个位置,像我们坐火车一样要想进站和出站都得检票。此处也有进口和出口的不同卡点,而钩子函数就相当于一个检票机或者检票员,对任何一个经由此处的报文就由钩子勾起来挡住,然后用规则一条一条比对检查一下是否符合规则中定义的标准,如果符合某一个规则的标准,则经过那个规则后的处理方式做出相应处理即可。
对于Linux而言,我们所提到的TCP/IP协议栈上对报文基于特定规则做处理时,不仅仅需要防火有时候还需要额外的其它功能。因为防火墙未必能防火,在一定程度上来讲,它可能对于某些特定规则或特定应用或特定报文给它伪装一下让本来能够防着的却又不防。所以有必要的时候,我们有可能要对某些报文中的内容做一些修改,而不对其做防范检查,仅仅是做一些额外处理等等。
而nat(网络地址转换)其实就是转换一个报文的源IP地址或者目标IP地址,另外pat(端口地址转换)也就意味着还可以改目标端口甚至是源端口的。那这种修改操作并不是防火功能的。例如:如果检查规则明确说明凡是来自于1.1.1.1的报文(报文源地址是1.1.1.1)都拒绝访问本机,但这个规则应该是到本机内部时才能检查,但是像这种报文如果我们想悄无声息的将源地址修改让其绕过防火墙到达目的地,怎么办呢?是在规则检查以后再改还是规则检查以前再改呢?报文对应相关内容的修改应该是在检查发生以前更改,而报文的三种流向都不适合于进行更改,那么应该放在哪进行更改呢?我们应当知道的是不管报文是往哪去,在刚进入本机就进行匹配度检测,事先做处理这是比较妥当的。此外还有一种情形,不管是从本机内部出来的还是经由本机转发的,任何报文要想通过本机,无论经由哪一块网卡要离开本机了,都要进行拦截,那应该怎么实现呢?
因此,对于整个主机的防火墙来讲,这里所设置的卡哨或设置的规则检查匹配度,为了辅助这三个位置工作,需要在前后两方设置两个卡点,能够对那些刚刚进入本机或马上要离开本机的报文进行处理。所以说对应一个本机的防火墙内部的实现构建是它大体上需要实现这么一个框架才能够完成我们所描述的防火功能的。
上述我们描述主机防火墙所考虑的问题,那网络防火墙呢?

网络防火墙就意味着卡点不能放在一个主机上了,主机防火墙只需要一个主机在内部的内核的TCP/IP协议栈内部去选择5个卡点,从本机出来的、到达本机内部的、经由本机转发的都可以做一些规则检查,而那些刚刚进入本机或要从本机出去了需要实现做两个卡点,这就是5个卡点。
但问题是现在我们面临的防火墙不是单台主机了,而是整个网络,一个网络内部有很多主机,并且有能力在单个主机上自行设定防火墙能力的人不多。所以我们最好能够替它们做好防护工作。那也就意味着我们对整个网络进出口的这个位置给它专门设置一个能够对进出本网络的报文的防火墙,经由这个防火墙做一下检测。这个防火墙首先它应该是一个独立的硬件设备,当然它起到防火功能的有可能是内部的硬件设定,也有可能是在硬件设备上编写的规则,这是必然的。但是这个设备它应该是什么呢?是一个Linux主机可不可以呢?此外还需考虑一个问题,若出现内网中的两台主机相互攻击呢?此时防火墙是没有起到作用的,所以防火墙在实现防火时,一定只能对那些经由本主机的报文做检测。
如果本地内网有一个服务器,而内网有一台主机对发起了攻击,此时防火墙是没有用的,因此首先网络上应该有一个端口防火墙,先过滤一部分报文防范外部攻击。然而每一台主机可能需要防范的规则和标准是不一样的,因此每一台主机需要有防火墙用来防范内部攻击,当然也能达到防范外部攻击。
当然防火墙规则是死的,但是如果实现有些新奇的攻击方式我们实现未添加防范规则该怎么办呢?我们不能对所有访问本主机的报文都拒之门外,这样作为服务器的意义就不复存在了。因此我们作为主机来讲填进去的防火规则一定是只能防范那些已知的、事先能够理解到的、认为可能存在的攻击,写的规则也是写死的。而如果有些人经过巧妙伪装后,它让自己的行为看上去并非攻击行为,将其放行到本地网络或本机内部后立即原形毕露,窃取数据、攻击服务,该怎么办呢?防火墙就束手无策了,因为设计的规则检查没办法防范这个东西,所以对于任何一个进出的报文,我们压根检测不了,但是它却做出了破坏性的行为。(需要注意的是,网络攻击跟毒是两码事,比如说访问一个文件,跟杀毒没有关系)
所以没有万无一失的安全性,其实我们也可以这样做,假如说一个用户它潜入到网络或主机中来,以Web服务器为例,我们对它的期望是仅仅是让它访问Web服务器下的页面,但是它却访问了其它页面,我们就可以认为这是一个不轨行为。由此说我们可以有事先定义好的有一些所谓的行为侦测机制能够识别出所谓它做出了不轨行为,这个时候立即进入防火墙,告诉它把这个报文挡在门外不要让它再访问了。因此我们必须要有一套额外的系统能检测或区辩出什么样的行为叫作不轨行为,而这种系统就叫作入侵检测系统(IDS)。一个进程在本地主机内部访问数据是根据我们界定的正常范围法则内它的正常访问我们都是允许的,但如果它一旦做出一些不轨行为系统是都能立即探测的到的,但是需要注意的是,入侵检测系统仅能够检测到入侵。
而IDS如果说它能够发现侦测到所谓的攻击行为,并将这个攻击行为通告给Firewall,如果Firewall在这个条件触发以后能自行再生成一条规则,把这种所谓有潜在攻击行为的报文给拒之门外,于是它就能实现叫入侵检测和防火墙联动所实现的功能,如果而这两个能合起来的话,就称为IPS(入侵防御系统)。但不是所有的IDS都能跟Firewall联动起来的一般来讲,IDS如果没有能力通知给Firewall并触发Firewall添加规则直接能够自动的把那些攻击行为的报文挡在门外的话,那可以有一个简单的方式,就是IDS检测攻击后它能够触发报警,怎么触发呢?一旦发现有攻击行为它赶紧发一封邮件给管理员,这是一个比较妥当的做法,但是这种做法有滞后性,所以如果它能通知给Firewall是最理想的状态。
IDS有两种常见的实现:
- HIDS:主机入侵检测系统,工作在主机上,只需要在单台主机上部署。
- NIDS:网络入侵检测系统,工作在网络通道上,通常需要在网络中的多个位置部署传感器。可以在每一个关键性的服务器之前的任何报文进出的位置给它部署一个传感器等等。
蜜罐:
但是对于IDS与IPS而言,它们也只是在用户发出攻击行为以后才能做出反应的。那如果要想对某些疑似攻击的报文进行处理的话,可通过“钓鱼之法”,因此我们将来也可以在网络内部部署一个honeypot(蜜罐)。
二、iptables相关概念
iptables防火墙通常称为包过滤型防火墙,即只是对包的TCP或IP或UDP首部做检测、匹配等完成过滤的,所以被称为包过滤型防火墙。
思考一下,iptables是什么呢?我们已经知道防火墙是工作在内核中的,即防火墙应该是内核中所实现的功能,而我们在使用iptables时,使用的是它的命令,但是既然我们可以把它当命令使用,那它会是内核中的东西吗?想象一下,我们可以将内核模块当命令使用吗?显然是不可能将内核本身的某个模块当做命令使用,因此iptables不是内核中的防火墙。那iptables是什么呢?
我们说过,要想实现在主机上完成防火墙的功能,意味着需要在内核中的TCP/IP协议栈上的数据报文流经的位置设置几个钩子,能够把那个对应的报文勾起来通过规则来检测,如果说没有这么一个钩子的话,首先,何处放规则?其次,规则放上去也是没用的。由此,我们所说的iptables其实是由两个部分组成的:
- iptables
- netfilter
其实,iptables的全称叫做iptables/netfilter;
而我们说的内核中设置了5个钩子,这5个位置所实现的叫一个框架(framework,内核中的网络报文过滤或处理框架),而netfilter就是这么一个内核TCP/IP协议栈内部所实现的网络过滤器的框架,说白了就是由它来负责提供钩子(hook),对于网络中的功能,钩子就是一些函数,称为钩子函数(hook function)。
而iptables用来做什么呢?有钩子仅仅能把报文勾起来,但这个报文到底符不符合某个匹配规则、如果匹配以后对于它做什么样的处理呢,所以规则才是真正负责检查并完成过滤或完成防火功能的组件。但是这个规则必须能够放置在恰当位置才能发挥作用的,我们可以想象成iptables就是负责向这5个钩子上添加、删除、修改规则的。所以iptables是一个规则管理工具(rule utils)。
站在这个角度来想,iptables是工作在用户空间的程序,netfilter才是真正能够实现防火墙的框架,但是二者谁离开谁都不可以,因为这5个钩子只是能够实现让至少选择这5个位置的任何一个报文经由、到达本机、从本机出发时必然会经由某一个位置,这几个卡哨做好以后并没有特别多的作用,因为最多只是我们已经界定报文应该流经什么位置。而真正能够发挥所谓网络防火墙或主机防火墙的功能的,是我们需要在这个位置上添加许许多多的检查规则,并一旦匹配到规则后做出相应处理,这才是应该要完备的功能。所以我们说netfilter是内核中本身就具备的框架,一旦我们想让它实现防火,那我们就使用iptables写一个规则把它扔到这个框架上去就能立即发挥作用了。
但是内核的某个功能发挥作用和应用程序发挥作用实现方式其实还不一样的,一个应用程序只有运行起来才能发挥作用,就像我们启动一个web服务,把httpd进程运行起来才能接收客户端访问,但是并没有把内核启动起来的概念,其实只要主机处于运行当中,内核就处于运行当中,所以iptables所写的规则只要将其扔到这个规则netfilter中去,它就会立即发挥作用了。而运行中的内核是在内存中的,那我们扔这个规则其实是把它扔到内存中去了。那也就意味着一关机的话扔的规则就没有了,于是为了让以后都有效就需要将iptables命令写成脚本,开机的时候让它自动运行这个脚本即可。
因此我们在开机的时候启动防火墙并不是将它启动为什么服务的,而仅仅是让这些规则重新生成一遍仅此而已。所以防火墙从来都不是服务,它不会启动进程,但为了统一管理,在CentOS 6上我们依然将它叫做iptables服务,但它真正发挥作用在开机启动时无非就是把一个规则文件给它重新生效一次,它没有运行任何进程因为它不需要进程,它是在内核上发挥作用的。
链:
5个钩子函数有特定的学术称呼,我们在添加规则时,要想扔一条规则到防火墙上,应该扔在什么位置,这5个的哪个位置呢?这需要看目的,是打算去限制本机访问别人、还是限制别人访问本机、还是限制那些报文经由本机转发时能不能转发,因此我们扔的位置应该是不同的,这也就意味着我们在写iptables规则时应该写明这个规则将其放在这5个钩子函数的哪个钩子上。所以就需要利用某一个名称来引用这个钩子以致于将来规则添加到哪个钩子上,所以在iptables的名称上下文或名称空间中,这5个钩子函数各有一个名称,它们被称为一个链。
但是为什么被称为链呢?我们需要了解一下iptables的前身。
其实早些时候,Linux上是没有内核中的软件防火墙的,而著名的Unix发行版BSD系统中有一项叫做Open BSD,它的主要着眼点为安全,被称为最安全的BSD发行版,Open BSD中各种安全体系做的非常完善。那个时候Linux刚诞生不就还没有防火墙,所以Linux就借鉴了Open BSD内部防火墙实现机制,模仿它们在内核中也实现了一个,早些时候叫ipfw,当然它也有自己内核中的框架,那个时候框架很简单,还没有成体系。那个时候还是在Linux2.0左右,而过一段时间,人们发现ipfw这种实现机制太粗浅,于是就把这个在内核中实现的这种防火墙通过添加规则的方式来完成防火功能,规则多了,穿起来就像链了,这个时候叫做ipchains。后来人们又发现,为了能够充分扩展防火墙的功能,因此使得防火墙在上,首先我们设了5个卡哨,其次每个卡哨上面它所实现的功能还不止一个,如在由本机内部报文发出的这个位置可以对其做过滤,即检查规则是否符合条件,如果符合,允许访问与不允许访问这叫过滤,或者是检查报文符不符合规则,如果符合规则把它的地址改一改这叫做地址转换,而过滤和地址转换是两种截然不同甚至是相去甚远的功能。因此这两种功能的链不能放在一起发挥作用,它们虽然都放在一个钩子上,但它们都属于两种不同的功能。这就意味着结果就成了在一个钩子上就有了两个链,每一个功能用一个链。而这两个功能到底谁先谁后呢?因此它们也应该有优先级关系,不过怎么讲,每一种功能都要单独的发挥完作用后才能让另外一个功能发挥作用。而每一个功能都可能有多条规则,那最终就是每一个钩子上就实现了多个行和多个列组成的表,ipchains就发展成了iptables,这就是iptables的由来。
所以从这个角度来讲,iptables之所以叫tables是因为它所实现的功能有很多。
iptables的功能:(可以理解成规则的分类)
注意:每一种功能它们都有可能需要在这5个钩子函数的某一个位置发挥作用;
- filter:过滤;最根本的功能,这是被称为防火墙的赖以生存的根本。
- nat:network address translation,网络地址转换;如果工作在网络地址转换这种模式的话,从这个角度讲,iptables这个主机更像是一个nat服务器。(nat是用来改源IP、源端口、目标IP、目标端口的)
- mangle:拆解报文,做出修改,封装报文;把一个报文拆开后,除了地址转换外,其它可转换的部分都可以拿来做修改。
- raw:关闭nat表上启用的连接追踪机制;是nat功能的一种补充;要想完成nat功能需要启动连接追踪功能才能进行做nat地址转换,而如果关闭了nat追踪机制的话,接下来可能在有些地方就会产生一些问题,所以raw功能用的并不是特别的多。
另外对于网络防火墙来讲,连接追踪功能是非常有用的功能。连接追踪就是能够去识别曾经访问过本主机或本网络的主机或报文的这样一种机制,即识别此前访问过本机或本网络的报文,对于我们的主机来说,如果要想能追踪每一个连接,那就需要建立一个非常庞大的追踪表才可以,对于一个非常繁忙的前端负载均衡服务器如果每一个连接都要做追踪的话,要想追踪连接就要将其记下来,记下来就需要内存空间,结果可能会导致内存空间溢出,一旦溢出,新的连接就不能进来了。因此为了追踪就需要记录,而新连接来了,记录下来了,那第一次访问都不允许了。所以对于非常繁忙的前端负载均衡服务器,连接追踪功能是万万不能开启的,如果不得不启用,准备好足够大的内存并且将连接追踪功能的所能够承受功能的调到足够大才可以。
5个钩子函数在iptables的名称空间当中,它有一种称呼分别是:(被称为5个内置的链)
- PREROUTING
- INPUT
- FORWARD
- OUTPUT
- POSTROUTING
报文刚刚到达本机后是发往本机内部还是经由本机转发的,需要作出判断,可以根据目标地址检查路由表来判断,这也就意味着接下来有一个路由功能要实现,即有一个路由选择的过程。而这个位置在路由选择发生之前就要完成,所以称为PREROUTING。
一旦PREROUTING结束了,报文就有两个走向,第一,要么是到本机内部,第二要么是经过本机转发。这两种情形,到本机内部有一个专门的钩子叫INPUT,经由本机转发称为FORWARD。
而对于一个网卡来讲,若将其当作是报文流出的接口,那报文要通过这个网卡流出时的来源有两种可能,第一种是转发而后出去的,第二种是由本机内部发出的。而本机内部发出的称为OUTPUT。
无论是由本地转发的还是经由本机内部发出的,将来它在离开本机之前需要再做一次路由选择,那就意味着路由选择发生以后要走哪条路就确定了。那第二次路由决策发生以后我们要对其做一些即将离开本机之前最后那一关再给它做一些处理,这就叫POSTROUTING,这是第二次路由决策发生以后用于做出处理的。
其实不管是PREROUTING也好,还是POSTROUTING也罢,其实它们跟网卡无关,从哪个网卡进来在路由发生之前都叫PREROUTING,无论即将通过哪个网卡离开,在路由决策发生以后都叫POSTROUTING。所以它们跟网卡是没有什么关系的,它们只是TCP/IP协议栈上的功能,可以从任意一个网卡离开,从任意一个网卡进来。
我们再想一个问题,如果说在这个FORWARD上,它既然是转发的,那么在这里添加规则的目的是什么呢?定义哪些可以转发,哪些不可以转发,那为什么转发时要做限制呢?这其实就是网络防火墙的意义了,iptables也可以用来扮演网络防火墙的角色,怎么扮演呢?把它的规则定义在FORWARD上,如果这个时候公司里只有一个主机或一根网线能够跟外部网络通信,然后把这个网线接到Linux主机上。内网所有主机都把这个Linux主机的内网网卡当网关,那就意味着所有的报文只要跟非本地网络的通信都要经过它,那我们就可以在它上面的访问列表上做好规则了,比如能访问或者不能访问QQ等等这一系列规则都可以在上面进行定义,而且我们对应哪些允许通过的主机都给它放行,哪些不允许通过的统统拒绝掉,那就能实现所谓的网络防火墙的功能了。
因此iptables可以扮演本地主机防火墙利用INPUT链、OUTPUT链即可,而又能扮演网络防火墙利用FORWARD链即可。
那么为什么需要硬件防火墙呢?所有内网的主机任何一个报文都经过本机跟非本地主机通信时就意味着每一个报文本机都要转发,因此转发的过程它要进行检测,效率会非常低,尤其是规则非常多时。还有一点就是iptables它的防火墙功能是在纯软件的基础上实现的,即便是内核级别实现它也是软件,有很多硬件防火墙它们的CPU在设计上在硬件级别就可以完成报文的拆分和封装。能让软件实现的好处在于可以改软件到达灵活修改的目的,但是硬件级别能实现的防火墙功能不需要软件参与,它的性能要好很多,所以有些硬件防火墙它能够将网络协议栈的本来是软件实现的某些功能基于硬件实现,从而大大提高了工作效率,而这个CPU通常都是专门设计的而且有特定架构,跟X86平台不是同一种架构。那既然是特定定制的又用于特殊目的的话通常代价非常昂贵,当然并不是硬件能完成所有功能,很多硬件防火墙一样需要在里面写规则,有些较高级的应用启动规则检查并且需要自己编辑添加规则了,不过它在较底层次上的某些报文处理功能的确在硬件层次上实现了,所以性能会非常高。
netfilter在内核中设置了5个参考点,而iptables为了能引用这5个参考点,我们可以通过PREROUTING、INPUT、FORWARD、OUTPUT、POSTROUTING来引用它们,而引用时用到的引用机制分为了4种不同的功能,每一个功能都可能会在这些链上来实现,如:filter会用到INPUT、FORWARD、OUTPUT,而mangle则会用到这5个。这就是为什么每一个链最终会成为iptables的原因,因为每一个链上都有可能添加n种功能的规则,每一种功能都叫做一个链,那多个链结合起来就相当于一个TABLE了。
总结报文流向以此来看如何写规则来完成真正防火墙的功能:
首先,所有报文大概就分为三种:
- 流入(当做进入本机内部的):所有流入的报文只要到了本机内部先通过PREROUTING,那PREROUTING发出后,随后但凡到达本机内部的会经由INPUT。PREROUTING --> INPUT
- 流出(当做本机发出的):OUTPUT --> POSTROUTING
- 转发(属于流出、流出的一种,由本机进来又由本机出去的):PREROUTING --> FORWARD --> POSTROUTING
所以流入、流出、转发它们所经由的位置不一样,这一点至关重要,因为我们添加规则时要打算对哪一种报文做检测那就在在它流经的位置上添加规则,如我们想不让某个报文出去在INPUT上没有任何作用,所以对于报文流入流出所经过的路径一定要做到心中有数,并且还需要在功能上对其作区分。
各功能的分别实现的位置:
filter:INPUT、FORWARD、OUTPUT
nat:PREROUTING(DNAT,目标地址转换)、OUTPUT(SNAT,源地址转换)、POSTROUTING(SNAT,源地址转换),在其它地方实现nat是没有必要也是不应该的而且就连OUTPUT都很少用,对我们来讲,实现地址转换通常只有两个链PREROUTING和POSTROUTING。
mangle:PREROUTING、INPUT、FORWARD、OUTPUT、POSTROUTING
raw:PREROUTING、OUTPUT
这样一来就意味着我们写规则时,第一既要先想明白使用的是什么功能,然后决定放在哪张表上,每个功能要有一张表,filter叫filter表,nat叫nat表,mangle叫mangle表;第二,还要明确的定义好我们应该放在对应表的哪个链(位置)上,要根据报文流经的方向来确定。
路由发生的时刻:
- 报文进入本机后:
判断目标主机(是否为本机);
- 报文发出之前:
判断经由哪个接口送往下一跳;
小结:
iptables一共有四表五链
添加规则的考量点:
(1) 要实现哪种功能(说白了就是做什么,是做过滤呢,还是做地址转换):判断添加在哪张表上;
(2) 报文流经的路径:判断添加在哪个链上;
我们说过在一个链上有n条规则,否则不能称之为链,那这些规则检查时自上而下进行检查,如果说某一规则匹配到了或生效了怎么办?其它还要不要做检查?我们如何重启这种检查机制?所以还需注意对于链而言,链上的规则次序即为检查的次序(所以这个次序就至关重要了);因此它内部隐含一定法则:
(1)同类规则(访问统一应用),匹配范围小的放上面;规则检查时自上而下的,而且有些规则是一旦被第一条规则处理了,往后就不再检查了,这就意味着效率提升了,如果每一次检查都是检查到最后,被最后一条规则匹配了,那前面的检查就白费了,那我们可以认为让那些尽可能越优先应该被匹配到的规则越往前放或者越有可能被匹配到的规则越往前放;
(2)不同类规则(访问不同应用),匹配到报文频率较大的放上面;
(3)将那些可由一条规则描述的多个规则合并为一个;
(4)设置默认策略;
白名单:默认为拒绝,只允许我们指定的访问;
黑名单:默认为允许,只拒绝那些我们明确指定的访问;
这两种名单中,白名单相对要安全的多,所以建议使用白名单
再考虑一个问题,在同一个钩子上有可能设置了多种不同功能的多个规则,于是形成了多个链,这多个链谁先发挥作用谁后发挥作用呢?是先做filter后做nat还是先做nat后做filter,这其实是由既定法则在里头的,规则生效是有既定次序的:

功能的优先级次序:raw --> mangle --> nat --> filter
规则:
报文匹配规则,真正发挥作用的既不是iptables本身也不是netfilter本身,而是我们添加进去的规则在发挥作用;
规则的组成部分(主要有两类):
- 报文的匹配条件(只有对那些能匹配到指定的规则条件的才能做处理)
- 匹配到之后的处理机制或动作
匹配条件:根据协议报文特征指定匹配条件
匹配条件的机制或编写格式:
-
- 基本匹配条件(只检查最根本的几项源IP、源端口之类的)
- 扩展匹配条件(想检查更严格一些,如:做连接追踪、转态追踪、甚至根据Mac地址做追踪、甚至能检查一些应用层的特性等等)
处理动作:(两种方式)
- 内建处理机制(如:以过滤功能为例,匹配到的就丢弃或拒绝)
- 自定义处理机制(自定义处理机制仅仅能够指明跳转目标,说白了就是可以自定义链匹配到后转到自定义的链上去。自定义的链不可能跟整个netfilter的某个钩子函数相对应,如PREROUTING就跟钩子函数PRETOUTING相对应,但自定义的链没办法对应,不对应的话报文就不可能流经指定的位置,那怎么办呢?没有办法,就只能在它必然流经的位置调用自定义的链)
注意:报文不会经过自定义链,因此自定义链要想发挥作用,只能在内置链上通过规则引用后生效;说白了就是通过自定义处理机制进行引用;