作者:ibless 来源:CSDN 原文:https://blog.csdn.net/ibless/article/details/80114009 其实 很早之前对这一块有了解 比较多的的是 CCNUMA 高速缓存一致性的 非一致性内存访问 需要在CPU之间架设高速缓存通路 这样才能提高相应的性能 AMD 最新的处理器架构 采取的CX 其实同一个物理插座上面的核 访问内存的延迟也不一样. 会出现掉速的现象.
通常,在业界存在两种主要类型的并行体系结构:共享内存体系结构(Shared Memory Architecture)和分布式内存体系结构(Distributed Memory Architecture)。而共享内存结构有两种类型:统一内存访问(UMA)和非同一内存访问(NUMA),有些博客中多一种只用高速缓存的存储器架构(Cache-Only Memory Architecture,简称COMA)。目前,三大商用服务器架构又分为SMP(对称多处理架构)、NUMA(非同一内存访问架构)、MMP(大规模并行处理架构)。本文先讲述UMA和NUMA,接下来的博客会陆续讲述SMP、MMP和NUMA的特点以及区别。
因为UMA和NUMA都是共享内存共享内存架构的并行体系机构,所以它们有一个相同点就是内存共享。共享内存,简单来说就是多个CPU可以访问系统中所有的内存。下图是共享内存的模型:
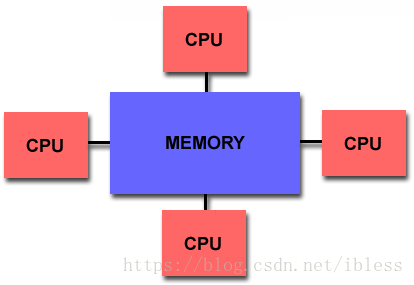
图1 共享内存架构
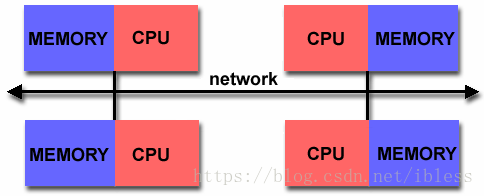
图2 分布式内存架构
接下来,我们先说一下UMA,在UMA中,内存访问时间取决于是哪个处理器发出的请求,或者哪个内存芯片包含传输的数据。下面是一张示意图:

在UMA中,所有的处理器平等的访问内存,因此CPU对内存的存取在速度上等是没有差异的,这也是称为统一内存访问的原因。各处理器与内存单元通过互联总线进行连接,各个CPU之间没有主从关系,其实SMP架构可以说成是UMA的。
下面我们来说一下NUMA架构,下图是NUMA架构的一个示例:

从上面的图中,我们可以看到一台计算机有多个Node(节点),每个节点中有多个Core(核),上图中是4个核,在每个节点内部都有自己的内存,称之为本地内存。与本地内存相对的是远端内存,对于Node0来说,Node1、Node2、Node3中的内存都是远端内存。在节点中,CPU与内存之间通过片内总线进行连接。各个节点之间通过互联模块(Crossbar Switch)进行连接。需要注意的是,NUMA节点中CPU对节点内部内存与节点外部内存的访问是有差异的。依旧是一个CPU对本地内存和远端内存的访问时间是不同的,一般来说,CPU对本地内存的时间要比远端内存的访问速度快1.3--5倍。这也就是称为NUMA(非统一内存访问)的原因。NUMA既然属于共享内存架构,也就是每个CPU都可以访问系统中所有的内存,只不过访问这些内存的速度或方式是有差异的。一般来说,NUMA节点之间是相互连接的,这个有一个Node Distance的概念,也就是节点与节点之间的距离是不同的。下图是一个获取Node Distance的截图:
参考:
https://en.wikipedia.org/wiki/Uniform_memory_access
https://en.wikipedia.org/wiki/Non-uniform_memory_access
http://cs.nyu.edu/~lerner/spring10/projects/NUMA.pdf
---------------------