spark中,slice=partition,一个slice对应一个task,启动task的数量上限取决于集群中核的数量
sc.parallelize(0 until numMappers, numMappers)中的numMappers就是slice的数量[1]
下面的图来自[3]
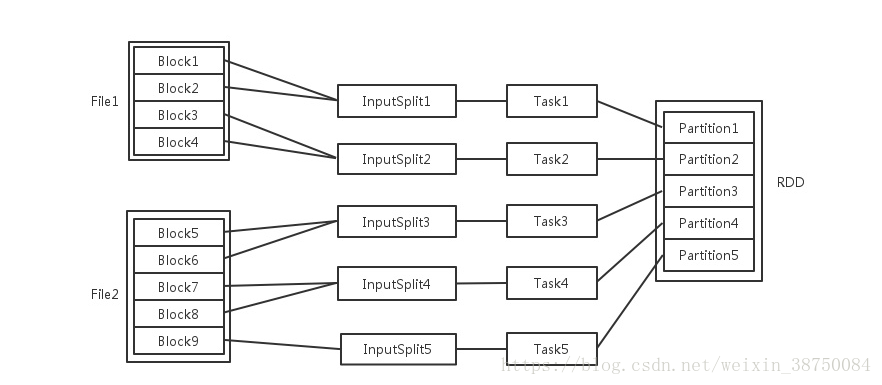
在spark调优中,增大RDD分区数目,可以增大任务并行度
map(function)
map是对RDD中的每个元素都执行一个指定的函数来产生一个新的RDD。
任何原RDD中的元素在新RDD中都有且只有一个元素与之对应。
scala> val a = sc.parallelize(1 to 9, 3)//这里的3表示的是把数据分成几份
a: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[2] at parallelize at <console>:24
scala> val b = a.map(x => x*2)
b: org.apache.spark.rdd.RDD[Int] = MapPartitionsRDD[3] at map at <console>:25
scala> a.collect
res1: Array[Int] = Array(1, 2, 3, 4, 5, 6, 7, 8, 9)
scala> b.collect
res2: Array[Int] = Array(2, 4, 6, 8, 10, 12, 14, 16, 18)
当然map也可以把Key变成Key-Value对
scala> val a = sc.parallelize(List("dog", "tiger", "lion", "cat", "panther", " eagle"), 2)
a: org.apache.spark.rdd.RDD[String] = ParallelCollectionRDD[4] at parallelize at <console>:24
scala> val b = a.map(x => (x, 1))
b: org.apache.spark.rdd.RDD[(String, Int)] = MapPartitionsRDD[5] at map at <console>:25
scala> b.collect.foreach(println(_))
(dog,1)
(tiger,1)
(lion,1)
(cat,1)
(panther,1)
( eagle,1)
mapPartitions(function)
map()的输入函数是应用于RDD中每个元素,
而mapPartitions()的输入函数是应用于每个Partition(一个RDD可以对应于多个Partition)
关于这个具体案例可以参见[4]
mapValues(function)
原RDD中的Key保持不变,与新的Value一起组成新的RDD中的元素。因此,该函数只适用于元素为KV对的RDD
scala> val a = sc.parallelize(List("dog", "tiger", "lion", "cat", "panther", " eagle"), 2)
a: org.apache.spark.rdd.RDD[String] = ParallelCollectionRDD[0] at parallelize at <console>:24
scala> val b = a.map(x => (x.length, x))
b: org.apache.spark.rdd.RDD[(Int, String)] = MapPartitionsRDD[1] at map at <console>:25
scala> b.mapValues("x" + _ + "x").collect
res0: Array[(Int, String)] = Array((3,xdogx), (5,xtigerx), (4,xlionx), (3,xcatx), (7,xpantherx), (6,x eaglex))
mapWith和flatMapWith
感觉用得不多,参考http://blog.csdn.net/jewes/article/details/39896301
flatMap(function)
与map类似,区别是原RDD中的元素经map处理后只能生成一个元素,而原RDD中的元素经flatmap处理后可生成多个元素
scala> val a = sc.parallelize(1 to 4, 2)
a: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[3] at parallelize at <console>:24
scala> val b = a.flatMap(x => 1 to x)
b: org.apache.spark.rdd.RDD[Int] = MapPartitionsRDD[4] at flatMap at <console>:25
scala> b.collect
res1: Array[Int] = Array(1,
1, 2,
1, 2, 3,
1, 2, 3, 4)
注意,上面的flatMap中的字符串,其实是一个函数
flatMapValues(function)
scala> val a = sc.parallelize(List((1,2),(3,4),(5,6)))
a: org.apache.spark.rdd.RDD[(Int, Int)] = ParallelCollectionRDD[7] at parallelize at <console>:24
scala> val b = a.flatMapValues(x=>1 to x)
b: org.apache.spark.rdd.RDD[(Int, Int)] = MapPartitionsRDD[8] at flatMapValues at <console>:25
scala> b.collect.foreach(println(_))
(1,1)
(1,2)
(3,1)
(3,2)
(3,3)
(3,4)
(5,1)
(5,2)
(5,3)
(5,4)
(5,5)
(5,6)
参考链接:
[1]https://blog.csdn.net/robbyo/article/details/50623339
[2]https://blog.csdn.net/guotong1988/article/details/50555185
[3]https://blog.csdn.net/weixin_38750084/article/details/83021819
[4]https://blog.csdn.net/appleyuchi/article/details/88371867