目录
2. 反卷积(tf.nn.conv2d_transpose)
1.定义
1.1 卷积运算的定义
所谓卷积,其实是一种数学运算。但是在我们的学习生涯中,往往它都是披上了一层外衣,使得我们经常知其然不知其所以然。比如在信号系统中,他是以一维卷积的形式出现描述系统脉冲响应。又比如在图像处理中,他是以二维卷积的形式出现,可以对图像进行模糊处理。乍一看,两个形式风马牛不相及,但其实他们的本质都是统一的。可见,我们看待事物不仅要看他们的表象,还要从表象中分辨出他们的本质。下面进入正题。
卷积网络,也叫卷积神经网络(CNN),是一种专门依赖处理具有类似网络结构的数据的神经网络。卷积是一种特殊的线性运算。卷积网络是指那些至少在网络的一层中使用卷积运算来代替一般的矩阵乘法运算的神经网络。
卷积运算,在通常形式中,卷积是对两个变体函数的一种数学运算数据是。卷积运算对输入数据应用滤波器,例子:输入数据是有高长方向的形状的数据,滤波器也一样,有高长方向上的维度,假设用height,weight,表示数据和滤波器的形状,“核”又称滤波器。卷积运算以一定间隔滑动滤波器的窗口并应用,将各个位置上的滤波器的元素 和输入的对应元素相乘,然后现求和(有时这个运算称为乘积累积运算),然后,将这个结果保存到输出的对应位,将这个过程在所有位置都进行一遍,就可以得到卷积运算的输出。
1.2 动机(稀疏权重、参数共享、等变表示)
卷积运算通过三个重要的思想来帮助改进机器学习系统:稀疏交互、参数共享、等变表示。另外,卷积提供了一种处理大小可变的输入的方法。卷积网络具有稀疏交互(也叫稀疏连接或者稀疏权重)的特征。
1.2.1 稀疏连接
传统神经网络使用矩阵乘法建立输入与输出的连接关系。参数矩阵的每一个单独的参数都描述了一个输入单元与一个输出单元间的交互。卷积网络通过使核的大小远小于输入的大小来达到稀疏连接的目的。
如果有m个输入和n个输出,矩阵乘法需要m*n个参数。如果限制每一个输出拥有的连接数为k,那么稀疏的连接方法只需k*n个参数。
1.2.2 参数共享
参数共享是指在一个模型的多个函数中使用相同的参数。在卷积网络中,核的每一个元素都作用在输入的每一个位置上。
1.2.3 等变表示
对于卷积,参数共享的特殊形式使得神经网络具有对平移等变的性质。如果一个函数满足输入改变,输出也以同样的方式改变,就说它是等变的。 卷积对其他的一些变换并不是天然等变的,例如对于图像的放缩或旋转变换,需要其他的机制来处理这些变换。
1.3 一维卷积运算和二维卷积运算
1.3.1 一维卷积
在这个部分,我们主要从数学的角度看一看卷积,也就是看一下卷积是怎么运算的。这里要说明一下,卷积分为连续卷积和离散卷积。在此为了方便大家理解,在此先以离散卷积举例,本文也就不再专门讨论连续卷积(因为连续卷积和离散卷积的区别也就是连续和离散的区别,找时间我会总结一下连续和离散的异同)。说到数学角度,那首先就要给出卷积运算的公式定义:
这个公式中有三个序列(y,h,u),其中h长度为lh=3,u的长度为lu=6。那么就有y的长度ly=lh+lu-1=8(至于为什么后面会说)。如何计算这个卷积呢?我们先将一个序列从小到大排列(U0,U1,U2,U3,U4,U5)在一维直线上,因为公式中U的序号i是从小到大。而将H序列从大到小排列(H2,H1,H0),因为H的序号是-i。再将两个序列的开头对齐,如下图:
排列好之后,我们就可以开始进行卷积运算。当位移K=0时,下面H序列不移动,上下两个序列中都存在的项相乘后相加,即y(0)=H0*U0。当位移K=1时,下面H序列移动1位,之后对应项相乘后相加得到y(1)=H1*U0+H0*U1。依此移动,直到取到K的最大值停止。可见,一维卷积就是卷积核H,在被卷积信号U的一维直线上的移动之后的对应项相乘后求和运算。那么K的取值范围时多少呢?从图中我们可以看出当K=8时,H序列和U序列对应项都不存在了,那么K=8也就没有意义。因此的最大长度要使得两个序列至少有1个项重合,即两个序列长度求和再减去重合的一项的长度。
1.3.2 多维卷积
我们还是先从简单的入手,以二维卷积为例。二维卷积的公式如下:
此时,三个序列(y,h,u)都是双下标的序列。在一维卷积中,我们将U展开在一维直线上。那么对于二维卷积运算,我们就将U展开在二维平面中,左下角为U(0,0),右上角为U(5,5)。同样的,将H也展开在二维平面中,同时要与U的方向相反,左下角H(2,2),右上角为H(0,0)。如下图所示:
同样,二维卷积中p,q的长度也是由H和U序列长度所决定的,即Lp=Lux+Lhx-1,Lq=Luy+Lhy-1。二维卷积运算就是卷积核H,在被卷积信号U的平面上的对应项相乘后求和运算。那么对于更高维的卷积运算,同样可以按照该方法理解。相信大家读到这里,可以理解不同维卷积的统一性。
特别注意:
1.卷积后的序号k,q,p其实表示的是两个卷积序列的相对位置关系,也就是与被卷积信号的坐标不相同。
2.卷积的两个信号的坐标既可以是时间坐标也可以是空间的坐标,甚至是时空坐标。只不过,如果是时间坐标,注意坐标不可为负。
2. 反卷积(tf.nn.conv2d_transpose)
2.1 卷积
这里提到的反卷积跟1维信号处理的反卷积计算是很不一样的,我们可以知道,在CNN中有con layer与pool layer,con layer进行对图像卷积提取特征,pool layer对图像缩小一半筛选重要特征,对于经典的图像识别CNN网络,如IMAGENET,最后输出结果是1X1X1000,1000是类别种类,1x1得到的是。这里图像的反卷积与图6的full卷积原理是一样的,使用了这一种反卷积手段使得图像可以变大,FCN作者使用的方法是这里所说反卷积的一种变体,这样就可以获得相应的像素值,图像可以实现end to end。
卷积层定义如下:
二维的离散卷积(N=2)
方形的特征输入()
方形的卷积核尺寸()
每个维度相同的步长()
每个维度相同的padding()
下图表示参数i=5,k=3,s=2,p=1的卷积过程,从计算结果可以看出输出的特征的尺寸大小o1=o2=o=3;i=6,k=3,s=2,p=1的卷积过程,从计算结果可以看出输出特征为o1=o2=o=3.


两个例子可以总结出卷积层与输出的特征尸寸和卷积核参数的关系为:
2.2 反卷积(后卷积,转置卷积)
二维的离散卷积N=2
方形的特征输入
方形的卷积核
每个维度相同的步长
每个维度相同的padding
下图参数为i'=2,k'=3,s'=1,p'=2的反卷积,其对应的卷积操作为i = 4,k=3,s=1,p=0。可以发现对应卷积和非卷积其k=k',s=s'但是反卷积却多了p'=2,通过对比发现卷积中左上角的输入只对左上角的输出有贡献,所以反卷积层会出现p' = k-p-1=2。从图中可以发现,反卷积的输入输出在s=s'=1的情况下关系为:o'=i'-k'+2p'+1 = i'+(k-1)-2p

2.3 代码实现(tf.conv2d_transpose,tf.conv3d_transpose)
我先解释一下必要信息:
tf.conv2d_transpose(value, filter, output_shape, strides, padding="SAME", data_format="NHWC", name=None)
除去name参数用以指定该操作的name,与方法有关的一共六个参数:
第一个参数value:指需要做反卷积的输入图像,它要求是一个Tensor
第二个参数filter:卷积核,它要求是一个Tensor,具有[filter_height, filter_width, out_channels, in_channels]这样的shape,具体含义是[卷积核的高度,卷积核的宽度,卷积核个数,图像通道数]
第三个参数output_shape:反卷积操作输出的shape,细心的同学会发现卷积操作是没有这个参数的.
第四个参数strides:反卷积时在图像每一维的步长,这是一个一维的向量,长度4
第五个参数padding:string类型的量,只能是"SAME","VALID"其中之一,这个值决定了不同的卷积方式
第六个参数data_format:string类型的量,'NHWC'和'NCHW'其中之一,这是tensorflow新版本中新加的参数,它说明了value参数的数据格式。'NHWC'指tensorflow标准的数据格式[batch, height, width, in_channels],'NCHW'指Theano的数据格式,[batch, in_channels,height, width],当然默认值是'NHWC'
input_shape = [1,5,5,3]
kernel_shape=[2,2,3,1]
strides=[1,2,2,1]
padding = "SAME"
out_shape 结果应该是什么,应该是[1,3,3,1] 只有一个通道的3*3的图片,
然后我们就对它进行反向操作,注意哪方面不同:然后输出的y就是最上面的input_shape,我想到了一个很合理的方法就是这样定制你的反卷积网络,也即是你在进行反卷积之前,你要推算一下正向卷积所需要的路径,然后把正向卷积所需要的kernel,和strides写入tf.conv2d_transpose()函数就行了,当然输入和输出要互相对换一下就行了,
import tensorflow as tf
tf.set_random_seed(1)
x = tf.random_normal(shape=[1, 3, 3, 1]) # 正向卷积的结果,要作为反向卷积的输出
kernel = tf.random_normal(shape=[2, 2, 3, 1]) # 正向卷积的kernel的模样
# strides 和padding也是假想中 正向卷积的模样。
y = tf.nn.conv2d_transpose(x, kernel, output_shape=[1, 5, 5, 3],
strides=[1, 2, 2, 1], padding="SAME")
# 在这里,output_shape=[1,6,6,3]也可以,考虑正向过程,[1,6,6,3]时,然后通过
# kernel_shape:[2,2,3,1],strides:[1,2,2,1]也可以
# 获得x_shape:[1,3,3,1]。
# output_shape 也可以是一个 tensor
sess = tf.Session()
tf.global_variables_initializer().run(session=sess)import tensorflow as tf
kernel1 = tf.constant(1.0, shape=[3, 3, 3, 512, 512]) # 正向卷积核
kernel2 = tf.constant(1.0, shape=[3, 3, 3, 512, 512]) # 反向卷积核
x3 = tf.constant(1.0, shape=[10, 2, 7, 7, 512]) # 正向卷积输入
y2 = tf.nn.conv3d(x3, kernel1, strides=[1, 1, 1, 1, 1], padding="SAME") # 正向卷积
pool = tf.nn.max_pool3d(y2, ksize=[1, 2, 2, 2, 1], strides=[1, 2, 2, 2, 1], padding='SAME') # 池化
sess = tf.Session()
sess.run(tf.global_variables_initializer())
sess.run(pool)
print(pool.shape) # (10,1,4,4,512)
# 反向卷积
y3 = tf.nn.conv3d_transpose(pool, kernel2, output_shape=[10, 2, 7, 7, 512], strides=[1, 2, 2, 2, 1], padding="SAME")
sess.run(y3)
print(y3.shape) # (10,2,7,7,512)

3. 池化运算的定义、种类(最大池化、平均池化等)
3.1 池化作用
池化是缩小高、长方向上的空间的运算。pooling的结果是使得特征减少,参数减少,但pooling的目的并不仅在于此。pooling目的是为了保持某种不变性(旋转、平移、伸缩等)。
3.2 池化分类
常用的有mean-pooling,max-pooling和Stochastic-pooling三种。mean-pooling,即对邻域内特征点只求平均,max-pooling,即对邻域内特征点取最大。根据相关理论,特征提取的误差主要来自两个方面:(1)邻域大小受限造成的估计值方差增大;(2)卷积层参数误差造成估计均值的偏移。
mean-pooling能减小第一种误差(邻域大小受限造成的估计值方差增大),更多的保留图像的背景信息,
max-pooling能减小第二种误差(卷积层参数误差造成估计均值的偏移),更多的保留纹理信息。
Stochastic-pooling则介于两者之间,通过对像素点按照数值大小赋予概率,再按照概率进行亚采样,在平均意义上,与mean-pooling近似,在局部意义上,则服从max-pooling的准则。
4. Text-CNN、Text-RNN的原理
CNN的核心点在于可以捕获信息的局部相关性,具体到文本分类任务中可以利用CNN来提取句子中类似N-Gram的关键信息。
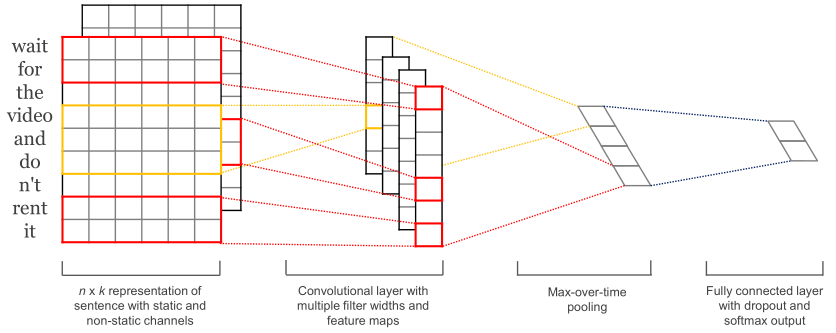
[1]一维卷积:使用不同尺寸的kernel_size来模拟语言模型中的N-Gram,提取句子中的信息。即TextCNN中的卷积用的是一维卷积,通过不同kernel_size的滤波器获取不同宽度的视野。
[2]词向量:static的方式采用预训练的词向量,训练过程不更新词向量,本质就是迁移学习,主要用于数据量比较小的情况。not-static的方式是在训练过程中更新词向量。推荐的方式是not-static的fine-tunning方式,它是以预训练的词向量进行初始化,训练过程中调整词向量。在工程实践中,通常使用字嵌入的方式也能得到非常不错的效果,这样就避免了中文分词。
[3]最大池化:TextCNN中的池化保留的是Top-1最大信息,但是可能保留Top-K最大信息更有意义。比如,在情感分析场景中,“我觉得这个地方景色还不错,但是人也实在太多了”,这句话前半部分表达的情感是正向的,后半部分表达的情感是负向的,显然保留Top-K最大信息能够很好的捕获这类信息。
TextCNN擅长捕获更短的序列信息,但是TextRNN擅长捕获更长的序列信息。具体到文本分类任务中,BiLSTM从某种意义上可以理解为可以捕获变长且双向的N-Gram信息。
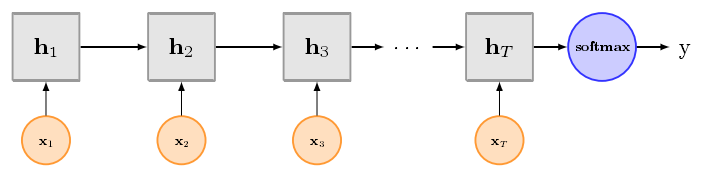
将CNN和RNN用在文本分类中都能取得显著的效果,但是有一个不错的地方就是可解释性不好,特别是去分析错误案例的时候,而注意力机制[Attention]能够很好的给出每个词对结果的贡献程度,已经成为Seq2Seq模型的标配,实际上文本分类也可以理解为一种特殊的Seq2Seq模型。因此,注意力机制的引入,可以在某种程度上提高深度学习文本分类模型的可解释性。
5. 利用Text-CNN模型来进行文本分类
Text-CNN-train.py
import tensorflow as tf
import numpy as np
from p7_TextCNN_model import TextCNN
from data_util import create_vocabulary,load_data_multilabel
import os
import word2vec
#configuration
FLAGS=tf.app.flags.FLAGS
tf.app.flags.DEFINE_string("traning_data_path","../data/sample_multiple_label.txt","path of traning data.") #sample_multiple_label.txt-->train_label_single100_merge
tf.app.flags.DEFINE_integer("vocab_size",100000,"maximum vocab size.")
tf.app.flags.DEFINE_float("learning_rate",0.0003,"learning rate")
tf.app.flags.DEFINE_integer("batch_size", 64, "Batch size for training/evaluating.") #批处理的大小 32-->128
tf.app.flags.DEFINE_integer("decay_steps", 1000, "how many steps before decay learning rate.") #6000批处理的大小 32-->128
tf.app.flags.DEFINE_float("decay_rate", 1.0, "Rate of decay for learning rate.") #0.65一次衰减多少
tf.app.flags.DEFINE_string("ckpt_dir","text_cnn_title_desc_checkpoint/","checkpoint location for the model")
tf.app.flags.DEFINE_integer("sentence_len",100,"max sentence length")
tf.app.flags.DEFINE_integer("embed_size",128,"embedding size")
tf.app.flags.DEFINE_boolean("is_training",True,"is traning.true:tranining,false:testing/inference")
tf.app.flags.DEFINE_integer("num_epochs",10,"number of epochs to run.")
tf.app.flags.DEFINE_integer("validate_every", 1, "Validate every validate_every epochs.") #每10轮做一次验证
tf.app.flags.DEFINE_boolean("use_embedding",False,"whether to use embedding or not.")
tf.app.flags.DEFINE_integer("num_filters", 128, "number of filters") #256--->512
tf.app.flags.DEFINE_string("word2vec_model_path","word2vec-title-desc.bin","word2vec's vocabulary and vectors")
tf.app.flags.DEFINE_string("name_scope","cnn","name scope value.")
tf.app.flags.DEFINE_boolean("multi_label_flag",True,"use multi label or single label.")
filter_sizes=[6,7,8]
#1.load data(X:list of lint,y:int). 2.create session. 3.feed data. 4.training (5.validation) ,(6.prediction)
def main(_):
trainX, trainY, testX, testY = None, None, None, None
vocabulary_word2index, vocabulary_index2word, vocabulary_label2index, vocabulary_index2label= create_vocabulary(FLAGS.traning_data_path,FLAGS.vocab_size,name_scope=FLAGS.name_scope)
vocab_size = len(vocabulary_word2index);print("cnn_model.vocab_size:",vocab_size);num_classes=len(vocabulary_index2label);print("num_classes:",num_classes)
train, test= load_data_multilabel(FLAGS.traning_data_path,vocabulary_word2index, vocabulary_label2index,FLAGS.sentence_len)
trainX, trainY = train
testX, testY = test
#print some message for debug purpose
print("length of training data:",len(trainX),";length of validation data:",len(testX))
print("trainX[0]:", trainX[0]);
print("trainY[0]:", trainY[0])
train_y_short = get_target_label_short(trainY[0])
print("train_y_short:", train_y_short)
#2.create session.
config=tf.ConfigProto()
config.gpu_options.allow_growth=True
with tf.Session(config=config) as sess:
#Instantiate Model
textCNN=TextCNN(filter_sizes,FLAGS.num_filters,num_classes, FLAGS.learning_rate, FLAGS.batch_size, FLAGS.decay_steps,
FLAGS.decay_rate,FLAGS.sentence_len,vocab_size,FLAGS.embed_size,FLAGS.is_training,multi_label_flag=FLAGS.multi_label_flag)
#Initialize Save
saver=tf.train.Saver()
if os.path.exists(FLAGS.ckpt_dir+"checkpoint"):
print("Restoring Variables from Checkpoint.")
saver.restore(sess,tf.train.latest_checkpoint(FLAGS.ckpt_dir))
#for i in range(3): #decay learning rate if necessary.
# print(i,"Going to decay learning rate by half.")
# sess.run(textCNN.learning_rate_decay_half_op)
else:
print('Initializing Variables')
sess.run(tf.global_variables_initializer())
if FLAGS.use_embedding: #load pre-trained word embedding
assign_pretrained_word_embedding(sess, vocabulary_index2word, vocab_size, textCNN,FLAGS.word2vec_model_path)
curr_epoch=sess.run(textCNN.epoch_step)
#3.feed data & training
number_of_training_data=len(trainX)
batch_size=FLAGS.batch_size
iteration=0
for epoch in range(curr_epoch,FLAGS.num_epochs):
loss, counter = 0.0, 0
for start, end in zip(range(0, number_of_training_data, batch_size),range(batch_size, number_of_training_data, batch_size)):
iteration=iteration+1
if epoch==0 and counter==0:
print("trainX[start:end]:",trainX[start:end])
feed_dict = {textCNN.input_x: trainX[start:end],textCNN.dropout_keep_prob: 0.5,textCNN.iter: iteration,textCNN.tst: not FLAGS.is_training}
if not FLAGS.multi_label_flag:
feed_dict[textCNN.input_y] = trainY[start:end]
else:
feed_dict[textCNN.input_y_multilabel]=trainY[start:end]
curr_loss,lr,_,_=sess.run([textCNN.loss_val,textCNN.learning_rate,textCNN.update_ema,textCNN.train_op],feed_dict)
loss,counter=loss+curr_loss,counter+1
if counter %50==0:
print("Epoch %d\tBatch %d\tTrain Loss:%.3f\tLearning rate:%.5f" %(epoch,counter,loss/float(counter),lr))
if start%(2000*FLAGS.batch_size)==0: # eval every 3000 steps.
eval_loss, f1_score, precision, recall = do_eval(sess, textCNN, testX, testY,iteration)
print("Epoch %d Validation Loss:%.3f\tF1 Score:%.3f\tPrecision:%.3f\tRecall:%.3f" % (epoch, eval_loss, f1_score, precision, recall))
# save model to checkpoint
save_path = FLAGS.ckpt_dir + "model.ckpt"
saver.save(sess, save_path, global_step=epoch)
#epoch increment
print("going to increment epoch counter....")
sess.run(textCNN.epoch_increment)
# 4.validation
print(epoch,FLAGS.validate_every,(epoch % FLAGS.validate_every==0))
if epoch % FLAGS.validate_every==0:
eval_loss,f1_score,precision,recall=do_eval(sess,textCNN,testX,testY,iteration)
print("Epoch %d Validation Loss:%.3f\tF1 Score:%.3f\tPrecision:%.3f\tRecall:%.3f" % (epoch,eval_loss,f1_score,precision,recall))
#save model to checkpoint
save_path=FLAGS.ckpt_dir+"model.ckpt"
saver.save(sess,save_path,global_step=epoch)
# 5.最后在测试集上做测试,并报告测试准确率 Test
test_loss,_,_,_ = do_eval(sess, textCNN, testX, testY,iteration)
print("Test Loss:%.3f" % ( test_loss))
pass
# 在验证集上做验证,报告损失、精确度
def do_eval(sess,textCNN,evalX,evalY,iteration):
number_examples=len(evalX)
eval_loss,eval_counter,eval_f1_score,eval_p,eval_r=0.0,0,0.0,0.0,0.0
batch_size=1
for start,end in zip(range(0,number_examples,batch_size),range(batch_size,number_examples,batch_size)):
feed_dict = {textCNN.input_x: evalX[start:end], textCNN.input_y_multilabel:evalY[start:end],textCNN.dropout_keep_prob: 1.0,textCNN.iter: iteration,textCNN.tst: True}
curr_eval_loss, logits= sess.run([textCNN.loss_val,textCNN.logits],feed_dict)#curr_eval_acc--->textCNN.accuracy
label_list_top5 = get_label_using_logits(logits[0])
f1_score,p,r=compute_f1_score(list(label_list_top5), evalY[start:end][0])
eval_loss,eval_counter,eval_f1_score,eval_p,eval_r=eval_loss+curr_eval_loss,eval_counter+1,eval_f1_score+f1_score,eval_p+p,eval_r+r
return eval_loss/float(eval_counter),eval_f1_score/float(eval_counter),eval_p/float(eval_counter),eval_r/float(eval_counter)
def compute_f1_score(label_list_top5,eval_y):
"""
compoute f1_score.
:param logits: [batch_size,label_size]
:param evalY: [batch_size,label_size]
:return:
"""
num_correct_label=0
eval_y_short=get_target_label_short(eval_y)
for label_predict in label_list_top5:
if label_predict in eval_y_short:
num_correct_label=num_correct_label+1
#P@5=Precision@5
num_labels_predicted=len(label_list_top5)
all_real_labels=len(eval_y_short)
p_5=num_correct_label/num_labels_predicted
#R@5=Recall@5
r_5=num_correct_label/all_real_labels
f1_score=2.0*p_5*r_5/(p_5+r_5+0.000001)
return f1_score,p_5,r_5
def get_target_label_short(eval_y):
eval_y_short=[] #will be like:[22,642,1391]
for index,label in enumerate(eval_y):
if label>0:
eval_y_short.append(index)
return eval_y_short
#get top5 predicted labels
def get_label_using_logits(logits,top_number=5):
index_list=np.argsort(logits)[-top_number:]
index_list=index_list[::-1]
return index_list
#统计预测的准确率
def calculate_accuracy(labels_predicted, labels,eval_counter):
label_nozero=[]
#print("labels:",labels)
labels=list(labels)
for index,label in enumerate(labels):
if label>0:
label_nozero.append(index)
if eval_counter<2:
print("labels_predicted:",labels_predicted," ;labels_nozero:",label_nozero)
count = 0
label_dict = {x: x for x in label_nozero}
for label_predict in labels_predicted:
flag = label_dict.get(label_predict, None)
if flag is not None:
count = count + 1
return count / len(labels)
def assign_pretrained_word_embedding(sess,vocabulary_index2word,vocab_size,textCNN,word2vec_model_path):
print("using pre-trained word emebedding.started.word2vec_model_path:",word2vec_model_path)
word2vec_model = word2vec.load(word2vec_model_path, kind='bin')
word2vec_dict = {}
for word, vector in zip(word2vec_model.vocab, word2vec_model.vectors):
word2vec_dict[word] = vector
word_embedding_2dlist = [[]] * vocab_size # create an empty word_embedding list.
word_embedding_2dlist[0] = np.zeros(FLAGS.embed_size) # assign empty for first word:'PAD'
bound = np.sqrt(6.0) / np.sqrt(vocab_size) # bound for random variables.
count_exist = 0;
count_not_exist = 0
for i in range(1, vocab_size): # loop each word
word = vocabulary_index2word[i] # get a word
embedding = None
try:
embedding = word2vec_dict[word] # try to get vector:it is an array.
except Exception:
embedding = None
if embedding is not None: # the 'word' exist a embedding
word_embedding_2dlist[i] = embedding;
count_exist = count_exist + 1 # assign array to this word.
else: # no embedding for this word
word_embedding_2dlist[i] = np.random.uniform(-bound, bound, FLAGS.embed_size);
count_not_exist = count_not_exist + 1 # init a random value for the word.
word_embedding_final = np.array(word_embedding_2dlist) # covert to 2d array.
word_embedding = tf.constant(word_embedding_final, dtype=tf.float32) # convert to tensor
t_assign_embedding = tf.assign(textCNN.Embedding,word_embedding) # assign this value to our embedding variables of our model.
sess.run(t_assign_embedding);
print("word. exists embedding:", count_exist, " ;word not exist embedding:", count_not_exist)
print("using pre-trained word emebedding.ended...")
if __name__ == "__main__":
tf.app.run()TextCNN_model.py
import tensorflow as tf
import numpy as np
class TextCNN:
def __init__(self, filter_sizes,num_filters,num_classes, learning_rate, batch_size, decay_steps, decay_rate,sequence_length,vocab_size,embed_size,
is_training,initializer=tf.random_normal_initializer(stddev=0.1),multi_label_flag=False,clip_gradients=5.0,decay_rate_big=0.50):
"""init all hyperparameter here"""
# set hyperparamter
self.num_classes = num_classes
self.batch_size = batch_size
self.sequence_length=sequence_length
self.vocab_size=vocab_size
self.embed_size=embed_size
self.is_training=is_training
self.learning_rate = tf.Variable(learning_rate, trainable=False, name="learning_rate")#ADD learning_rate
self.learning_rate_decay_half_op = tf.assign(self.learning_rate, self.learning_rate * decay_rate_big)
self.filter_sizes=filter_sizes # it is a list of int. e.g. [3,4,5]
self.num_filters=num_filters
self.initializer=initializer
self.num_filters_total=self.num_filters * len(filter_sizes) #how many filters totally.
self.multi_label_flag=multi_label_flag
self.clip_gradients = clip_gradients
# add placeholder (X,label)
self.input_x = tf.placeholder(tf.int32, [None, self.sequence_length], name="input_x") # X
#self.input_y = tf.placeholder(tf.int32, [None,],name="input_y") # y:[None,num_classes]
self.input_y_multilabel = tf.placeholder(tf.float32,[None,self.num_classes], name="input_y_multilabel") # y:[None,num_classes]. this is for multi-label classification only.
self.dropout_keep_prob=tf.placeholder(tf.float32,name="dropout_keep_prob")
self.iter = tf.placeholder(tf.int32) #training iteration
self.tst=tf.placeholder(tf.bool)
self.global_step = tf.Variable(0, trainable=False, name="Global_Step")
self.epoch_step=tf.Variable(0,trainable=False,name="Epoch_Step")
self.epoch_increment=tf.assign(self.epoch_step,tf.add(self.epoch_step,tf.constant(1)))
self.b1 = tf.Variable(tf.ones([self.num_filters]) / 10)
self.b2 = tf.Variable(tf.ones([self.num_filters]) / 10)
self.decay_steps, self.decay_rate = decay_steps, decay_rate
self.instantiate_weights()
self.logits = self.inference() #[None, self.label_size]. main computation graph is here.
self.possibility=tf.nn.sigmoid(self.logits)
if not is_training:
return
if multi_label_flag:print("going to use multi label loss.");self.loss_val = self.loss_multilabel()
else:print("going to use single label loss.");self.loss_val = self.loss()
self.train_op = self.train()
if not self.multi_label_flag:
self.predictions = tf.argmax(self.logits, 1, name="predictions") # shape:[None,]
print("self.predictions:", self.predictions)
correct_prediction = tf.equal(tf.cast(self.predictions,tf.int32), self.input_y) #tf.argmax(self.logits, 1)-->[batch_size]
self.accuracy =tf.reduce_mean(tf.cast(correct_prediction, tf.float32), name="Accuracy") # shape=()
def instantiate_weights(self):
"""define all weights here"""
with tf.name_scope("embedding"): # embedding matrix
self.Embedding = tf.get_variable("Embedding",shape=[self.vocab_size, self.embed_size],initializer=self.initializer) #[vocab_size,embed_size] tf.random_uniform([self.vocab_size, self.embed_size],-1.0,1.0)
self.W_projection = tf.get_variable("W_projection",shape=[self.num_filters_total, self.num_classes],initializer=self.initializer) #[embed_size,label_size]
self.b_projection = tf.get_variable("b_projection",shape=[self.num_classes]) #[label_size] #ADD 2017.06.09
def inference(self):
"""main computation graph here: 1.embedding-->2.CONV-BN-RELU-MAX_POOLING-->3.linear classifier"""
# 1.=====>get emebedding of words in the sentence
self.embedded_words = tf.nn.embedding_lookup(self.Embedding,self.input_x)#[None,sentence_length,embed_size]
self.sentence_embeddings_expanded=tf.expand_dims(self.embedded_words,-1) #[None,sentence_length,embed_size,1). expand dimension so meet input requirement of 2d-conv
# 2.=====>loop each filter size. for each filter, do:convolution-pooling layer(a.create filters,b.conv,c.apply nolinearity,d.max-pooling)--->
# you can use:tf.nn.conv2d;tf.nn.relu;tf.nn.max_pool; feature shape is 4-d. feature is a new variable
pooled_outputs = []
for i,filter_size in enumerate(self.filter_sizes):
with tf.name_scope("convolution-pooling-%s" %filter_size):
# ====>a.create filter
filter=tf.get_variable("filter-%s"%filter_size,[filter_size,self.embed_size,1,self.num_filters],initializer=self.initializer)
# ====>b.conv operation: conv2d===>computes a 2-D convolution given 4-D `input` and `filter` tensors.
#Conv.Input: given an input tensor of shape `[batch, in_height, in_width, in_channels]` and a filter / kernel tensor of shape `[filter_height, filter_width, in_channels, out_channels]`
#Conv.Returns: A `Tensor`. Has the same type as `input`.
# A 4-D tensor. The dimension order is determined by the value of `data_format`, see below for details.
#1)each filter with conv2d's output a shape:[1,sequence_length-filter_size+1,1,1];2)*num_filters--->[1,sequence_length-filter_size+1,1,num_filters];3)*batch_size--->[batch_size,sequence_length-filter_size+1,1,num_filters]
#input data format:NHWC:[batch, height, width, channels];output:4-D
conv=tf.nn.conv2d(self.sentence_embeddings_expanded, filter, strides=[1,1,1,1], padding="VALID",name="conv") #shape:[batch_size,sequence_length - filter_size + 1,1,num_filters]
conv,self.update_ema=self.batchnorm(conv,self.tst, self.iter, self.b1)
# ====>c. apply nolinearity
b=tf.get_variable("b-%s"%filter_size,[self.num_filters]) #ADD 2017-06-09
h=tf.nn.relu(tf.nn.bias_add(conv,b),"relu") #shape:[batch_size,sequence_length - filter_size + 1,1,num_filters]. tf.nn.bias_add:adds `bias` to `value`
# ====>. max-pooling. value: A 4-D `Tensor` with shape `[batch, height, width, channels]
# ksize: A list of ints that has length >= 4. The size of the window for each dimension of the input tensor.
# strides: A list of ints that has length >= 4. The stride of the sliding window for each dimension of the input tensor.
pooled=tf.nn.max_pool(h, ksize=[1,self.sequence_length-filter_size+1,1,1], strides=[1,1,1,1], padding='VALID',name="pool")#shape:[batch_size, 1, 1, num_filters].max_pool:performs the max pooling on the input.
pooled_outputs.append(pooled)
# 3.=====>combine all pooled features, and flatten the feature.output' shape is a [1,None]
#e.g. >>> x1=tf.ones([3,3]);x2=tf.ones([3,3]);x=[x1,x2]
# x12_0=tf.concat(x,0)---->x12_0' shape:[6,3]
# x12_1=tf.concat(x,1)---->x12_1' shape;[3,6]
self.h_pool=tf.concat(pooled_outputs,3) #shape:[batch_size, 1, 1, num_filters_total]. tf.concat=>concatenates tensors along one dimension.where num_filters_total=num_filters_1+num_filters_2+num_filters_3
self.h_pool_flat=tf.reshape(self.h_pool,[-1,self.num_filters_total]) #shape should be:[None,num_filters_total]. here this operation has some result as tf.sequeeze().e.g. x's shape:[3,3];tf.reshape(-1,x) & (3, 3)---->(1,9)
#4.=====>add dropout: use tf.nn.dropout
with tf.name_scope("dropout"):
self.h_drop=tf.nn.dropout(self.h_pool_flat,keep_prob=self.dropout_keep_prob) #[None,num_filters_total]
self.h_drop=tf.layers.dense(self.h_drop,self.num_filters_total,activation=tf.nn.tanh,use_bias=True)
#5. logits(use linear layer)and predictions(argmax)
with tf.name_scope("output"):
logits = tf.matmul(self.h_drop,self.W_projection) + self.b_projection #shape:[None, self.num_classes]==tf.matmul([None,self.embed_size],[self.embed_size,self.num_classes])
return logits
def batchnorm(self,Ylogits, is_test, iteration, offset, convolutional=False): #check:https://github.com/martin-gorner/tensorflow-mnist-tutorial/blob/master/mnist_4.1_batchnorm_five_layers_relu.py#L89
"""
batch normalization: keep moving average of mean and variance. use it as value for BN when training. when prediction, use value from that batch.
:param Ylogits:
:param is_test:
:param iteration:
:param offset:
:param convolutional:
:return:
"""
exp_moving_avg = tf.train.ExponentialMovingAverage(0.999,iteration) # adding the iteration prevents from averaging across non-existing iterations
bnepsilon = 1e-5
if convolutional:
mean, variance = tf.nn.moments(Ylogits, [0, 1, 2])
else:
mean, variance = tf.nn.moments(Ylogits, [0])
update_moving_averages = exp_moving_avg.apply([mean, variance])
m = tf.cond(is_test, lambda: exp_moving_avg.average(mean), lambda: mean)
v = tf.cond(is_test, lambda: exp_moving_avg.average(variance), lambda: variance)
Ybn = tf.nn.batch_normalization(Ylogits, m, v, offset, None, bnepsilon)
return Ybn, update_moving_averages
def loss_multilabel(self,l2_lambda=0.0001): #0.0001#this loss function is for multi-label classification
with tf.name_scope("loss"):
#input: `logits` and `labels` must have the same shape `[batch_size, num_classes]`
#output: A 1-D `Tensor` of length `batch_size` of the same type as `logits` with the softmax cross entropy loss.
#input_y:shape=(?, 1999); logits:shape=(?, 1999)
# let `x = logits`, `z = labels`. The logistic loss is:z * -log(sigmoid(x)) + (1 - z) * -log(1 - sigmoid(x))
losses = tf.nn.sigmoid_cross_entropy_with_logits(labels=self.input_y_multilabel, logits=self.logits);#losses=tf.nn.softmax_cross_entropy_with_logits(labels=self.input__y,logits=self.logits)
#losses=-self.input_y_multilabel*tf.log(self.logits)-(1-self.input_y_multilabel)*tf.log(1-self.logits)
print("sigmoid_cross_entropy_with_logits.losses:",losses) #shape=(?, 1999).
losses=tf.reduce_sum(losses,axis=1) #shape=(?,). loss for all data in the batch
loss=tf.reduce_mean(losses) #shape=(). average loss in the batch
l2_losses = tf.add_n([tf.nn.l2_loss(v) for v in tf.trainable_variables() if 'bias' not in v.name]) * l2_lambda
loss=loss+l2_losses
return loss
def loss(self,l2_lambda=0.0001):#0.001
with tf.name_scope("loss"):
#input: `logits`:[batch_size, num_classes], and `labels`:[batch_size]
#output: A 1-D `Tensor` of length `batch_size` of the same type as `logits` with the softmax cross entropy loss.
losses = tf.nn.sparse_softmax_cross_entropy_with_logits(labels=self.input_y, logits=self.logits);#sigmoid_cross_entropy_with_logits.#losses=tf.nn.softmax_cross_entropy_with_logits(labels=self.input_y,logits=self.logits)
#print("1.sparse_softmax_cross_entropy_with_logits.losses:",losses) # shape=(?,)
loss=tf.reduce_mean(losses)#print("2.loss.loss:", loss) #shape=()
l2_losses = tf.add_n([tf.nn.l2_loss(v) for v in tf.trainable_variables() if 'bias' not in v.name]) * l2_lambda
loss=loss+l2_losses
return loss
def train(self):
"""based on the loss, use SGD to update parameter"""
learning_rate = tf.train.exponential_decay(self.learning_rate, self.global_step, self.decay_steps,self.decay_rate, staircase=True)
train_op = tf.contrib.layers.optimize_loss(self.loss_val, global_step=self.global_step,learning_rate=learning_rate, optimizer="Adam",clip_gradients=self.clip_gradients)
return train_op
#test started. toy task: given a sequence of data. compute it's label: sum of its previous element,itself and next element greater than a threshold, it's label is 1,otherwise 0.
#e.g. given inputs:[1,0,1,1,0]; outputs:[0,1,1,1,0].
#invoke test() below to test the model in this toy task.
def test():
#below is a function test; if you use this for text classifiction, you need to transform sentence to indices of vocabulary first. then feed data to the graph.
num_classes=5
learning_rate=0.001
batch_size=8
decay_steps=1000
decay_rate=0.95
sequence_length=5
vocab_size=10000
embed_size=100
is_training=True
dropout_keep_prob=1.0 #0.5
filter_sizes=[2,3,4]
num_filters=128
multi_label_flag=True
textRNN=TextCNN(filter_sizes,num_filters,num_classes, learning_rate, batch_size, decay_steps, decay_rate,sequence_length,vocab_size,embed_size,is_training,multi_label_flag=multi_label_flag)
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
for i in range(500):
input_x=np.random.randn(batch_size,sequence_length) #[None, self.sequence_length]
input_x[input_x>=0]=1
input_x[input_x <0] = 0
input_y_multilabel=get_label_y(input_x)
loss,possibility,W_projection_value,_=sess.run([textRNN.loss_val,textRNN.possibility,textRNN.W_projection,textRNN.train_op],
feed_dict={textRNN.input_x:input_x,textRNN.input_y_multilabel:input_y_multilabel,textRNN.dropout_keep_prob:dropout_keep_prob})
print(i,"loss:",loss,"-------------------------------------------------------")
print("label:",input_y_multilabel);print("possibility:",possibility)
def get_label_y(input_x):
length=input_x.shape[0]
input_y=np.zeros((input_x.shape))
for i in range(length):
element=input_x[i,:] #[5,]
result=compute_single_label(element)
input_y[i,:]=result
return input_y
def compute_single_label(listt):
result=[]
length=len(listt)
for i,e in enumerate(listt):
previous=listt[i-1] if i>0 else 0
current=listt[i]
next=listt[i+1] if i<length-1 else 0
summ=previous+current+next
if summ>=2:
summ=1
else:
summ=0
result.append(summ)
return result
TextCNN_predict.py
import sys
import importlib
importlib.reload(sys)
#sys.setdefaultencoding('utf8')
import tensorflow as tf
import numpy as np
#from p5_fastTextB_model import fastTextB as fastText
from a02_TextCNN.other_experiement.data_util_zhihu import load_data_predict,load_final_test_data,create_voabulary,create_voabulary_label
from tflearn.data_utils import pad_sequences #to_categorical
import os
import codecs
from p7_TextCNN_model import TextCNN
#configuration
FLAGS=tf.app.flags.FLAGS
tf.app.flags.DEFINE_float("learning_rate",0.01,"learning rate")
tf.app.flags.DEFINE_integer("batch_size", 1, "Batch size for training/evaluating.") #批处理的大小 32-->128
tf.app.flags.DEFINE_integer("decay_steps", 5000, "how many steps before decay learning rate.") #批处理的大小 32-->128
tf.app.flags.DEFINE_float("decay_rate", 0.9, "Rate of decay for learning rate.") #0.5一次衰减多少
tf.app.flags.DEFINE_string("ckpt_dir","text_cnn_title_desc_checkpoint/","checkpoint location for the model")
tf.app.flags.DEFINE_integer("sentence_len",100,"max sentence length")
tf.app.flags.DEFINE_integer("embed_size",100,"embedding size")
tf.app.flags.DEFINE_boolean("is_training",False,"is traning.true:tranining,false:testing/inference")
tf.app.flags.DEFINE_integer("num_epochs",15,"number of epochs.")
tf.app.flags.DEFINE_integer("validate_every", 1, "Validate every validate_every epochs.") #每10轮做一次验证
tf.app.flags.DEFINE_string("predict_target_file","text_cnn_title_desc_checkpoint/zhihu_result_cnn_multilabel_v6_e14.csv","target file path for final prediction")
tf.app.flags.DEFINE_string("predict_source_file",'test-zhihu-forpredict-title-desc-v6.txt',"target file path for final prediction") #test-zhihu-forpredict-v4only-title.txt
tf.app.flags.DEFINE_string("word2vec_model_path","zhihu-word2vec-title-desc.bin-100","word2vec's vocabulary and vectors") #zhihu-word2vec.bin-100
tf.app.flags.DEFINE_integer("num_filters", 256, "number of filters") #128
##############################################################################################################################################
filter_sizes=[1,2,3,4,5,6,7]#[1,2,3,4,5,6,7]
#1.load data(X:list of lint,y:int). 2.create session. 3.feed data. 4.training (5.validation) ,(6.prediction)
# 1.load data with vocabulary of words and labels
vocabulary_word2index, vocabulary_index2word = create_voabulary(simple='simple',
word2vec_model_path=FLAGS.word2vec_model_path,
name_scope="cnn2")
vocab_size = len(vocabulary_word2index)
vocabulary_word2index_label, vocabulary_index2word_label = create_voabulary_label(name_scope="cnn2")
questionid_question_lists = load_final_test_data(FLAGS.predict_source_file)
test = load_data_predict(vocabulary_word2index, vocabulary_word2index_label, questionid_question_lists)
testX = []
question_id_list = []
for tuple in test:
question_id, question_string_list = tuple
question_id_list.append(question_id)
testX.append(question_string_list)
# 2.Data preprocessing: Sequence padding
print("start padding....")
testX2 = pad_sequences(testX, maxlen=FLAGS.sentence_len, value=0.) # padding to max length
print("end padding...")
# 3.create session.
config = tf.ConfigProto()
config.gpu_options.allow_growth = True
graph=tf.Graph().as_default()
global sess
global textCNN
with graph:
sess=tf.Session(config=config)
# 4.Instantiate Model
textCNN = TextCNN(filter_sizes, FLAGS.num_filters, FLAGS.num_classes, FLAGS.learning_rate, FLAGS.batch_size,
FLAGS.decay_steps, FLAGS.decay_rate,
FLAGS.sentence_len, vocab_size, FLAGS.embed_size, FLAGS.is_training)
saver = tf.train.Saver()
if os.path.exists(FLAGS.ckpt_dir + "checkpoint"):
print("Restoring Variables from Checkpoint")
saver.restore(sess, tf.train.latest_checkpoint(FLAGS.ckpt_dir))
else:
print("Can't find the checkpoint.going to stop")
#return
# 5.feed data, to get logits
number_of_training_data = len(testX2);
print("number_of_training_data:", number_of_training_data)
#index = 0
#predict_target_file_f = codecs.open(FLAGS.predict_target_file, 'a', 'utf8')
#############################################################################################################################################
def get_logits_with_value_by_input(start,end):
x=testX2[start:end]
global sess
global textCNN
logits = sess.run(textCNN.logits, feed_dict={textCNN.input_x: x, textCNN.dropout_keep_prob: 1})
predicted_labels,value_labels = get_label_using_logits_with_value(logits[0], vocabulary_index2word_label)
value_labels_exp= np.exp(value_labels)
p_labels=value_labels_exp/np.sum(value_labels_exp)
return predicted_labels,p_labels
def main(_):
# 1.load data with vocabulary of words and labels
vocabulary_word2index, vocabulary_index2word = create_voabulary(simple='simple',word2vec_model_path=FLAGS.word2vec_model_path,name_scope="cnn2")
vocab_size = len(vocabulary_word2index)
vocabulary_word2index_label, vocabulary_index2word_label = create_voabulary_label(name_scope="cnn2")
questionid_question_lists=load_final_test_data(FLAGS.predict_source_file)
test= load_data_predict(vocabulary_word2index,vocabulary_word2index_label,questionid_question_lists)
testX=[]
question_id_list=[]
for tuple in test:
question_id,question_string_list=tuple
question_id_list.append(question_id)
testX.append(question_string_list)
# 2.Data preprocessing: Sequence padding
print("start padding....")
testX2 = pad_sequences(testX, maxlen=FLAGS.sentence_len, value=0.) # padding to max length
print("end padding...")
# 3.create session.
config=tf.ConfigProto()
config.gpu_options.allow_growth=True
with tf.Session(config=config) as sess:
# 4.Instantiate Model
textCNN=TextCNN(filter_sizes,FLAGS.num_filters,FLAGS.num_classes, FLAGS.learning_rate, FLAGS.batch_size, FLAGS.decay_steps,FLAGS.decay_rate,
FLAGS.sentence_len,vocab_size,FLAGS.embed_size,FLAGS.is_training)
saver=tf.train.Saver()
if os.path.exists(FLAGS.ckpt_dir+"checkpoint"):
print("Restoring Variables from Checkpoint")
saver.restore(sess,tf.train.latest_checkpoint(FLAGS.ckpt_dir))
else:
print("Can't find the checkpoint.going to stop")
return
# 5.feed data, to get logits
number_of_training_data=len(testX2);print("number_of_training_data:",number_of_training_data)
index=0
predict_target_file_f = codecs.open(FLAGS.predict_target_file, 'a', 'utf8')
for start, end in zip(range(0, number_of_training_data, FLAGS.batch_size),range(FLAGS.batch_size, number_of_training_data+1, FLAGS.batch_size)):
logits=sess.run(textCNN.logits,feed_dict={textCNN.input_x:testX2[start:end],textCNN.dropout_keep_prob:1}) #'shape of logits:', ( 1, 1999)
# 6. get lable using logtis
predicted_labels=get_label_using_logits(logits[0],vocabulary_index2word_label)
# 7. write question id and labels to file system.
write_question_id_with_labels(question_id_list[index],predicted_labels,predict_target_file_f)
index=index+1
predict_target_file_f.close()
# get label using logits
def get_label_using_logits(logits,vocabulary_index2word_label,top_number=5):
index_list=np.argsort(logits)[-top_number:] #print("sum_p", np.sum(1.0 / (1 + np.exp(-logits))))
index_list=index_list[::-1]
label_list=[]
for index in index_list:
label=vocabulary_index2word_label[index]
label_list.append(label) #('get_label_using_logits.label_list:', [u'-3423450385060590478', u'2838091149470021485', u'-3174907002942471215', u'-1812694399780494968', u'6815248286057533876'])
return label_list
# get label using logits
def get_label_using_logits_with_value(logits,vocabulary_index2word_label,top_number=5):
index_list=np.argsort(logits)[-top_number:] #print("sum_p", np.sum(1.0 / (1 + np.exp(-logits))))
index_list=index_list[::-1]
value_list=[]
label_list=[]
for index in index_list:
label=vocabulary_index2word_label[index]
label_list.append(label) #('get_label_using_logits.label_list:', [u'-3423450385060590478', u'2838091149470021485', u'-3174907002942471215', u'-1812694399780494968', u'6815248286057533876'])
value_list.append(logits[index])
return label_list,value_list
# write question id and labels to file system.
def write_question_id_with_labels(question_id,labels_list,f):
labels_string=",".join(labels_list)
f.write(question_id+","+labels_string+"\n")
if __name__ == "__main__":
#tf.app.run()
labels,list_value=get_logits_with_value_by_input(0, 1)
print("labels:",labels)
print("list_value:", list_value)