1.安装jieba库
舍友帮装的,我也不会( ╯□╰ )
2.上网寻找政府工作报告
3.参照课本三国演义词频统计代码编写
import jieba
txt = open("D:\政府工作报告.txt","r",encoding='utf-8').read()
words = jieba.lcut(txt)
counts = {}
for word in words:
if len(word) == 1:
continue
else:
counts[word] = counts.get(word,0) + 1
items = list(counts.items())
items.sort(key=lambda x:x[1], reverse=True)
for i in range(10):
word, count = items[i]
print ("{0:<10}{1:>5}".format(word, count))
结果显示如下
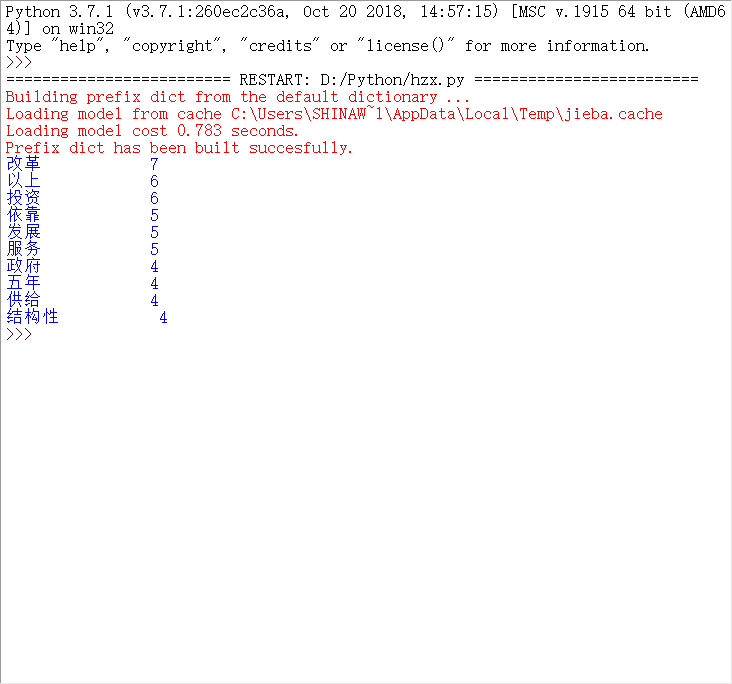
可见改革和发展出现的次数还是很高的,高频词体现了政府工作的重点在于改革方面。