---恢复内容开始---
一、结巴中文分词涉及到的算法包括:
(1) 基于Trie树结构实现高效的词图扫描,生成句子中汉字所有可能成词情况所构成的有向无环图(DAG);
(2) 采用了动态规划查找最大概率路径, 找出基于词频的最大切分组合;
(3) 对于未登录词,采用了基于汉字成词能力的HMM模型,使用了Viterbi算法。
结巴中文分词支持的三种分词模式包括:
(1) 精确模式:试图将句子最精确地切开,适合文本分析;
(2) 全模式:把句子中所有的可以成词的词语都扫描出来, 速度非常快,但是不能解决歧义问题;
(3) 搜索引擎模式:在精确模式的基础上,对长词再次切分,提高召回率,适合用于搜索引擎分词。
同时结巴分词支持繁体分词和自定义字典方法。
二、首先要先在cmd下载结巴
可以通过pip指令安装:pip install jieba #或者 pip3 install jieba
然后通过pip show pip检查是否是下载成功

这个就是jieba安装成功了
三、
#encoding=utf-8
importjieba
#全模式
text ="我来到北京清华大学"
seg_list = jieba.cut(text, cut_all=True)
printu"[全模式]: ","/ ".join(seg_list)
#精确模式
seg_list = jieba.cut(text, cut_all=False)
printu"[精确模式]: ","/ ".join(seg_list)
#默认是精确模式
seg_list = jieba.cut(text)
printu"[默认模式]: ","/ ".join(seg_list)
#新词识别 “杭研”并没有在词典中,但是也被Viterbi算法识别出来了
seg_list = jieba.cut("他来到了网易杭研大厦")
printu"[新词识别]: ","/ ".join(seg_list)
#搜索引擎模式
seg_list = jieba.cut_for_search(text)
printu"[搜索引擎模式]: ","/ ".join(seg_list)
输出如图所示:
代码中函数简单介绍如下:
jieba.cut():第一个参数为需要分词的字符串,第二个cut_all控制是否为全模式。
jieba.cut_for_search():仅一个参数,为分词的字符串,该方法适合用于搜索引擎构造倒排索引的分词,粒度比较细。
其中待分词的字符串支持gbk\utf-8\unicode格式。返回的结果是一个可迭代的generator,可使用for循环来获取分词后的每个词语,更推荐使用转换为list列表。
2.添加自定义词典
由于"国家5A级景区"存在很多旅游相关的专有名词,举个例子:
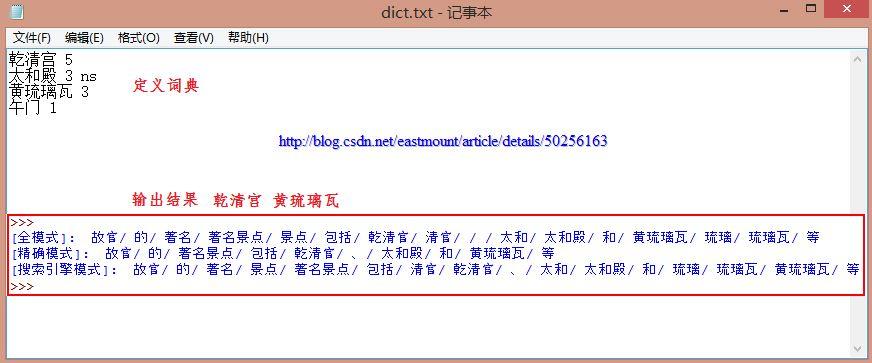
[输入文本] 故宫的著名景点包括乾清宫、太和殿和黄琉璃瓦等
[精确模式] 故宫/的/著名景点/包括/乾/清宫/、/太和殿/和/黄/琉璃瓦/等
[全 模 式] 故宫/的/著名/著名景点/景点/包括/乾/清宫/太和/太和殿/和/黄/琉璃/琉璃瓦/等
显然,专有名词"乾清宫"、"太和殿"、"黄琉璃瓦"(假设为一个文物)可能因分词而分开,这也是很多分词工具的又一个缺陷。但是Jieba分词支持开发者使用自定定义的词典,以便包含jieba词库里没有的词语。虽然结巴有新词识别能力,但自行添加新词可以保证更高的正确率,尤其是专有名词。
词典格式和dict.txt一样,一个词占一行;每一行分三部分,一部分为词语,另一部分为词频,最后为词性(可省略,ns为地点名词),用空格隔开。
#encoding=utf-8
importjieba
#导入自定义词典
jieba.load_userdict("dict.txt")
#全模式
text ="故宫的著名景点包括乾清宫、太和殿和黄琉璃瓦等"
seg_list = jieba.cut(text, cut_all=True)
printu"[全模式]: ","/ ".join(seg_list)
#精确模式
seg_list = jieba.cut(text, cut_all=False)
printu"[精确模式]: ","/ ".join(seg_list)
#搜索引擎模式
seg_list = jieba.cut_for_search(text)
printu"[搜索引擎模式]: ","/ ".join(seg_list)
输出结果如下所示:其中专有名词连在一起,即"乾清宫"和"黄琉璃瓦"。
---恢复内容结束---