"""
author:魏振东
data:2019.12.18
func:统计词频 词性标注 excel文件操作
"""import jieba.posseg as psg
from collections import Counter
import xlwt
# 用分词工具进行分词,带有词性标注,保存到文件中。defcixing(filenamer,filenamerw):# 文件读取withopen(filenamer,'r',encoding='utf-8',errors='ignore')as fr:
article = fr.read()# 词性标注
seg_list = psg.cut(article)# 格式化
result =" ".join(["{0}:{1}\n".format(w, t)for w, t in seg_list iflen(w)!=1])# 文件写入withopen(filenamerw,'w+')as r:
r.write(result)# print(result)# 统计词频,保存到文件中。defcipin(filenamer,filenamerw):# 文件读取withopen(filenamer,'r', encoding='utf-8', errors='ignore')as fr:
article = fr.read()# 词性标注
seg_list = psg.cut(article)# 数据清洗
seg_list1 =["{0}".format(w)for w, t in seg_list iflen(w)!=1]# 计数
count = Counter(seg_list1)# 字典排序
dic3 =sorted(count.items(), key=lambda x: x[1], reverse=True)# print(count)withopen(filenamerw,'w+')as r:for x in dic3:
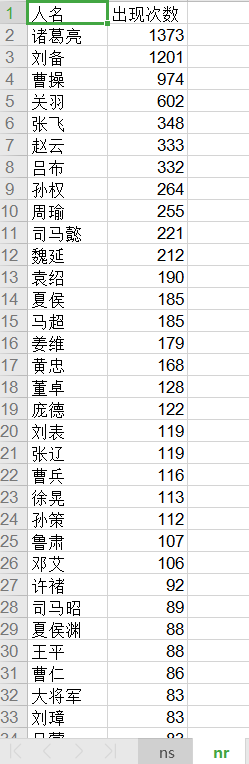
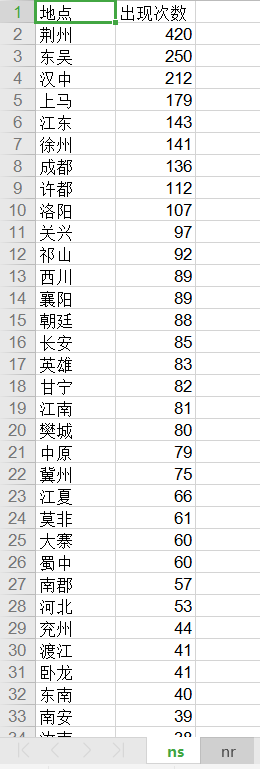
r.write('{0} 出现{1}次\n'.format(x[0],x[1]))# 统计出现的人名,地名,保存到文件中。如果可以把人名进行统一就更好了,比如曹操,曹贼,丞相,阿蛮都是一个人。甚至你还可以统计人物的穿着,常用的武器等。deftongji(filenamer,filenamerw):# 文件读取withopen(filenamer,'r', encoding='utf-8', errors='ignore')as fr:
article = fr.read()# 词性标注
seg_list = psg.cut(article)# 数据清洗
excludes ={'将军','却说','令人','赶来','徐州','不见','下马','喊声','因此','未知','大败','百姓','大事','一军','之后','接应','起兵','成都','原来','江东','正是','忽然','原来','大叫','上马','天子','一面','太守','不如','忽报','后人','背后','先主','此人','城中','然后','大军','何不','先生','何故','夫人','不如','先锋','二人','不可','如何','荆州','不能','如此','主公','军士','商议','引兵','次日','大喜','魏兵','军马','于是','东吴','今日','左右','天下','不敢','陛下','人马','不知','都督','汉中','一人','众将','后主','只见','蜀兵','马军','黄巾','立功','白发','大吉','红旗','士卒','钱粮','于汉','郎舅','龙凤','古之','白虎','古人云','尔乃','马飞报','轩昂','史官','侍臣','列阵','玉玺','车驾','老夫','伏兵','都尉','侍中','西凉','安民','张曰','文武','白旗','祖宗','寻思'}# 排除的词汇
dic1 ={}for word, t in seg_list:if t =='nr':iflen(word)==1orlen(word)>=4or word in excludes:# 排除单个字符的分词结果continueelif word =='孔明'or word =='孔明曰'or word =='卧龙先生':
real_word ='诸葛亮'elif word =='云长'or word =='关公曰'or word =='关公':
real_word ='关羽'elif word =='玄德'or word =='玄德曰'or word =='玄德甚'or word =='玄德遂'or word =='玄德兵'or word =='玄德领' \
or word =='玄德同'or word =='刘豫州'or word =='刘玄德':
real_word ='刘备'elif word =='孟德'or word =='丞相'or word =='曹贼'or word =='阿瞒'or word =='曹丞相'or word =='曹将军':
real_word ='曹操'elif word =='高祖':
real_word ='刘邦'elif word =='光武':
real_word ='刘秀'elif word =='桓帝':
real_word ='刘志'elif word =='灵帝':
real_word ='刘宏'elif word =='公瑾':
real_word ='周瑜'elif word =='伯符':
real_word ='孙策'elif word =='吕奉先'or word =='布乃'or word =='布大怒'or word =='吕布之':
real_word ='吕布'elif word =='赵子龙'or word =='子龙':
real_word ='赵云'elif word =='卓大喜'or word =='卓大怒':
real_word ='董卓'else:
real_word = word
dic1.setdefault(t,[]).append("{0}".format(real_word))elif t =='ns':iflen(word)==1orlen(word)>=4:continueelse:
dic1.setdefault(t,[]).append("{0}".format(word))# print(dic1['ns'])# print(dic1['nr'])# 计数
count = Counter(dic1['ns'])
count1 = Counter(dic1['nr'])# 排序
dic3 =sorted(count.items(), key=lambda x: x[1], reverse=True)
dic4 =sorted(count1.items(), key=lambda x: x[1], reverse=True)# print(dic3)# 创建一个workbook 设置编码
workbook = xlwt.Workbook(encoding='utf-8')# 创建一个worksheet
worksheet = workbook.add_sheet('ns')# 写入excel# 参数对应 行, 列, 值
worksheet.write(0,0, label='地点')
worksheet.write(0,1, label='出现次数')
i=1for x in dic3:
worksheet.write(i,0, label=x[0])
worksheet.write(i,1, label=x[1])
i = i+1
worksheet1 = workbook.add_sheet('nr')# 写入excel# 参数对应 行, 列, 值
worksheet1.write(0,0, label='人名')
worksheet1.write(0,1, label='出现次数')
i =1for x in dic4:
worksheet1.write(i,0, label=x[0])
worksheet1.write(i,1, label=x[1])
i = i +1# 保存
workbook.save(filenamerw)if __name__ =='__main__':# 用分词工具进行分词,带有词性标注,保存到文件中。
cixing('171182.txt','词性标注.txt')# 统计词频,保存到文件中。# cipin('171182.txt','统计词频.txt')# 统计出现的人名,地名,保存到文件中。如果可以把人名进行统一就更好了,比如曹操,曹贼,丞相,阿蛮都是一个人。甚至你还可以统计人物的穿着,常用的武器等。# tongji('171182.txt','Excel_test.xls')