BeautifulSoup是一个可以从HTML或XML文件中提取数据的Python库,是通过转换器实现惯用文档导航,查找,修改的工具。BeautifulSoup将复杂的HTML文档转换成一个复杂的树形结构,树的每一个节点都是Python对象,所有对象可以归纳为四种: Tag , NavigableString , BeautifulSoup , Comment 。
一、Tag
1.Tag对象即HTML或XML文档中的tag标签对象。
代码:

运行结果:

2.属性
(1)Name
每个tag都有自己的名字,通过tag.name来获取;如果改变了tag的name,将影响所有通过当前BeautifulSoup对象生成的HTML文档。
代码:

运行结果:

(2)Attributes(标签的属性属性)
一个tag可能有很多个属性,tag的属性的操作方法与字典相同;tag的属性可以被增加、修改和删除。
代码:

运行结果:

3.多值属性(可以包含多个值的属性)
(1)在BeautifulSoup中多值属性的返回类型是list。
(2)如果某个属性看起来像是有多个值,但在HTML中没有被定义为多值属性,那么BeautifulSoup会将这个属性作为字符串返回。
(3)将tag转换成字符串时,多值属性会合并为一个值。
(4)如果转换的文档是XML格式,那么tag中不包含多值属性。
代码:

运行结果:

二、NavigableString(可遍历的字符串)
字符串常被包含在tag内.Beautiful Soup用 NavigableString 类来包装tag中的字符串。
1.一个 NavigableString 字符串与Python中的Unicode字符串相同,并且还支持包含在 遍历文档树 和 搜索文档树 中的一些特性. 通过 unicode() 方法可以直接将 NavigableString 对象转换成Unicode字符串。
代码:

运行结果:

2.tag中包含的字符串不能编辑,但是可以被替换成其它的字符串,用 replace_with() 方法:
代码:

运行结果:

3.NavigableString 对象支持 遍历文档树 和 搜索文档树 中定义的大部分属性, 并非全部.尤其是,一个字符串不能包含其它内容(tag能够包含字符串或是其它tag),字符串不支持 .contents 或 .string 属性或 find() 方法.
4.如果想在Beautiful Soup之外使用 NavigableString 对象,需要调用 unicode() 方法,将该对象转换成普通的Unicode字符串,否则就算Beautiful Soup已方法已经执行结束,该对象的输出也会带有对象的引用地址.这样会浪费内存.
三、BeautifulSoup
BeautifulSoup 对象表示的是一个文档的全部内容.大部分时候,可以把它当作 Tag 对象,它支持 遍历文档树 和 搜索文档树 中描述的大部分的方法。因为 BeautifulSoup 对象并不是真正的HTML或XML的tag,所以它没有name和attribute属性.但有时查看它的 .name 属性是很方便的,所以 BeautifulSoup 对象包含了一个值为 “[document]” 的特殊属性 .name。
代码:

运行结果:
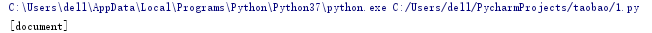
四、Comment(注释及特殊字符串)
1.Comment 对象是一个特殊类型的 NavigableString 对象,但是当它出现在HTML文档中时, Comment 对象会使用特殊的格式输出。
代码:

运行结果:

2.Beautiful Soup中定义的其它类型都可能会出现在XML的文档中: CData , ProcessingInstruction , Declaration , Doctype .与 Comment 对象类似,这些类都是 NavigableString 的子类,只是添加了一些额外的方法的字符串独享.下面是用CDATA来替代注释的例子。
代码:

运行结果:
