版权声明:转载必须经过本人同意,并且注明文章来源! https://blog.csdn.net/weixin_41665360/article/details/88777776
1、基本排序算法
基本排序算法包括:冒泡排序,选择排序和插入排序。
1.1、冒泡排序
原理:
- 每次比较相邻两个元素,确保小的在前,大的在后,第一轮过后,最大的元素“沉在”最后的位置。
- 针对除了最后一个元素外其他元素,重复之前的过程,知道没有数字需要比较
代码如下:
def bubble_sort(seq): # O(n^2), n(n-1)/2 = 1/2(n^2 + n)
n = len(seq)
for i in range(n-1): # 排好序的元素个数为 i
exchange = 0
for j in range(n-1-i): # 减去 i 是因为最后 i 个元素位置已排好
if seq[j] > seq[j+1]: # 若降序,则交换相邻元素
seq[j], seq[j+1] = seq[j+1], seq[j]
exchange += 1
if exchange == 0: # 子序列已经为升序,则退出循环
break
print(seq)
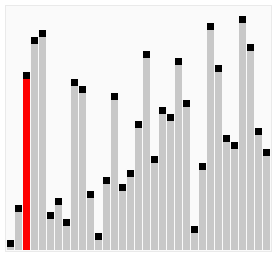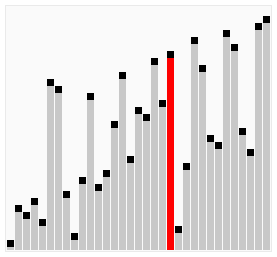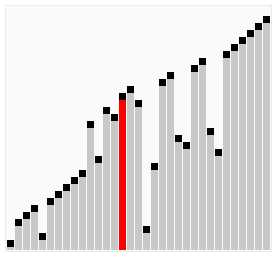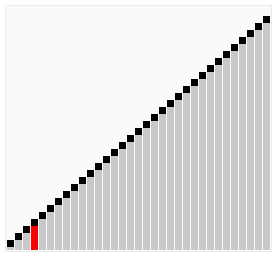
测试结果如下:
import random
def test_bubble_sort():
seq = list(range(10))
random.shuffle(seq) # shuffle 打乱数组
bubble_sort(seq)
assert seq == sorted(seq)
# 内置的 sorted 不是 inplace 的,返回一个新的数组
"""
[3, 4, 5, 0, 9, 1, 7, 8, 6, 2]
[3, 4, 0, 5, 1, 7, 8, 6, 2, 9]
[3, 0, 4, 1, 5, 7, 6, 2, 8, 9]
[0, 3, 1, 4, 5, 6, 2, 7, 8, 9]
[0, 1, 3, 4, 5, 2, 6, 7, 8, 9]
[0, 1, 3, 4, 2, 5, 6, 7, 8, 9]
[0, 1, 3, 2, 4, 5, 6, 7, 8, 9]
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
"""
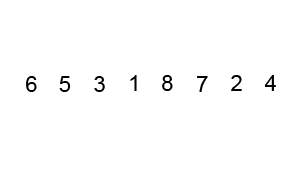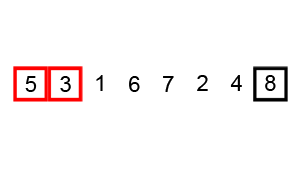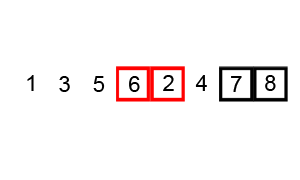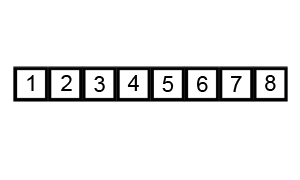
最优时间复杂度:
最差时间复杂度:
算法稳定性:稳定
1.2、选择排序
原理:
- 从所有元素中找到最小值,放在第一位
- 从剩下的元素中找到最小值放在第二位
- 重复以上过程直到所有元素排序完成
代码如下:
def select_sort(seq):
n = len(seq)
for i in range(n-1):
min_ind = i # 假设当前下标的元素是最小的
for j in range(i+1, n): # 从 i 的后边开始找到最小的元素的下标
if seq[j] < seq[min_ind]:
min_ind = j # 一个循环之后找到最小的元素它的下标
if min_ind != i: # 若最小元素不在位置 i 则交换
seq[i], seq[min_idx] = seq[min_idx], seq[i]
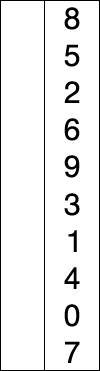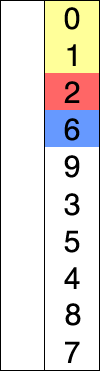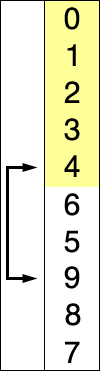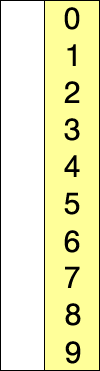
测试结果如下:
def test_select_sort():
seq = list(range(10))
random.shuffle(seq)
select_sort(seq)
assert seq == sorted(seq)
"""
[4, 7, 5, 3, 6, 0, 2, 9, 8, 1]
[0, 7, 5, 3, 6, 4, 2, 9, 8, 1]
[0, 1, 5, 3, 6, 4, 2, 9, 8, 7]
[0, 1, 2, 3, 6, 4, 5, 9, 8, 7]
[0, 1, 2, 3, 6, 4, 5, 9, 8, 7]
[0, 1, 2, 3, 4, 6, 5, 9, 8, 7]
[0, 1, 2, 3, 4, 5, 6, 9, 8, 7]
[0, 1, 2, 3, 4, 5, 6, 9, 8, 7]
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
"""
最优时间复杂度:
最差时间复杂度:
算法稳定性:不稳定
1.3、插入排序
原理:
- 假设已有一组排序好的序列
- 找到新插入的元素在排序好的序列中的插入位置,插入该元素
- 从第二个元素开始逐个插入,直到排序完成
代码如下:
def insertion_sort(seq):
""" 每次挑选下一个元素插入已经排序好的数组中 """
n = len(seq)
print(seq)
for i in range(1, n): # 从第二个元素开始逐个插入
value = seq[i] # 保存当前位置的值,转移的过程中它可能被覆盖
pos = i # 找到 seq[i] 插入的位置,可能在 0-i
while pos > 0 and value < seq[pos-1]:
seq[pos] = seq[pos-1] # 如果前边的元素比它大,就让它一直前移
pos -= 1
seq[pos] = value # 找到了合适的位置插入
print(seq) # 打印排序好的序列
测试结果如下:
""" 不断把新元素放到已经有序的数组中
[1, 7, 3, 0, 9, 4, 8, 2, 6, 5]
[1, 7, 3, 0, 9, 4, 8, 2, 6, 5]
[1, 3, 7, 0, 9, 4, 8, 2, 6, 5]
[0, 1, 3, 7, 9, 4, 8, 2, 6, 5]
[0, 1, 3, 7, 9, 4, 8, 2, 6, 5]
[0, 1, 3, 4, 7, 9, 8, 2, 6, 5]
[0, 1, 3, 4, 7, 8, 9, 2, 6, 5]
[0, 1, 2, 3, 4, 7, 8, 9, 6, 5]
[0, 1, 2, 3, 4, 6, 7, 8, 9, 5]
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
"""
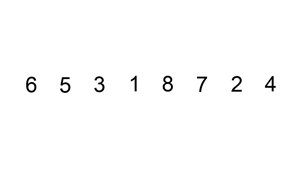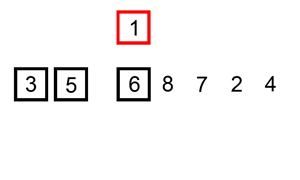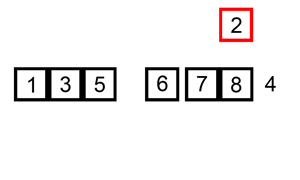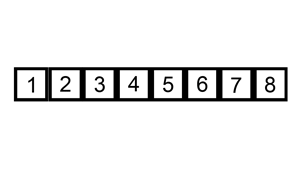
最优时间复杂度:
最差时间复杂度:
算法稳定性:稳定
1.4、小结
| 排序算法 | 最优时间复杂度 | 最坏时间复杂度 | 算法稳定性 |
|---|---|---|---|
| 冒泡排序 | 稳定 | ||
| 选择排序 | 不稳定 | ||
| 插入排序 | 稳定 |
4、希尔排序
希尔排序是一种特殊的插入排序。
原理:
- 将数组分割为 列,分别对每列进行插入排序
- 调整 值,重复以上过程,直到排序完成
代码如下:
def shell_sort(seq):
"""希尔排序"""
n = len(seq)
gap = n//2
while gap > 0:
for i in range(gap, n):
j = i
# 这里等价于插入排序
while j > 0:
if seq[j] < seq[j-gap]:
seq[j], seq[j-gap] = seq[j-gap], seq[j]
j -= gap
else: break
gap //= 2
最优时间复杂度:取决于步长
最差时间复杂度:
算法稳定性:不稳定
5、快速排序
原理:
- 从数列中挑出一个元素,作为“基准”( )
- 将比基准小的元素放左边,比基准大的放右边(相等的放在任一边),分区结束后,基准处在排序后的正确的位置,这个操作称为分区( )
- 递归( )地将小于基准的子序列和大于基准的子序列排序
代码如下:
# 非 inplace 实现
def quick_sort(seq):
size = len(seq)
if not seq or size < 2: # 空数组或者只有一个元素的数组都是有序的
return seq
pivot_idx = 0
pivot = seq[pivot_idx]
less_part = [seq[i] for i in range(size) if seq[i] <= pivot and pivot_idx != i]
great_part = [seq[i] for i in range(size) if seq[i] > pivot and pivot_idx != i]
return quick_sort(less_part) + [pivot] + quick_sort(great_part)
# inplace 实现
def quick_sort(seq, first, last):
"""快速排序"""
n = len(seq)
mid_value = seq[0]
low = first
high = last
while low < high:
# high 左移,相等的放右边
while low < high and seq[high] >= mid_value:
high -= 1
seq[low] = seq[high]:
# low 右移
while low < high and seq[low] < mid_value:
low += 1
seq[high] = seq[low]
# 循环退出时,low = high
seq[low] = mid_value
# 对左边快排
quick_sort(seq, first, low-1)
# 对右边快排
quick_sort(seq, low+1, last)
最优时间复杂度:
最差时间复杂度:
算法稳定性:不稳定
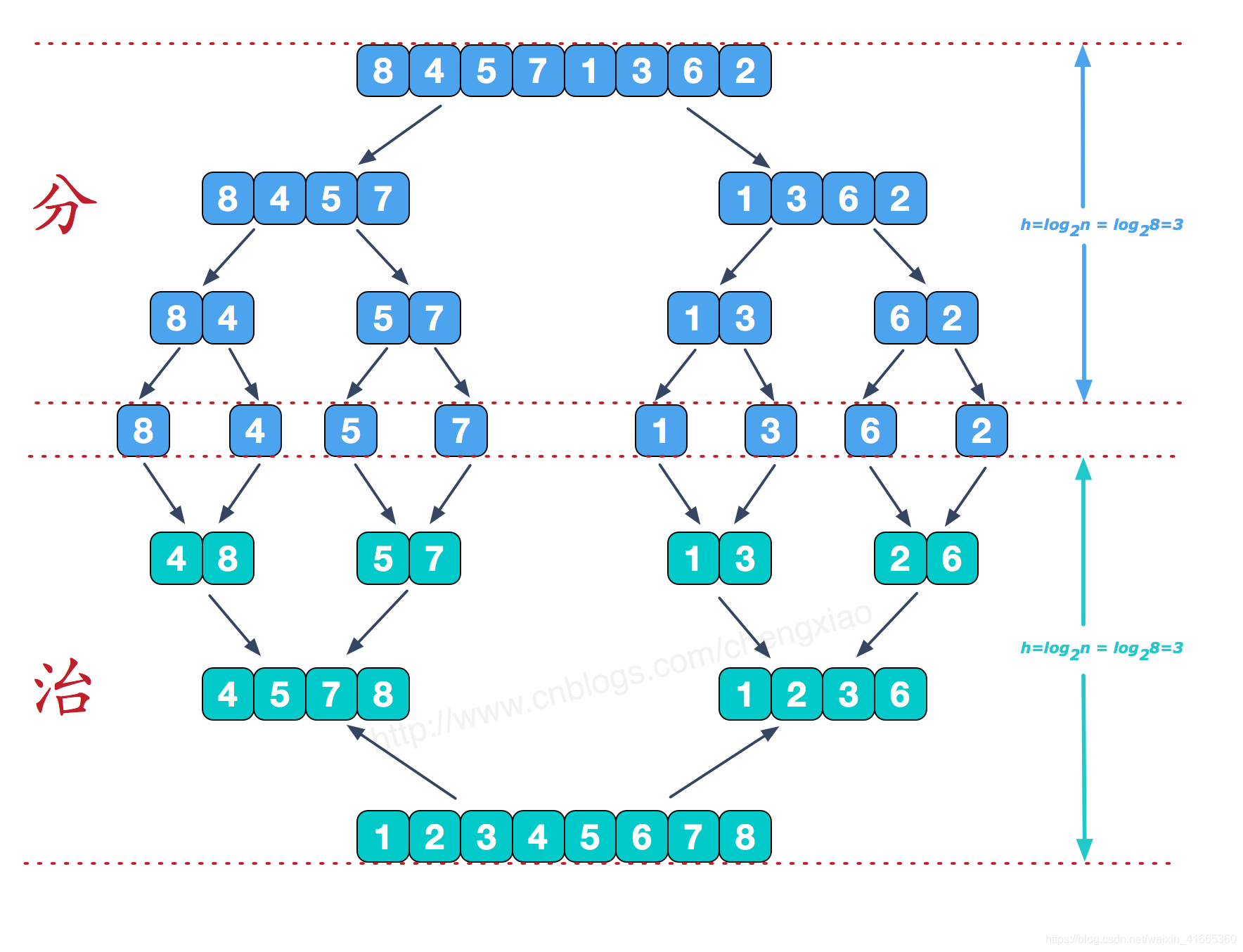
6、归并排序
原理:
- 将列表进行拆分,直到每部分只有一个元素为止
- 从两数组第一个元素开始,取较小的元素,取出元素后的指针向后移动一位,然后再进行比较,直到一个数组全部取完,把另一数组余下部分复制过来即可。
- 重复第二步,直到所有数组全部合并
代码如下:
def merge_sort(seq):
"""归并排序"""
n = len(seq)
if n <= 1: # 只有一个元素是递归出口
return seq
mid = n // 2
left_half = merge_sort(seq[:mid])
right_half = merge_sort(seq[mid:])
# 合并两个有序的数组
length_a, length_b = len(left_half), len(right_half)
a = b = 0
sorted_seq = list()
while a < length_a and b < length_b:
if left_half[a] < right_half[b]:
sorted_seq.append(left_half[a])
a += 1
else:
sorted_seq.append(right_half[b])
b += 1
# 如果 a 或 b 中还有剩余元素,需要放到最后
if a < length_a:
sorted_seq.extend(left_half[a:])
else:
sorted_seq.extend(right_half[b:])
return new_seq
最优时间复杂度:
最差时间复杂度:
算法稳定性:稳定
7、堆排序
堆排序是对选择排序算法的改进。
大顶堆:每个结点的值都大于等于左右子结点的值。
小顶堆:每个结点的值都小于等于左右子结点的值。
原理:
- 将待排序序列构成一个大顶堆(小顶堆)。
- 此时根结点的值为最大值,将其与序列末尾元素交换。
- 将剩余 个元素序列构成新的大顶堆,得到序列次大值,将其与序列倒数第二个元素交换。
- 重复该过程,直到完全排序。
代码如下:
def heap_sort(iterable):
from heapq import heappush, heappop
items = []
for value in iterable:
heappush(items, value)
return [heappop(items) for i in range(len(items))]
最优时间复杂度:
最差时间复杂度:
算法稳定性:不稳定
8、总结
以下为各排序算法时间复杂度及算法稳定性的总结
| 排序算法 | 最优时间复杂度 | 最坏时间复杂度 | 算法稳定性 |
|---|---|---|---|
| 冒泡排序 | 稳定 | ||
| 选择排序 | 不稳定 | ||
| 插入排序 | 稳定 | ||
| 希尔排序 | 不稳定 | ||
| 快速排序 | 不稳定 | ||
| 归并排序 | 稳定 | ||
| 堆排序 | 不稳定 |