跟单智能体强化学习相比,多智能体强化学习的入门似乎更难,想了想觉得有以下几个方面的原因:
(1) 多智能体强化学习研究成果较少,没有一本经典的系统的书籍来介绍。而单智能体强化学习算法有本神作,即Sutton的《Reinforcement Learning: An introduction》,有这本神作,足矣。(当然对于入门的中国学生来说,我今年出版的中文书籍《深入浅出强化学习:原理入门》可以作为辅助教材来帮助理解。该书后面还会有提起,简称为入门书)
(2) 多智能体强化学习没有系统的网络课程,而单智能体强化学习算法至少有David Silver的视频教程,而且还有伯克利、斯坦福的系列教程。在这些课程的帮助下,可以深刻理解单智能体强化学习。
(3) 多智能体强化学习算法缺少系统的开源代码,而单智能体强化学习算法至少有不少开源代码,如莫烦的专栏,叶强的专栏等。
(4) 多智能体强化学习所涉及到的理论知识更多,如马尔科夫决策过程,博弈论等,而单智能体强化学习只需要弄懂马尔科夫决策过程就够了。
由于这四个原因,多智能体强化学习将很多人挡在门外。其实国内从事多智能体研究的前辈有很多,如南京大学的高阳老师,清华大学的唐平中老师,天津大学的郝建业老师等等,他们在各自的领域做出很好的研究,但至今尚未看到一本系统介绍多智能强化学习入门的书。
本专栏开始的多智能体强化学习笔记系列就是在此抛砖引玉,希望能和大家一起来了解和入门多智能体强化学习。
1. 第一个问题,什么是多智能体强化学习?
在此,举一个非常简单的例子。如图1所示为两个智能体将金条搬运回家的例子。在这里我们称两个智能体分别是小红和小蓝。该例子的故事应该是这样的:小红和小蓝是幸福甜蜜的一对夫妻,有一天他们在离家不远的地方发现一根金条,这根金条需要两个人一人抬着一边才能扛回家。假设他们各自的初始位置如图1所示。要想把金条扛回家,小红和小蓝必须先绕过障碍物,然后每个人到达金条的一边,扛起金条后,两人还得绕开家门口的障碍物,这样才能将金条扛回家。
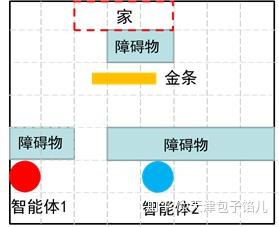
图1 两个智能体搬运金条
这是一个典型的多智能体协作的例子。该例子来自于多智能体强化学习综述论文《Multi-agent reinforcement learning: An overview》,这里对原文中的例子稍稍改编了一下。
从这个例子中,我们可以思考一下,什么是多智能体强化学习。我觉得多智能体强化学习至少应该包括如下几个要素:
(1) 在多智能体系统中至少有两个智能体。
(2) 智能体之间存在着一定的关系,如合作关系(如本例),竞争关系(如多人游戏),或者同时存在竞争与合作的关系。
(3) 每个智能体最终所获得的回报不仅仅与自身的动作有关系,还跟对方的动作有关系。如本例中每个智能体要想获得回报,必须是金条被两个智能体一起搬回家。
在单智能体强化学习中,我们用马尔科夫决策过程来描述智能体的学习(见“入门书”),那么在多智能体强化学习中,如何描述多智能体的学习呢?
第二个问题:如何描述多智能体系统的学习?
单智能体强化学习用马尔科夫决策过程来描述,而多智能体强化学习需要用马尔科夫博弈来描述。
马尔科夫博弈(Markov game)又称为随机博弈(stochastic game)。这个概念似乎很抽象,初次遇到你是不是又要挠头了?其实这个概念很容易理解,我们还是像介绍单智能体强化学习的方法介绍多智能体:即理解概念。
我们将马尔科夫博弈拆分成两个词:马尔科夫和博弈。
首先,马尔科夫是指多智能体系统的状态符合马尔科夫性,即下一时刻的状态只与当前时刻有关,与前面的时刻没有直接关系。
其次:博弈,描述的是多智能体之间的关系。
所以马尔科夫博弈这个词完全描述了一个多智能体系统。用更精确的数学语言进行形式化描述则为:
随机博弈(又称为马尔科夫博弈),可用一个元组
来描述。其中:
为玩家的个数,在本例中n为2。
为系统状态,一般指多智能体的联合状态,即每个智能体的联合状态。在本例中联合状态可表示为
,其中 为两个智能体的位置坐标,
表示两个智能体有没有抓住金条。
为状态转移函数,指给定玩家当前状态和联合行为时,下一状态的概率分布。即:
。
为回报函数,
.
表示玩家
在状态
时,采取联合行为 之后在状态
所得到的回报。
有同学肯定会问,之前您说马尔科夫博弈描述了多智能体系统的两个方面:多智能体之间的状态符合马尔科夫性,多智能体之间的关系。但是形式化表述怎么没有体现出来这两个性质呢?
我的回答是,其实形式化表述已经描述了这两个属性。我们回过头来仔细看马尔科夫博弈的形式化描述。
(1)状态转移概率 ,描述了状态的马尔科夫性。
(2)回报函数则完全描述了多智能体之间的关系。需要注意的是这里的回报函数是每个智能体的回报函数。当每个智能体的回报函数一致时,则表示智能体之间是合作关系;当回报函数相反时,则表示智能体之间是竞争关系,当回报函数介于两者之间,则是混合关系。
有了形式化描述,我们再看一看多智能体和单智能体之间的区别。
最重要的区别是多智能体的状态转移和回报都是建立在联合动作的条件下。
图2 多智能强化学习系统
如图2所示,多智能体同时动作,在联合动作下,整个系统才会转移,才能得到立即回报。图2来自文献”Game Theory and Multi-agent Reinforcement Learning”。
今天的笔记先更新到这里,下次笔记预告:多智能强化学习算法的基本框架,经典算法。