1.多智能体强化学习
系统里的agents数量大于1,agents彼此之间不是独立的
- 每个agent的动作都能影响到下一个状态
- 每个agent都能影响到其他agent
除非agent之间是独立的,否则单一agent的RL方法不适合MARL
2.MARL的类型
- Fully cooperative(完全合作):agents合作优化同一个回报,如工业机器人
- Fully competitive(完全竞争):一个agent的利益和另一个agent的损失,如捕猎者和猎物
- Mixed cooperative & competitive(合作和竞争):如机器人足球,同一队合作关系,两队竞争关系
- Self-interested(利己主义):不关心其他agent的奖励,如自动交易系统,无人驾驶。
3.MARL概念
3.1 State, Action, State Transition
每个agent都有一个action,转移到下一个状态取决于所有智能体的动作

3.2 Rewards
每个agent都有一个reward,reward不仅取决于这个agent的动作,也取决于所有其他agent的动作。在完全合作中,每个agent的奖励都是一样的,在完全竞争中,奖励是相反的。

3.3 Returns
时刻t,每个agent都有一个reward,因此也有对应的return

3.4 Policy Network
每个agent都有自己的策略网络,有些场景下策略是可交换的,即共享一个策略,比如自动驾驶策略相同,有些场景下策略不可交换,比如足球中前锋和门将代表不同的角色,策略也不同。

3.5 Uncertainty in the Return
某时刻某个agent的奖励取决于当前状态和所有其他agents的动作。状态的转移本身就存在不确定性,动作是根据策略随机选择的,回报取决于所有未来的状态和未来的动作,因此回报也存在不确定性。

3.5 State-Value Function
状态值函数是回报的期望,回报是奖励的期望,而奖励取决于所有agents的动作,动作是基于策略随机选择。因此某时刻某个agent的状态值函数取决于所有agents的策略参数。如果一个agent改变了它的策略,所有其它agents的状态值函数都会改变。
比如在足球比赛中,前锋改进了策略,其他人的策略不变,他的团队的状态值函数也会增加,对面的球员状态值函数会减少。

4.学习收敛性
对于单智能体策略的学习,当目标函数停止增加时则收敛。对于多个智能体的学习则使用纳什均衡(Nash Equilibrium),对于每个agent,当其它agent的策略不变时,它改变策略不会获得更高的回报。纳什均衡下能实现收敛,因为每个agent都没有改变的动力。

5.MARL的难点
之前的单一智能体梯度策略更新的方法不再适用于MARL。如果在MARL,每个agent都只更新自己的策略网络,而策略更新的目标函数取决于所有agent的参数,因此会出现以下情况:对于agent1,已经找到了最优参数,然后agent2改变了它的策略,agent1的目标函数也会改变,找到的最优策略就不在是最优的,又需要重新学习更新,如此往复难以实现收敛,因此需要设计针对多智能体的RL方法。

6.MARL的三种架构
MARL有三种结构:
- Fully Decentralized:完全去中心化
- Fully centralized:完全中心化
- Centralized training with decentralized execution:中心化学习,去中心化执行
在智能体系统中,一个智能体可能会或者不会观测到完整的状态,如果是完全可观察(Full observation),各智能体的观察值等同于状态,如果是部分可观察(Partial observation),每个智能体的观察值不等同于状态。
6.1 完全去中心化
Fully Decentralized是去中心化训练和执行,每个智能体都有自己的观察值和奖励用来学习自己的策略,智能体之间没有交流。以actor critic方法为例,每个智能体都有独立的策略网络和值网络,两个网络的输入输出都是基于自己观察的局部状态信息,智能体之间不会共享观察值和动作,和单一智能体学习方式是一样的,前文已经阐述过这种方式不可行。

6.2 完全中心化
Fully centralized是中心化训练和中心化执行,智能体将所有信息都发送给中央控制器,控制器会为所有智能体做决策。
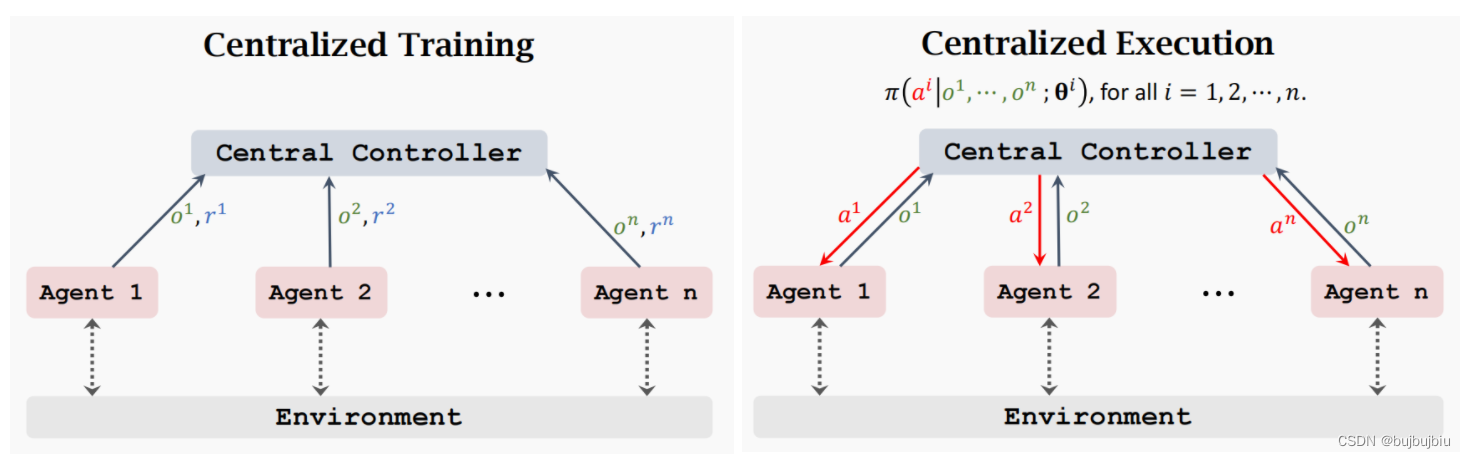
用Centralized Actor-Critic方法说明上述过程:在某时刻t,定义a为n个智能体的动作集合,o为n个智能体的观测集合,中央控制器(central controller)会获取到a,o和所有的奖励,控制器有n个策略网络和n个值网络,分别对应到每个智能体。每个策略网络输入是整体观测集合,输出对应智能体的动作。每个值网络输入是整体观测集合和整体动作集合,输出对应智能体策略值函数。中央控制器分别使用PG和TD更新所有的AC网络。在执行时,控制器会给予观测集合和n个策略网络随机采样n个动作给n个智能体。
这种方式缺点在于:所有智能体都要同时将观测值传给中央控制器,控制器再统一返回给每个智能体一个动作,智能体和控制器之间的通信和同步比较耗时,难以实现实时决策。

6.3 中心化学习+去中心化执行
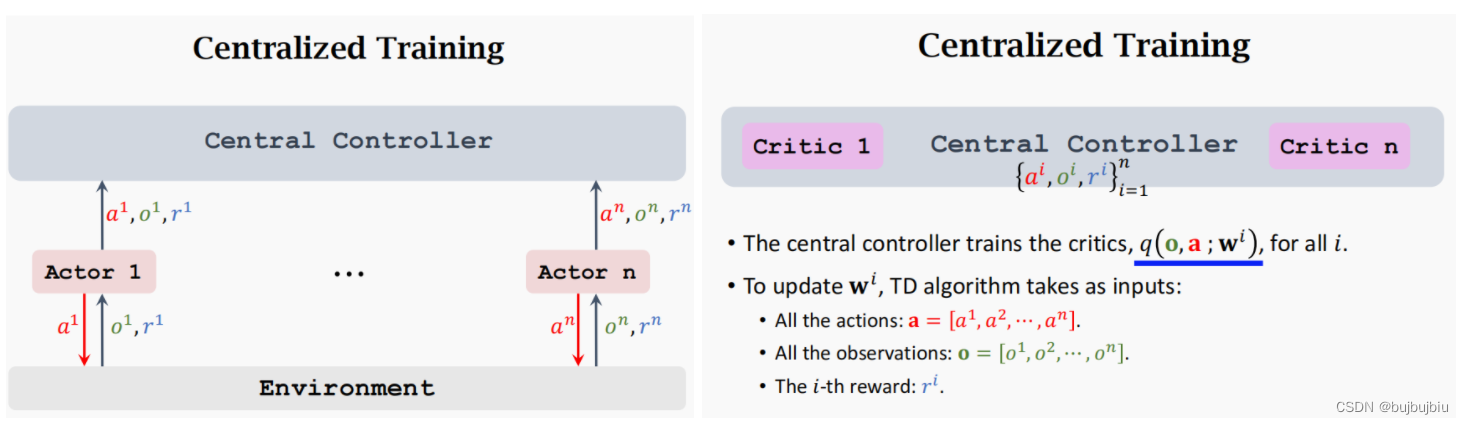
Centralized Training with Decentralized Execution在训练时使用中央控制器,在执行时弃用控制器。每个智能体有自己的策略网络,中央控制器有n个价值网络。也就是critic的更新是中央控制器负责,而actor的更新是各个智能体负责。
- Centralized Training:中央控制器会接受所有智能体的观测,动作和奖励,使用这些信息来更新n个价值网络,例如对于actor1的价值网络critic1,输入是观测集合,动作集合以及reward1,输actor1的值函数。actor1的策略网络以它自己的观测值,动作和控制器返回的值函数为输入更新策略。
- Decentralized Execution:actor与环境交互时只需输入它自己的观测值,基于自己的策略网络输入动作
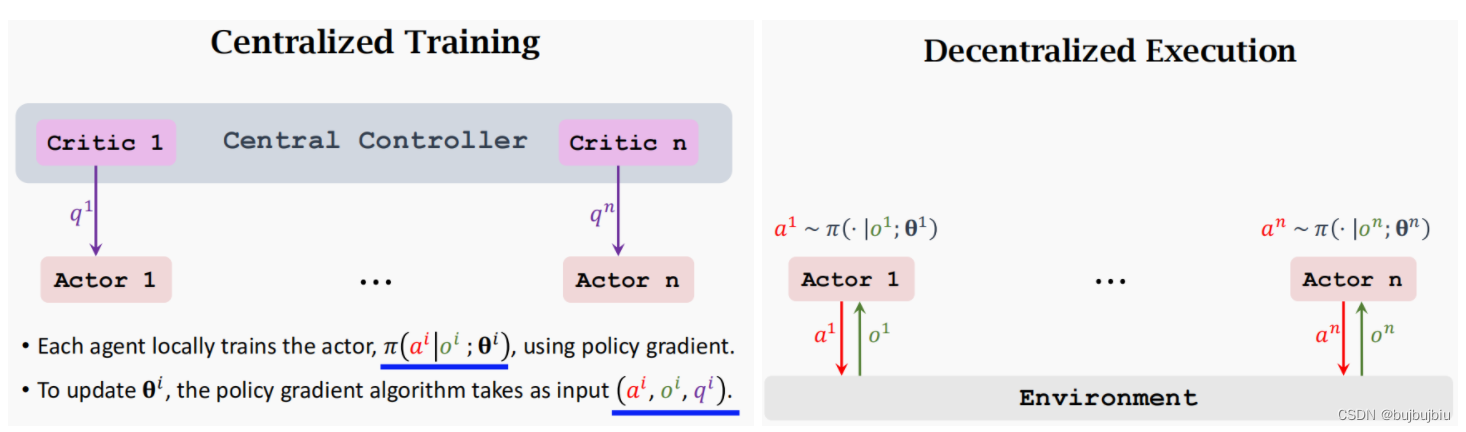
从上面描述可知,Centralized Training with Decentralized Execution即能保证训练的稳定性,也能保证执行的快速。
6.4 三种架构的对比总结
共同点:n个智能体,n个actor,n个critic
不同点:actor和critic的网络输入不同,训练方式不同

6.5 参数共享(Parameter Sharing)
所有actor和critic网络参数是否共享要考虑智能体是否可交换,比如在无人驾驶中每台车都可以是一样的策略,在机器人足球赛中,各个角色的策略都不同,是不能实现参数共享的。

相关论文:
Multi-Agent Actor-Critic for Mixed Cooperative-Competitive Environments
The Surprising Effectiveness of PPO in Cooperative, Multi-Agent Games