RDD的属性
-
一组分片(Partition),即数据集的基本组成单位。对于RDD来说,每个分片都会被一个计算任务处理,并决定并行计算的粒度。用户可以在创建RDD时指定RDD的分片个数,如果没有指定,那么就会采用默认值。默认值就是程序所分配到的CPU
Core的数目。 -
一个计算每个分区的函数。Spark中RDD的计算是以分片为单位的,每个RDD都会实现compute函数以达到这个目的。compute函数会对迭代器进行复合,不需要保存每次计算的结果。
-
RDD之间的依赖关系。RDD的每次转换都会生成一个新的RDD,所以RDD之间就会形成类似于流水线一样的前后依赖关系。在部分分区数据丢失时,Spark可以通过这个依赖关系重新计算丢失的分区数据,而不是对RDD的所有分区进行重新计算。
-
一个Partitioner,即RDD的分片函数。当前Spark中实现了两种类型的分片函数,一个是基于哈希的HashPartitioner,另外一个是基于范围的RangePartitioner。只有对于于key-value的RDD,才会有Partitioner,非key-value的RDD的Parititioner的值是None。Partitioner函数不但决定了RDD本身的分片数量,也决定了parent
RDD Shuffle输出时的分片数量。 -
一个列表,存取每个Partition的优先位置(preferred
location)。对于一个HDFS文件来说,这个列表保存的就是每个Partition所在的块的位置。按照“移动数据不如移动计算”的理念,Spark在进行任务调度的时候,会尽可能地将计算任务分配到其所要处理数据块的存储位置。
rdd三种创建方式:
由一个已经存在的集合创建
val rdd1: RDD[Int] = sc.parallelize(Array(1,2,3,4,5))
由外部存储文件创建 包括本地的文件系统,还有所有Hadoop支持的数据集,比如HDFS、 Cassandra、HBase等。
val rdd2: RDD[String] = sc.textFile("/words.txt")
由已有的RDD经过算子转换,生成新的RDD
val rdd3: RDD[String] = rdd2.flatMap(_.split(" "))
rdd常用的算子
transformation
-
map
val func1: Array[Int] = rdd1.map(_*2).collect println(func1.toBuffer) -
filter(func)
val arr2: RDD[String] = sc.parallelize(Array("xiaohong","xiaoli","xiaowang","dazhi"))
val filter1: RDD[String] = arr2.filter(name => name.contains("xiao"))
println(filter1.collect.toBuffer)
结果: ArrayBuffer(xiaohong, xiaoli, xiaowang)
- flatMap(func)
val arr3: RDD[Int] = sc.parallelize(1 to 5)
val flatMaparr3: RDD[Int] = arr3.flatMap(x => (1 to x))
println(flatMaparr3.collect.toBuffer)
结果:ArrayBuffer(1, 1, 2, 1, 2, 3, 1, 2, 3, 4, 1, 2, 3, 4, 5)
- mapPartitions(func) 、mapPartitionsWithIndex(func)
mapPartitions与map的区别:
map:将partition中的每个元素取出来,作用在map函数里边
mapPartitions:一次将partition中的所有元素取出来
val arr4: RDD[(String, String)] = sc.parallelize(List(("hehe","female"),("wang","female"),("zhang","male"),("luck","female")),3)
val result: RDD[String] = arr4.mapPartitions(partitionsFun)
val result1: RDD[String] = arr4.mapPartitionsWithIndex(partitionsFun1)
println(result1.collect.toBuffer)
- sample(withReplacement, fraction, seed) 、takeSample
这篇博客比较详细
https://blog.csdn.net/qq_21383435/article/details/77528042
var arr5: RDD[Int] = sc.parallelize(1 to 10)
val result: RDD[Int] = arr5.sample(false,0.1)
val result1: Array[Int] = arr5.takeSample(false,3)
println(result1.toBuffer)
结果: ArrayBuffer([0]hehe, [1]wang, [2]luck)
- union(otherDataset) 、intersection(otherDataset) 、distinct([numTasks]))
val arr6: RDD[Int] = sc.parallelize(1 to 5)
val arr7: RDD[Int] = sc.parallelize(3 to 7)
val arr8: RDD[Int] = arr6.union(arr7)
//println(arr8.collect.toBuffer) ArrayBuffer(1, 2, 3, 4, 5, 3, 4, 5, 6, 7)
val arr9: RDD[Int] = arr6.intersection(arr7)
//println(arr9.collect.toBuffer) ArrayBuffer(4, 3, 5)
val arr10: RDD[Int] = arr8.distinct()
//println(arr10.collect.toBuffer) ArrayBuffer(4, 1, 5, 6, 2, 3, 7)
- partitionBy
val arr11: RDD[(Int, String)] = sc.parallelize(Array((1,"nan"),(2,"bbb"),(3,"ccc"),(4,"ddd")),3)
//println(arr11.partitions.size)
结果:3
//重分区
val arr12: RDD[(Int, String)] = arr11.partitionBy(new HashPartitioner(2))
println(arr12.partitions.size)
结果:2
- reduceByKey(func, [numTasks])
val rdd1: RDD[(String, Int)] = sc.parallelize(List(("female",5),("male",6),("male",7),("female",4)))
val rdd2: RDD[(String, Int)] = rdd1.reduceByKey((x, y)=>x+y)
println(rdd2.collect.toBuffer)
结果:ArrayBuffer((female,9), (male,13))
- groupByKey
reduceByKey与groupByKey的区别,在于groupByKey只能生成一个sequence
val words = Array("one","two","one","three","two","one","three")
val wordPartition: RDD[(String, Int)] = sc.parallelize((words).map(x => (x,1)))
/*println(wordPartition.collect.toBuffer)
ArrayBuffer((one,1), (two,1), (one,1), (three,1), (two,1), (one,1), (three,1))*/
val wordGroupByKey: RDD[(String, Iterable[Int])] = wordPartition.groupByKey()
println(wordGroupByKey.collect.toBuffer)
ArrayBuffer((two,CompactBuffer(1, 1)), (one,CompactBuffer(1, 1, 1)), (three,CompactBuffer(1, 1)))
- combineByKey[C]
val scores = Array(("zhangsna",89),("zhangsna",79),("zhangsan",98),("lisi",78),("lisi",99),("lisi",65))
val input = sc.parallelize(scores)
val combine = input.combineByKey(
(v)=>(v,1),
(acc:(Int,Int),v)=>(acc._1+v,acc._2+1),
(acc1:(Int,Int),acc2:(Int,Int))=>(acc1._1+acc2._1,acc1._2+acc2._2)
)
//println(combine.collect.toBuffer)
//ArrayBuffer((zhangsan,(98,1)), (zhangsna,(168,2)), (lisi,(242,3)))
val avg = combine.map{
case (key,value) => (key,value._1/value._2.toDouble)
}
//println(avg.collect.toBuffer)
//ArrayBuffer((zhangsan,98.0), (zhangsna,84.0), (lisi,80.66666666666667))
- aggregateByKey(zeroValue:U,[partitioner: Partitioner]) (seqOp: (U, V)
=> U,combOp: (U, U) => U)
val rdd: RDD[(Int, Int)] = sc.parallelize(List((1,3),(1,2),(1,4),(2,4),(2,6),(5,8),(3,9)),1)
val rdd1: RDD[(Int, Int)] = rdd.aggregateByKey(0)(math.max(_,_),_+_)
//println(rdd1.collect.toBuffer)
//ArrayBuffer((1,4), (3,9), (5,8), (2,6))
key为1的分区为例,0先和3比较得3,3和2比较得3,3和4比较得4,(1,4)
key为2,0和4比较得4,4和6比较得6.
- foldByKey(zeroValue: V)(func: (V, V) => V): RDD[(K, V)]
val rdd: RDD[(Int, Int)] = sc.parallelize(List((1,3),(1,2),(1,4),(2,4),(2,6),(5,8),(3,9)),3)
val foldByKeyNum: RDD[(Int, Int)] = rdd.foldByKey(0)(_+_)
println(foldByKeyNum.collect.toBuffer)
ArrayBuffer((3,9), (1,9), (5,8), (2,10))
- sortByKey([ascending], [numTasks])
val rdd: RDD[(Int, String)] = sc.parallelize(Array((3,"aa"),(2,"bb"),(4,"ff")))
val result: RDD[(Int, String)] = rdd.sortByKey(true)
println(result.collect.toBuffer)
ArrayBuffer((2,bb), (3,aa), (4,ff))
- sortBy(func,[ascending], [numTasks])
val rdd: RDD[Int] = sc.parallelize(List(1,2,3,4))
val sortNum: RDD[Int] = rdd.sortBy(x=> x%3)
println(sortNum.collect.toBuffer)
ArrayBuffer(3, 1, 4, 2)
- join(otherDataset, [numTasks])

-
cogroup(otherDataset, [numTasks])

-
cartesian(otherDataset)

-
pipe(command, [envVars])
Shell脚本
#!/bin/sh
echo "AA"
while read LINE; do
echo ">>>"${LINE}
done

- coalesce(numPartitions)

- repartition(numPartitions)
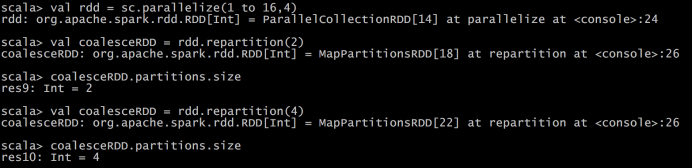
- repartitionAndSortWithinPartitions(partitioner)

- mapValues

- subtract
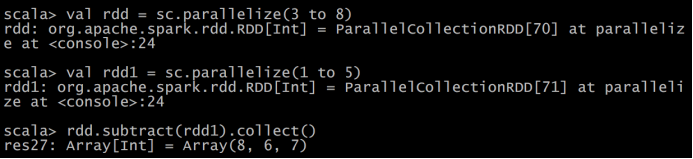
Action
- reduce(func)

- collect()

- count()

- first()

- take(n)

- takeSample(withReplacement,num, [seed])

- takeOrdered(n)

- aggregate (zeroValue: U)(seqOp: (U, T) ⇒ U, combOp: (U, U) ⇒ U)

- fold(num)(func)
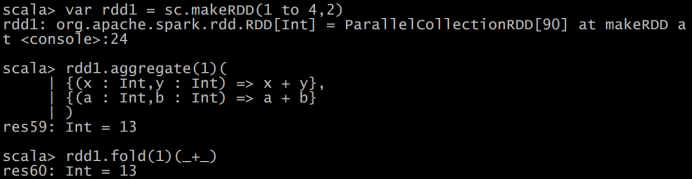
- saveAsTextFile(path)

- saveAsSequenceFile(path)

- saveAsObjectFile(path)

- countByKey()

- foreach(func)
foreach(func):在数据集的每一个元素上,运行函数func进行更新。
