在我的上一篇博客<<Explain检测SQL语句的性能>>中简单的介绍了explain关键字查询结果字段.这篇博客将介绍如何用正确使用索引提高查询效率.
索引用于快速找出在某个列中有一特定值的行。不使用索引,MySQL必须从第1条记录开始然后读完整个表直到找出相关的行。表越大,花费的时间越多。如果表中查询的列有一个索引,MySQL能快速到达一个位置去搜寻到数据文件的中间,没有必要看所有数据。注意如果你需要访问大部分行,顺序读取要快得多,因为此时我们避免磁盘搜索。
先来创建一张表:
- CREATE TABLE IF NOT EXISTS `article` (`id` int(10) unsigned NOT NULL AUTO_INCREMENT,
- `author_id` int(10) unsigned NOT NULL,
- `category_id` int(10) unsigned NOT NULL,
- `views` int(10) unsigned NOT NULL,
- `comments` int(10) unsigned NOT NULL,
- `title` varbinary(255) NOT NULL,
- `content` text NOT NULL,
- PRIMARY KEY (`id`)
- );
使用sql语句插入12条数据:
- INSERT INTO `article`
- (`author_id`, `category_id`, `views`, `comments`, `title`, `content`) VALUES
- (1, 1, 1, 1, '1', '1'),
- (2, 2, 2, 2, '2', '2'),
- (1, 1, 3, 3, '3', '3'),
- (4, 4, 4, 4, '4', '4'),
- (5, 5, 5, 5, '5', '5'),
- (4, 4, 6, 6, '6', '6'),
- (7, 7, 7, 7, '7', '7'),
- (8, 8, 8, 8, '8', '8'),
- (7, 7, 9, 9, '9', '9'),
- (1, 1, 1, 1, '1', '1'),
- (2, 2, 2, 2, '2', '2'),
- (1, 1, 3, 3, '3', '3');
测试:
查询 category_id为 4且 comments大于4的情况下,views最多的 article_id。
执行查询语句:

- SELECT *
- FROM `article`
- WHERE category_id =4 AND comments >4
- ORDER BY views DESC
查询时间

看到这个时间的时候是不是感觉挺快的.那么再用explain看看这条语句的性能:
- EXPLAIN
- SELECT *
- FROM `article`
- WHERE category_id = 4 AND comments >4
- ORDER BY views DESC
看到这个结果,type是all ,是最坏的情况,就需要进行优化了.最简单的方法就是添加索引,但是索引应该怎么添加呢?我们来看看:
查询条件之后共用了category_id,comments,views三个字段,那么就添加一个联合索引试试.
sql语句:
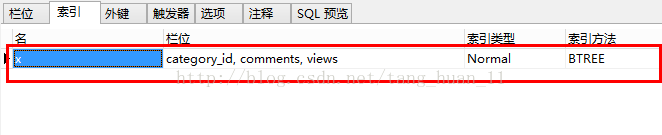
- ALTER TABLE `article` ADD INDEX x ( `category_id` , `comments`, `views` );
添加的索引:
看看执行语句所需要的时间:
我们再看看sql的性能:

type类型已经是range,但是情况还是很糟糕.
在表中已经建立了索引,但是效果为什么这么差呢?回头看看建立的索引方法,可以看到索引方法是B-Tree.B-Tree索引的工作原理:先排序category_id,如果遇到相同的category_id则再排序comments,如果遇到相同的comments则再排序views.当comments字段在联合索引里处于中间位置时,因comments>1条件是一个范围值,mysql无法再索引在对后面的views部分进行检索.现在我们需要抛弃comments,
先删除旧索引,再建立新索引:
- DROP INDEX x ON article;
- ALTER TABLE `article` ADD INDEX y ( `category_id` , `views` ) ;
索引结果:

再来看看sql语句的性能:

从结果中,我们可以看出type的类型是ref,结果是比较理想的.而且extra中的using filesort也消失了.
从整个过程中我们可以看出在小数据量的时候,从执行时间很难知道sql语句的性能如何,但是用explain关键字就可以检测出你的sql语句性能.从而我们也知道了添加索引的原则:
1.在作为查询条件的字段上添加索引,即跟在where后面的字段.
2.索引最好不要添加在查询条件为某个范围的字段上.