可复制集
mongoDB可复制集本质上是对主从复制模型的增强。在主从复制的基础上增加了自动化切主、平滑迁移的功能。
最小的可复制集群至少有3个节点,主、从节点和一个裁判节点。裁判节点不包含数据,只在主节点down后进行重新选主操作。
构建可复制集群
构建一个包含3个节点的集群。一个主节点,一个从节点,一个裁判节点。
mongod --replSet myrepl --dbpath /data/data1 --port 27017
mongod --replSet myrepl --dbpath /data/data2 --port 27018
mongod --replSet myrepl --dbpath /data/data3 --port 27019
在有数据的一个节点客户端(若都没数据则随便选一个)执行以下命令初始化集群。这里在27019节点操作。
rs.initiate(),在该节点初始化集群,此时集群只有一个这一个节点。- 使用
rs.add("host:port")添加其他节点。如rs.add('localhost:27018')添加从节点,使用rs.add("localhost:27017",true)添加裁判节点。
裁判节点可理解为轻量级的节点,不参与复制但参加主节点的选举。
复制操作时异步的。
一般来说,拥有最新optlog(或更高优先级的)节点可以称为主节点。
复制原理
复制操作依靠两个基础机制:(oplog)操作日志和(heartbeat)心跳检测完成。操作日志记录着所有的写操作,提供数据复制的依据,而心跳检测则用于触发故障转移。
oplog记录着所有写操作,为数据复制提供了基础(可以把它当做操作日志)。一般主节点完成写操作后会将写数据记录到oplog中。从节点再到主节点复制oplog,将新的更改应用到从节点(根据各自的时间戳应用)。
若集群只剩下主节点,则主节点会降级成从节点。
设置复制集群参数:
- votes,默认每个节点一票,可修改,但一般不会
- 可设置节点优先级(priority),值为0-100,便于选举时成为主节点,若为0,则不会称为主节点,通常用于灾难备份节点,另外对于灾难备份节点,可使用延迟复制(slaveDelay)功能。
分片集群
模型架构
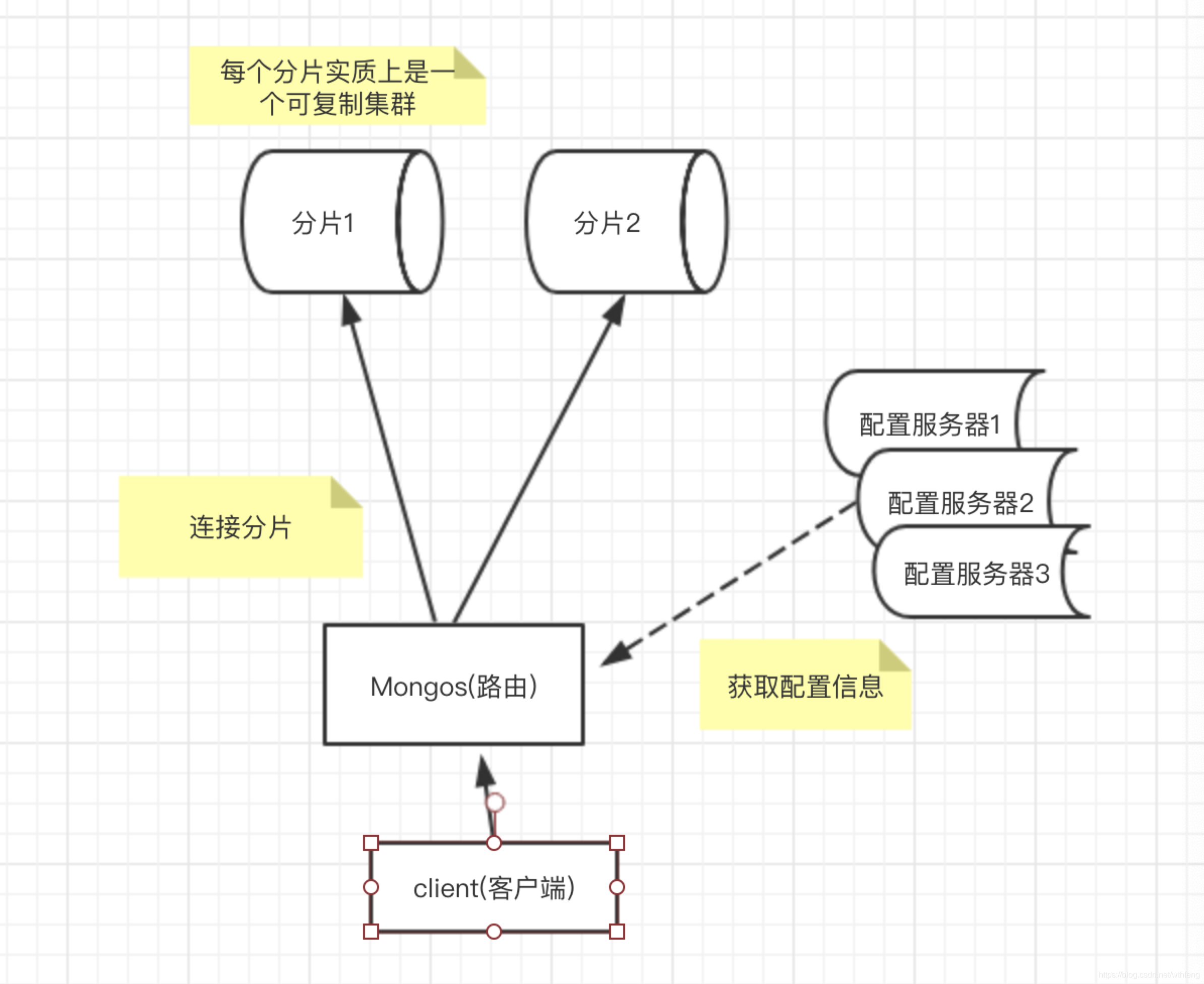
分片集群由若干分片、mongos(路由器)及配置服务器组成。其中,
- 一个分片本质上就是一个可复制集群,
- mongos负责消息路由,接收客户端请求。它本身不储存集群细腻系,没有持久化,所有配置信息向配置服务器请求。
- 配置服务器储存集群数据,数据库和集合的数据起始位置以及迁移记录。
对于分片集群而言,分片键的选取很重要。一般不要选择分布性查的字段,这样会导致数据都集中在一个分片上,无法利用分片集群的优势,但也不要选择完全随机的字段,这样会导致数据分布完全没有逻辑,无法利用局部性原理。查询会很费力。最好使用粗粒度+细粒度的复合分片键。如基于用户id和文档主键的分片键(userId+docId)。
| 方式 | 说明 | 特点 |
|---|---|---|
| 单机模式 | 一个mongod节点 | 无从节点,无高可用 |
| 主从 | 一个主节点和多个从节点组成 | 不能自动容灾,主节点down掉需人工重启维护,维护性查,不能高可用,目前已经不再应用 |
| 可复制集群 | 结构和主从一致,一个主节点点配置若干从节点或裁判节点 | 对主从结构的完善,当主节点挂掉后可自动选主节点,期间过程对用户透明,实现了高可用性 |
| 分片集群 | 有分片节点,路由节点和配置服务器集群组成,其中每个分片节点即是一个可复制集群 | 在可复制集群基础上添加了分片概念,可应对数据量过大的情况,结构也相对复杂。 |