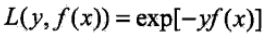Boosting是一项从多个弱分类器中构建强分类器的集成预测技术。它从训练数据中构建模型,然后通过修正前一个模型的错误创造出第二个模型。以此类推,模型不断叠加,直至能够完美预测训练数据集,或达到可添加的模型的数量上限。
在针对二元分类所开发的boosting算法中,AdaBoost是第一个成功的。(AdaBoost算法与决策树一起工作)
注意,这里Adaboost只能用于二分类,如果想应用与多分类/回归需要进行必要的变形
Adaboost最基本的性质就是通过更新样本权重来不断减少训练误差
它是理解boosting算法的最佳起点。现代boosting方法基于AdaBoost而构建,最典型的例子是随机梯度加速器。
Boosting是采用的对原始数据集D不断修改每个数据的权值来实现训练不同的基分类器,权值更新策略就采用的增大误分类样本的权值。
这样看来前期的数据清洗工作就非常有必要,因为噪声会对模型影响很大(对于噪声增大权值学习错误的样本)
鲁棒性差

最后整体的模型:
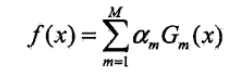
这里Adaboost还有一种解释方法:
 前向分步算法:
前向分步算法:
如果要是直接按照加法模型f(x)来进行求解,那损失函数求解太麻烦了
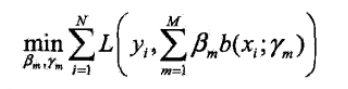
但是如果从前向后每一步就学系一个基函数和它的系数,那就好搬了
那么我们每次优化就求:
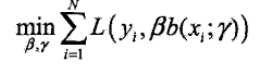
之后采用累加的形式

而Adaboost是前向分步算法的一个特例!
模型:加法模型
损失:指数函数损失