整个流程基本为从网上大牛的分享结合自己的理解所述,部分引用可能未粘贴链接。
Kernel启动流程中的Tips:
1、 Kernel一般会存在于存储设备上,比如FLASH\EMMC\SDCARD. 因此,需要先将kernel镜像加载到RAM的位置上,CPU才可以去访问到kernel。
但是注意,加载的位置是有要求的,一般是加载到物理RAM偏移0x8000的位置,也就是要在前面预留出32K的RAM。kernel会从加载的位置上开始解压,而kernel前面的32K空闲RAM中,16K作为boot params,16K作为临时页表
2、 Arch/arm/kernel/head.S(kernel的入口函数)
3、 bootloader需要通过设置PC指针到kernel的入口代码处(也就是kernel的加载位置)来实现kernel的跳转。
Some标记:
1)asmlinkage:表示函数不从寄存器传递参数,而是从栈传递
2)__visible:Tell the optimizer thatsomething else uses this function or variable
由__init*修饰的函数或者变量,只在开机阶段使用,占用的空间在系统完成后自行释放。
3)__init:标记内核启动时使用的初始化代码,内核启动完成后不再需要。以此标记的代码位于.init.text 内存区域
4)__initdata:标记内核启动时使用的初始化代码,内核启动完成后不再需要。以此标记的代码位于.init.data 内存区域
Start_Kernel():内核启动第二阶段入口 init/main.c
重要的点:
1、内核启动参数的获取和处理;
2、setup_arch(&command_line)函数;
3、内存管理的初化(从bootmem到slab);
4、rest_init()函数
asmlinkage __visible void__init start_kernel(void)
来自:https://www.cnblogs.com/yjf512/p/5999532.html
1、lockdep_init();kernel/kernel3.18/include/linux/lockdep.h
do{}while(0)什么都没做,作用暂未知。
2、set_task_stack_end_magic(&init_task);kernel/kernel3.18/kernel/fork.c
init_task:
1)为init_task_union结构体的成员,为系统的第一个进程,PID为0,唯一一个不用fork()创建的进程。其使用静态创建的方式生成,start_kernel之前的汇编代码到start_kernel执行,这里都会纳入idle进程的上下文(之前的汇编代码就是为了idle进程的执行做准备)。
2) 由宏“INIT_TASK(tsk)”初始化,方式:为task_struct结构体中的每个成员直接赋值
3)init进程,PID为1,在rest_init()中才被创建。
该函数主要用于指定init_task线程堆栈的结尾,设置标记STACK_END_MAGIC(防溢出操作)
3、smp_setup_processor_id();kernel/kernel3.18/arch/arm/kernel/setup.c
设置smp模型的处理器ID;SMP(多对称处理模型),指多个CPU之间地位平等,共享所有总线、内存、I/O,但也因此会造成抢占资源的问题。
4、boot_init_stack_canary();kernel/kernel3.18/arch/arm/asm/stackprotector.h
该函数也用于防止栈溢出(不是堆栈,是栈),该函数在局部变量和保存的指令指针之间设置一个标记位(canaryword)。当该位被修改后,即可探测到溢出,最后调用__stack_chk_fail函数,丢出错误退出进程。
参考:https://www.ibm.com/developerworks/cn/linux/l-cn-gccstack/
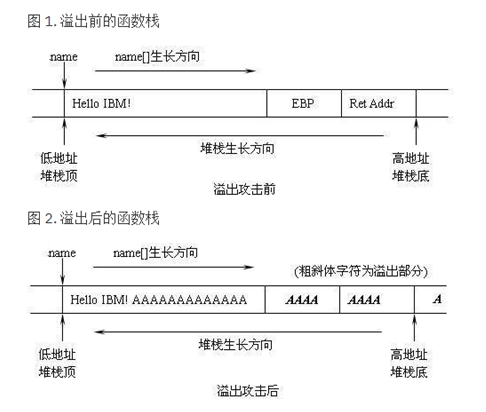
上图2中的EBP(堆栈帧指针,ESP为栈顶指针)和返回地址已经被覆盖,如果能在运行时检测出这种破坏,就有可能对函数栈进行保护。目前的堆栈保护实现大多使用基于 “Canaries” 的探测技术来完成对这种破坏的检测。详细见上述地址。
5、cgroup_init_early();kernel/kernel3.18/kernel/cgoup.c
参考:http://www.cnblogs.com/yjf512/p/6003094.html描述了Linux系统中的cgroup机制,部分截选如下:
我们把每种资源叫做子系统,比如CPU子系统,内存子系统。为什么叫做子系统呢,因为它是从整个操作系统的资源衍生出来的。然后我们创建一种虚拟的节点,叫做cgroup(controlgroup,一组进程的行为控制)。
进程分组css_set,不同层级中的节点cgroup也都有了。那么,就要把节点cgroup和层级进行关联,和数据库中关系表一样。这个事一个多对多的关系。为什么呢?首先,一个节点可以隶属于多个css_set,这就代表这这批css_set中的进程都拥有这个cgroup所代表的资源。其次,一个css_set需要多个cgroup。因为一个层级的cgroup只代表一种或者几种资源,而一般进程是需要多种资源的集合体。
Cgroup机制结构图如下:

结构体css_set中最重要的成员就是cgroup_subsys_statesubsys[]数组以及structcgroup_subsys_state *subsys[CGROUP_SUBSYS_COUNT];
task_struct->css_set->cgroup_subsys_state->cgroup反映了进程与cgroup之间的连接关系。
即该函数就是初始化这个cgroup机制。
6、local_irq_enable();关闭中断(底层调用汇编指令)
7、boot_cpu_init();初始化第一个CPU,并将当前CPU设置为激活状态
8、page_address_init();
页地址初始化的作用,未定义高端内存,代码为do{}while(0),不需要做任何操作,具体参考上述网址。
9、setup_arch(&command_line);
内核启动最重要的部分
参考:http://blog.csdn.net/qing_ping/article/details/17351541
http://www.it165.net/os/html/201409/9264.html
主要完成四个工作:
A)取得machine和processor的信息,然后赋值给kernel相应的全局变量
B)对boot_command_line和tags进行解析
C)memory和cache的初始化
D)为kernel后续运行请求资源
1. /*内核通过machine_desc结构体来控制系统体系架构相关部分的初始化。
2. machine_desc结构体通过MACHINE_START宏来初始化,在代码中,
3. 通过在start_kernel->setup_arch中调用setup_machine_fdt来获取。*/
每种体系结构都有自己的setup_arch()函数,是体系结构相关的,具体编译哪个 体系结构的setup_arch()函数,由源码树顶层目录下的Makefile中的ARCH变量决定
{
1)setup_processor();
首先从寄存器中读取cpuid,之后调用lookup_processor_type来取得proc_info_list
lookup_processor_type定义在head-common.S中,其实就是调用
__lookup_processor_type
2)mdesc =setup_machine_fdt(__atags_pointer);
主要工作:获取machine_desc结构体以及uboot传来的参数。
__atags_pointer即Uboot调用kernel时传递的第三个参数DTB首地址。如何指向的?
通过搜索该关键字,可在head-common.S中找到其定义,在对象__mmap_switched_data中,该对象被__mmap_switched调用,具体操作是通过将r3表示地址(__mmap_switched_data)中的内容依次存入相应的寄存器(r4~r7)中,在代码中,__atags_pointer地址被存入r6,之后再将uboot传来的第三个参数(第三个参数,所以在r2中)寄存器r2中的值赋值给r6,即实现__atags_pointer指向DTB首地址。
str r2, [r6]
验证DTB的有效性,主要为FDT的magic(参考kernel启动流程第一阶段的__vet_args)
调用of_flat_dt_match_machine接口:先获取DTB的根节点,通过循环遍历后续的节点进行匹配,找出最接近machine_desc结构.
调用early_init_dt_scan_chosen接口:扫描“/chosen/”下的节点,包括获取initrd相关的信息;bootargs相关的信息存入变量boot_command_line。
调用early_init_dt_scan_root接口:依据属性“#size-cells”获取相关信息。
3)setup_machine_tags():
若步骤2返回的mdesc结构为空(只有在验证时就失败返回的情况),则以__machine_arch_type为依据重新进行一次查找mdesc和boot_command_line。若仍未找到,则陷入死循环。
参考:http://www.360doc.com/content/13/0401/19/11635678_275349091.shtml
4)结构struct mm_struct管理进程的虚拟地址空间,所有内核线程都使用共同的地址空间,因为他们都是用相同的地址映射,这个地址空间由init_mm来描述。此处对init_mm结构体进行初始化,其中_text和_etext表示内核镜像代码的起始位置和结束位置,_etext 到_edata之间是已初始化数据段。_edata到_end时未初始化数据段等。_end后便是堆区。ps:每一个任务都有一个mm_struct结构以管理内存空间,init_mm是内核自身的mm_struct
5)parse_early_param:
看代码parse_one()中param为“early option”而params为NULL,所以理应在parameq判断条件时就返回了,最后直接调用传进来的函数调用(do_early_param)。
parse_early_param===>parse_one===>do_early_param===>proc_info_list.setup_func()
内容及原理比较混乱。
6)early_paging_init:
核心就是调用之前找到的mdesc中的init_meminfo()成员。
7)setup_dma_zone:
设置DMA区域的大小
8)arm_memblock_init():
将所有内存块添加到全局变量memblock中,该变量为结构体structmemblock类型,结构体memblock中存在两种类型的结构体,分别用于存储已使用的内存区(类型为reserve)和未使用的内存区(类型为memory)。其中,将已使用的内存(长度:_end- _stext)添加到reserve区中。
参考:http://blog.csdn.net/modianwutong/article/details/53162142
Linux内核使用伙伴系统管理内存,那么在伙伴系统工作前,如何管理内存?答案是memblock;
memblock在系统启动阶段进行简单的内存管理,记录物理内存的使用情况;
9)sanity_check_meminfo():
扫描各个内存块,检测低端内存的最大值arm_lowmem_limit,设置高端内存起始值的虚拟地址high_memory
10)paging_init(mdesc);
内核创建页表,初始化自举分配器。
11)request_standard_resources(mdesc);
内核中将许多物理资源用struct resource结构来管理,该函数就是将IO内存作为resource注册到内核
12)unflatten_device_tree();
解析FDT创建设备树节点。
后续暂留
}
10、mm_init_cpumask(&init_mm)
初始化CPU屏蔽字
mm.owner = &init_task
11、setup_command_line();
对cmdline进行备份和保存,均为分配的内存:
1、保存未改变的comand_line到字符数组static_command_line[] 中。
2、保存 boot_command_line到字符数组saved_command_line[]中
3、 初始化initcall_command_line变量用于后续使用
其中,command_line由boot_command_line拷贝得到,在setup_arch中进行此操作。
12、setup_nr_cpu_ids();
参考:http://blog.csdn.net/yin262/article/details/46778013
nr_cpu_ids全局变量被声明为__read_mostly属性。
nr_cpu_ids保存的是所有可处于联机状态的CPU总数。
nr_cpu_ids具有当前系统能具备的CPU数的信息,默认值为NR_CPUS值,NR_CPUS是编译时用户可设置的常量值。NR_CPUS并非当前系统内存在的CPU的数值,而是Linux内核能支持的最大CPU数的最大值。
三种系统中UP(Uni-Processor)中是1,32位SMP中具有2~32的值,64位内核中具有2~64位的值。
其中:
cpu_possible_mask:系统内可安装的最多CPU的位图
cpu_online_mask:系统内安装的CPU中,正在使用的CPU的位图
cpu_present_mask:系统内安装的CPU的位图
cpu_active_mask:处于联机状态且可以动的(migration)的CPU的位图
13、setup_per_cpu_areas();
setup_per_cpu_areas是为了对内核的内存管理(mm)进行初始化而调用的函数之一。只在SMP系统中调用,UP中不执行任何操作。
setup_per_cpu_areas函数为SMP的每个处理器生成per-cpu数据。
per-cpu数据按照不同的CPU类别使用,以将性能低下引发的缓存一致性(cachecoherency)问题减小到最小。per-cpu数据由各cpu独立使用,即使不锁也可访问,十分有效。
系统中维护的per_cpu数据是一个数据结构数组,其中每一个元素即每一个数据结构仅供一个CPU使用,不用担心竞争。
__per_cpu_offset数组中记录了每个CPU的percpu区域的开始地址。我们访问每CPU变量就要依靠__per_cpu_offset中的地址。
14、smp_prepare_boot_cpu();do nothing
15、build_all_zonelists();
建立系统内存页区(zone)链表
参考:http://blog.csdn.net/yuesichiu/article/details/8781272
用于初始化结点和内存域。该函数首先调用__build_all_zonelists,此函数遍历系统的每个内存结点(此处,遍历时每个节点pgdat= NODE_DATA(nid),最终为pgdat = &contig_page_data,从哪里体现出节点的不同,最终指向的都是同一个变量,why?),针对每个内存结点调用build_zonelists(),该函数的任务是在当前处理的结点和系统中其他结点的内存域之间建立一种等级次序。接下来,依据这种次序分配内存,如果在期望的结点内存域中,没有空闲内存,就去查找相邻结点的内存域。内核定义了内存的一个层次结构关系,首先试图分配廉价的内存,如果失败,则根据访问速度和容量,逐渐尝试分配更昂贵的内存。
该函数接下来计算所有剩余的内存页,存放到全局变量vm_total_pages中。接下来如果空闲内存页太少,则关闭页的可迁移性,即page_group_by_mobility_disabled置位。页的可迁移性是内核为了避免内存碎片而在linux2.6.24中加入的新特性。该特性把内存页分为不可移动内存页、可回收页和可移动页三种类型来避免内存碎片。
16、page_alloc_init();
内存页初始化
为系统设置一个page_alloc_cpu_notify回调函数,该函数用来实现CPU的关闭与使能。在一个MPP结构的处理器系统或者大型服务器中有大量的CPU,该函数可以临时打开或者关闭某些Core或者CPU,此时Linux系统会调用page_alloc_cpu_notify函数。
17、打印boot_command_line
18、parse_early_param();
解析早期格式的内核参数
19、parse_args("Bootingkernel", static_command_line, __start___param,
__stop___param - __start___param, -1, -1, &unknown_bootoption);
参考:http://blog.csdn.net/funkunho/article/details/51967137
函数对Linux启动命令行参数进行再分析和处理,
当不能够识别前面的命令时所调用的函数。
参考:http://blog.csdn.net/tommy_wxie/article/details/8041487
系统的所有参数都是由__setup(str,fn)和early_param(str,fn)宏定义的,两个宏都由一个宏实现:__setup_param(),实现如下:
#define __setup(str,fn) /
__setup_param(str, fn, fn, 0)
#define early_param(str,fn) /
__setup_param(str, fn, fn, 1)
可见唯一区别为最后的early标记是0还是1。为1则为early param,其表示需要在其他内核选项之前被处理(处理操作为调用18、 parse_early_param),若为0则由parse_args处理。
__setup()宏用于定义一个结构体(obs_kernel_param),并指定其放入“.init.setup”段,段头段尾分别为(__setup_start和__setup_end),因此解析参数的时候即可以通过从头遍历到尾,将其中的标记提取出来用来判断是否是early参数,之后对符合的参数,提取其结构体中的函数(定义时传入的fn)直接调用。
20、jump_label_init();
处理静态定义在跳转标号
21、setup_log_buf(0);
使用memblock_alloc分配一个启动时log缓冲区
参考:http://blog.csdn.net/ffmxnjm/article/details/70230958
22、pidhash_init(); // 初始化pid散列表
参考:http://blog.csdn.net/ongoingcre/article/details/50405356
设定Pid散列表的原因是:通过遍历进程双向链表来找到指定的进程效率太低,因此再维护一个hash表来提高查找效率
第一:分配系统支持最大的hash_table,以及长度,在此期间内核动态的为4个散列表分配空间,分别是PID(进程ID),TGID(线程组领头进程的PID),PGID(进程组领头进程的PID),SID(会话领头进程的PID)。
第二:根据得到的长度初始化pid_hash.
第三:hash表可能存在冲突的问题,因此在得到pid_hash后,初始化链表来解决冲突的问题。
23、vfs_caches_init_early(); // 初始化dentry和inode的hashtable
两个hash表的初始化的方式和pidhash_init()如出一辙,都是先分配空间,初始化hash表,再将对应的链表初始化。此函数为前期步骤,后续初始化为函数68。
24、sort_main_extable(); // 对内核异常向量表进行排序
25、trap_init(); // 对内核陷阱异常进行初始化,arm没有用到
26、mm_init(); // 初始化内核内存分配器,过度到伙伴系统,启动
//slab机制,初始化非连续内存区
参考:http://blog.csdn.net/sunlei0625/article/details/58594542
全局变量mem_map:描述系统中所有的物理内存采用的struct page结构的数组的基指针。比如说,对于4GB的内存(2^32)来说,如果一个页定义为4KB,即2^12字节。那么可想而知,总共这个mem_map数组大小为2^20个。
这些页都有一个具体的页帧号与之对应。页帧号一般用pfn来表示,那么由于每个页都有一个页帧号,那最小的页帧号和最大的页帧号为多少呢?需要特别注意的是,页帧号也是与mem_map数组的index相对应。我们一般认为pfn_min为0,而最大pfn_max为mem_map数组下标的最大值,这个最大值也就是max_pfn,这个值跟内核的max_mapnr相对应。
函数set_max_mapnr()就是用于计算max_mapnr。max_mapnr是在setup_arch的paging_init()中调用bootmem_init()来设置的。在成功设置max_mapnr后,我们要把启动过程时所有的空闲内存释放到伙伴系统,这里需要注意三点:
一. bootmem内存管理或者nobootmem管理
二. memblock内存管理
三. 伙伴系统
27、sched_init(); // 初始化进程调度器
根据系统的配置情况,分配空间并初始化root_task_group中的调度实体或调度队列指针。
将root_task_group添加到task_groups链表
。。。一系列初始化
init_idle(current,smp_processor_id()); // 将当前进程,即init_task设置为idle进程
current->sched_class = &fair_sched_class; // 设置当前进程,即init_task进程采用CFS调度策略
28、preempt_disable(); // 禁止内核抢占
if (WARN(!irqs_disabled(), "Interrupts wereenabled *very* early, fixing it\n"))
local_irq_disable(); // 关闭本地中断
29、idr_init_cache(); // 创建idr(整数id管理机制)高速缓存
IDR机制原理:
IDR机制适用在那些需要把某个整数和特定指针关联在一起的地方。例如,在IIC总线中,每个设备都有自己的地址,要想在总线上找到特定的设备,就必须要先发送设备的地址。当适配器要访问总线上的IIC设备时,首先要知道它们的ID号,同时要在内核中建立一个用于描述该设备的结构体,和驱动程序
将ID号和设备结构体结合起来,如果使用数组进行索引,一旦ID号很大,则用数组索引会占据大量内存空间。这显然不可能。或者用链表,但是,如果总线中实际存在的设备很多,则链表的查询效率会很低。
此时,IDR机制应运而生。该机制内部采用红黑树实现,可以很方便的将整数和指针关联起来,并且具有很高的搜索效率
30、rcu_init(); // 初始化rcu机制(读-写-拷贝)
31、trace_init(); //初始化系统的trace功能
32、context_tracking_init();//
33、radix_tree_init(); // 初始化内核基数树
/* init some links before init_ISA_irqs() */
Linuxradix树最广泛的用途是用于内存管理,结构address_space通过radix树跟踪绑定到地址映射上的核心页,该radix树允许内存管理代码快速查找标识为dirty或writeback的页。
Linux基数树(radix tree)是将指针与long整数键值相关联的机制,它存储有效率,并且可快速查询,用于指针与整数值的映射(如:IDR机制)、内存管理等。
34、early_irq_init(); // arm64没有用到
35、init_IRQ(); // 初始化中断
参考:http://blog.chinaunix.net/uid-12567959-id-160975.html
start_kernel()函数调用trap_init()、early_irq_init()和init_IRQ()三个函数来初始化中断管理系统。
1)trap_init()在arm平台下为空。
2)early_irq_init()函数在kernel/handle.c文件中根据内核配置时是否选择了CONFIG_SPARSE_IRQ,而可以选择两个不同版本的该函数中的一个进行编译。CONFIG_SPARSE_IRQ配置项,用于支持稀疏irq号,对于发行版的内核很有用,它允许定义一个高CONFIG_NR_CPUS值,但仍然不希望消耗太多内存的情况。
主要工作即为初始化用于管理中断的irq_desc[NR_IRQS]数组的每个元素,它主要设置数组中每一个成员的中断号,使得数组中每一个元素的kstat_irqs字段(irq stats per cpu),指向定义的二维数组中的对应的行。
alloc_desc_masks(&desc[i], 0, true)和init_desc_masks(&desc[i])函数在非SMP平台上为空函数。arch_early_irq_init()在主要用于x86平台和PPC平台,其他平台上为空函数。
3)init_IRQ(void)函数是一个特定于体系结构的函数,这个函数将irq_desc[NR_IRQS]结构数组各个元素的状态字段设置为IRQ_NOREQUEST| IRQ_NOPROBE,也就是未请求和未探测状态。然后调用特定机器平台的中断初始化init_arch_irq()函数。
36、tick_init(); // 初始化时钟滴答控制器
内部调用两个函数:tick_broadcast_init()和tick_nohz_init()
1)Linux的broadcasttimer机制:防止系统休眠时(CPU深度休眠也会关闭local timer),localtimer也休眠导致无法唤醒本CPU,所以添加了一个broadcast timer机制,用于在cpu休眠时负责唤醒。
详细参考:http://www.wowotech.net/timer_subsystem/tick-broadcast-framework.html
2)nohz时钟机制:
参考:http://blog.csdn.net/droidphone/article/details/8112948
Linux中的时钟事件都是由一个周期时钟提供,不管系统中的clock_event_device是工作于周期触发模式,还是工作于单触发模式,也不管定时器系统是工作于低分辨率模式,还是高精度模式,内核都竭尽所能,用不同的方式提供周期时钟,以产生定期的tick事件,tick事件或者用于全局的时间管理(jiffies和时间的更新),或者用于本地cpu的进程统计、时间轮定时器框架等等。周期性时钟虽然简单有效,但是也带来了一些缺点,尤其在系统的功耗上,因为就算系统目前无事可做,也必须定期地发出时钟事件,激活系统。为此,内核的开发者提出了动态时钟这一概念,我们可以通过内核的配置项CONFIG_NO_HZ来激活特性。有时候这一特性也被叫做tickless,不过还是把它称呼为动态时钟比较合适,因为并不是真的没有tick事件了,只是在系统无事所做的idle阶段,我们可以通过停止周期时钟来达到降低系统功耗的目的,只要有进程处于活动状态,时钟事件依然会被周期性地发出。
36+ rcu_init_nohz();
37、init_timers(); // 初始化内核定时器
参考:http://blog.csdn.net/sunnybeike/article/details/7016322
(1)初始化本 CPU 上的软件时钟相关的数据结构;
(2)向 cpu_chain 通知链注册元素 timers_nb ,该元素的回调函数用于初始化
指定 CPU 上的软件时钟相关的数据结构;
(3)初始化时钟的软中断处理函数。(会注册中断处理函数run_timer_softirq)
38、hrtimers_init(); // 初始化高精度时钟
39、softirq_init(); // 初始化软中断
软件中断的资源是有限的,内核目前只实现了10种类型的软件中断。定义在 include/linux/interrupt.h
该函数会调用open_softirq()初始化softirq_vet数组中的两个中断类型(每种中断类型对应一个数组元素,故该数组共有10个元素),分别为TASKLET_SOFTIRQ和HI_SOFTIRQ,指定softirq_vet[中断类型]中的action即中断处理函数。
补充:。内核为每个cpu都管理着一个待决软中断变量(pending),它就是irq_cpustat_t,每一位对应一个中断是否触发。疑问:变量为unsigned int类型,如何指定10种中断类型?
40、timekeeping_init(); // 初始化了大量的时钟相关全局变量
详细见:http://www.wowotech.net/timer_subsystem/timekeeping.html
41、time_init(); // 时钟初始化
与架构相关,其实就是调用板级初始化文件(arch/arm/mach-*/board-*.c)中定义“设备描述结构体”中的timer成员的初始化函数。
41+、sched_clock_postinit();
41++、perf_event_init();//软件性能分析工具初始化
42、profile_init(); // 初始化内核profile子系统,内核性能调试工具
43、call_function_init(); // smp下跨cpu的函数传递初始化
44、WARN(!irqs_disabled(), "Interrupts were enabledearly\n");
45、early_boot_irqs_disabled = false;
46、local_irq_enable(); // 使能当前cpu中断
47、kmem_cache_init_late();//完善slab分配器的缓存机制,对应于
//mm_init中的kmem_cache_init
后续可参考:http://blog.csdn.net/zdy0_2004/article/details/48852147
/*
* HACK ALERT! This is early. We're enablingthe console before
* we've done PCI setups etc, andconsole_init() must be aware of
* this. But we do want output early, in casesomething goes wrong.
*/
48、console_init();//初始化终端
依次调用__con_initcall_start到__con_initcall_end之间的函数,通过vmlinux.lds可以找到宏console_initcall(fn),该宏指定的函数调用register_console()接口实现console的初始化。
if (panic_later)
panic(panic_later, panic_param);
Linux内核在发生kernelpanic时会打印出Oops信息(哎呦),会将寄存器状态、堆栈内容和完整的Call trace都打印出来。
Oops信息的具体含义参考:https://www.cnblogs.com/wwang/archive/2010/11/14/1876735.html
后续均来自:http://www.360doc.com/content/15/0129/20/14530056_444817012.shtml
49、lockdep_info();//打印当前锁的依赖信息
/*
* Need to run this when irqs are enabled,because it wants
* to self-test [hard/soft]-irqs on/off lockinversion bugs
* too:
*/
50、locking_selftest();
#ifdef CONFIG_BLK_DEV_INITRD
if (initrd_start && !initrd_below_start_ok&&
page_to_pfn(virt_to_page((void*)initrd_start)) < min_low_pfn) {
pr_crit("initrd overwritten(0x%08lx < 0x%08lx) - disabling it.\n",
page_to_pfn(virt_to_page((void*)initrd_start)),
min_low_pfn);
initrd_start = 0;
}
#endif
检查initrd的位置是否符合要求。min_low_pfn是系统可用的最小的页帧号,即判断传递进来的initrd_start对应的物理地址是否正常,如果有误就清零。
51、page_cgroup_init();
52、debug_objects_mem_init();//Debug_objetcs机制的内存分配初始化
53、kmemleak_init();//内核内存泄漏检测机制初始化
54、setup_per_cpu_pageset();//设置每个CPU的页组,并初始化。此
//前只有启动页
55、numa_policy_init(); //非一致性内存访问(NUMA)初始化
if (late_time_init)
late_time_init();
56、sched_clock_init();//对每个CPU,初始化调度时钟
57、calibrate_delay(); //计算BogoMIPS值,他是衡量一个CPU性能的标识
58、pidmap_init(); //PID分配映射初始化
59、anon_vma_init(); //匿名虚拟内存域(anonymous VMA)初始化
60、acpi_early_init();
#ifdef CONFIG_X86
if (efi_enabled(EFI_RUNTIME_SERVICES))
efi_enter_virtual_mode();
#endif
61、thread_info_cache_init();//获取thread_info缓存空间,arm为空
62、cred_init();//任务信用系统初始化。详见:Documentation/credentials.txt
63、fork_init(totalram_pages);//进程创建初始化。为内核“task_struct”分配空间,计算最大任务数
64、proc_caches_init();//初始化进程创建机制所需的其他数据结构,为其申请空间。
65、buffer_init();//缓存系统初始化,创建缓存头空间,并检查其大小限时。
66、key_init(); //内核密钥管理系统初始化
67、security_init();//内核安全框架初始化
68、dbg_late_init();//内核调试系统后期初始化
69、vfs_caches_init(totalram_pages);//虚拟文件系统缓存初始化
70、signals_init();//信号管理系统初始化
/* rootfs populating might need page-writeback */
page_writeback_init();//页回写机制初始化
#ifdef CONFIG_PROC_FS
proc_root_init();//proc文件系统初始化
#endif
71、cgroup_init();//control group的正式初始化
72、cpuset_init();//cpuset初始化
73、taskstats_init_early();//任务状态早期初始化函数:为结构体获
//取高速缓存,并初始化互斥机制
74、delayacct_init();//任务延迟机制初始化
75、check_bugs();//检查CPU BUG的函数,通过软件规避BUG
76、acpi_subsystem_init();//ACPI(高级配置和电源接口)
77、sfi_init_late();
if (efi_enabled(EFI_RUNTIME_SERVICES)) {
efi_late_init();
efi_free_boot_services();
}
78、ftrace_init();
/* Do the rest non-__init'ed, we're now alive */
79、rest_init();
{
1)start_sheduler_starting();
打开RCU(rcu_scheduler_active标志置1),从该函数后所有RCU事件都将被响应;
2)调用kernel_thread();
创建kernel_init线程(线程号为1),kernel_init线程的第一个函数kernel_init_freeable()会调用wait_for_completion接口,等待一个条件触发,条件就是kthreadd_done。
3)numa_default_policy();设定NUMA系统的内存访问策略:意图未知
4)再次调用kernel_thread();创建kthreadd线程,其作用是管理和调度其他的内核线程。
Kthreadd:调度其他线程步骤如下:
设置内核环境;
在for循环内:
{
A、set_current_state(TASK_INTERRUPTIBLE);
设置线程为“挂起”状态(直到调用schedule()才真正的释放CPU)
TASK_INTERRUPTIBLE : 这是针对等待某事件或其他资源而睡眠的进程设置的。在内核发送信号给该进程时表明等待的事件已经发生或资源已经可用,进程状态变为 TASK_RUNNING,此时只要被调度器选中就立即可恢复运行。
其他标志的具体含义参考:http://blog.csdn.net/johnyuan1988/article/details/9166873
set_current_state()的使用:
在驱动程序中,进程睡眠往往通过 3 个步骤进行:
1. 将进程加入等待队列中。
2. 然后使用 set_current_state() 来设置进程的状态,设置的状态为 TASK_INTERRUPTIBLE 或TASK_UNINTERRUTIBLE 。
3. 上面的设置完后,我们就要放弃处理器了。但在放弃处理器之前,还有一件重要的事情需要做:检查睡眠等待的条件。如果不检查,如果此时条件正好变为真,那么就漏掉了继续运行的机会,从而会睡眠更长的时间。就好比如,你在等一辆车,你觉得车还没来,你很困并就打算先睡一会儿,此时有一辆车刚好过来了,你睡眼朦胧的并没打算睁开眼睛去看一下,结果得花更长的时间来等下一趟。所以,一般在睡前需要类似的动作。
不检查睡眠等待条件的应用参考:http://blog.csdn.net/cosmoslhf/article/details/50481758
B、按照上述3中所述,在set_current_state后需要检查条件,此处的条件为查看kthread_create_list全局链表(维护内核线程)是否为空。若为空则不满足,直接进行执行schedule()函数;真正的释放CPU将本线程挂起并等待内核信号唤醒。
C、若不为空则无需调度,重新将进程置为TASK_RUNNING状态。之后在while循环(循环的条件是当前内核线程链表中不为空)中进行如下操作:
1)先将链表中的下一个元素进行从链表上摘除
2)调用create_kthread:创建一个kthread线程,传入的参数为这个被摘除的链表元素指针。
}
总结:kthreadd线程主要负责对线程队列中的线程进行调度和运行。
5)在RCU锁的保护中执行find_task_by_pid_ns():
参考:http://blog.csdn.net/tiantao2012/article/details/78621421
1. 这个函数基本分成两步,第一步,通过形参nr和ns让find_pid_ns找到struct pid。然后
2. 再让pid_task 根据struct pid和type返回对应的task
6)调用complete()唤醒kernel_init中等待的条件(kernel_init线程中会调用wait_for_completion()等待条件kthread_done条件完成)。
问:是否立即唤醒?还是需要等待本线程释放?
Complete详细用法具体参考:http://blog.csdn.net/wealoong/article/details/8490654
7)设置当前进程为idle进程。
问:函数27sched_init()中已经调用了init_idle()不是已经将该进程设置为idle进程了么?
8)schedule_preempt_disabled();
里面执行了三个函数,分别为:开启内核抢占;schedule()调度;关闭抢占
具体要做什么不清楚。
9)cpu_startup_entry()。
kernel_init处理流程如下:
参考:http://blog.chinaunix.net/uid-20543672-id-3172321.html
参考:http://www.wfuyu.com/mvc/25670.html
1、执行kernel_init_freeable();
1)调用wait接口等待条件(kthreadd完成,rest_init中置位)。
2)__GFP_BITS_MASK;设置bitmask,使得init进程可使用PM并且允许I/O阻塞操作。
3)初始化可在任何node分配到内存页。
4)通过设置cpu_bit_mask,可以限定task只能在特定的处理器上运行, 而current进程此时必定是init进程,设置其cpu_all_mask即使得init进程可以在任意的cpu上运行。
5)设置到目前运行进程init的pid号给cad_pid{cad_pid是用来接收ctrl-alt-del rebootsignal的进程, 如果设置C_A_D=1就表示可以处理来自ctl-alt-del的动作,最后会调用 ctrl_alt_del(void)并确认C_A_D是不是为1,确认完成后将履行cad_work=deferred_cad,履行kernel_restart}
6)smp_prepare_cpus()函数是体系结构相干的函数,实例在arch/arm/kernel/smp.c中,调用smp_prepare_cpus时,会以全局变量setup_max_cpus为函式参数max_cpus,以表示在编译核心时,设定支援的最大CPU数量。
7)do_pre_smp_initcalls()
函数会遍历Symbol中__initcall_start与__initcall0_start之间的函数,并调用do_one_initcall(fn)依次执行。
通过查看arch/arm/kernel/vmlinux.lds.S可看到宏“INIT_CALLS”找到对应的vmlinux.lds.h文件中的定义,可知为*(.initcallearly.init)段
详细可参考:
http://blog.163.com/ericxia_gnikam/blog/static/969208792008102441621546/
8)smp_init():
实例在kernel/smp.c中, 函数主要是由Bootstrap处理器,进行Active多核心架构下其它的处理器. 如果产生Online的处理器个数(fromnum_online_cpus)超过在核心编译时,所设定的最大处理器个数setup_max_cpus (from NR_CPUS),就会终止流程.如果该处理器目前属於Present(也就是存在系统中),但还没有是Online的状态,就会呼唤函式cpu_up(inkernel/cpu.c)来啟动该处理器.
9)sched_init_smp():未懂
10)do_basic_setup():下文
11)打开根文件系统中的/dev/console,再重复两次sys_dup(0),对应0,1,2标准输入,输出,错误
12)判断是否存在/init,存在则向下走,不存在则走prepare_namespace挂载文件系统。
13)load_default_modules():加载基本的模块
2、async_synchronize_full():
在这函数中会等待List async_running与async_pending都清空后,才会返回.Asynchronously called functions主要设计用来加速Linux Kernel开机的效力,避免在开机流程中等待硬体反应延迟,影响到开机完成的时间。
3、free_initmem():
释放Linux Kernel介於__init_begin到__init_end属于init Section的函数的所有内存.并会把Page个数加到变量totalram_pages中,作为后续LinuxKernel在配置记忆体时可使用的Pages. (在这也可把TCM范围(__tcm_start到__tcm_end)释放加入到总Page中,但TCM比外部记忆体有效力,合适多媒体,中断,…etc等对效能要求高的履行需求,放到总Page中,成为可供1般目的配置的存储范围
4、mark_readonly():
标记内核数据只读
5、numa_default_policy():
恢复当前进程的内存策略为默认状态。
6、加载init进程,进入用户空间
a,如果ramdisk_execute_command不為0,就履行该命令成為init User Process.
b,如果execute_command不為0,就履行该命令成為init User Process.
c,如果上述都不成立,就依序執行以下指令
run_init_process(“/sbin/init”);
run_init_process(“/etc/init”);
run_init_process(“/bin/init”);
run_init_process(“/bin/sh”);
也就是说会依照顺序从/sbin/init,/etc/init, /bin/init 與 /bin/sh依序履行第1个 init User Process.
如果都找不到可以執行的 initProcess,就會進入Kernel Panic.以下所示panic(“No init found. Try passing init= option to kernel. ”“See Linux Documentation/init.txt for guidance.”);
do_basic_setup():
参考:http://www.mamicode.com/info-detail-1063855.html
{
1、cpuset_init_smp(); //初始化内核cgroup的cpuset子系统。
针对SMP系统,初始化内核controlgroup的cpuset子系统。如果非SMP,此函数为空。
cpuset是在用户空间中操作cgroup文件系统来执行进程与cpu和进程与内存结点之间的绑定。
本函数将cpus_allowed和mems_allwed更新为在线的cpu和在线的内存结点,并为内存热插拨注册了钩子函数,最后创建一个单线程工作队列cpuset。
2、usermodehelper_init();
创建一个单线程工作队列khelper。运行的系统中只有一个,主要作用是指定用户空间的程序路径和环境变量, 最终运行指定的userspace的程序,属于关键线程,不能关闭。
3、shmem_init();
Tmpfs文件系统初始化
4、driver_init();
初始化驱动模型中的各子系统,可见的现象是在/sys/中出现的目录和文件。
包括:
初始化devtmpfs文件系统,驱动核心设备将在该文件系统中添加设备节点;
初始化驱动模型中的部分子系统和kobject;
初始化bus子系统、class子系统、firmware子系统、hypervisor子系统;
初始化bus/platform子系统;devices/system/cpu子系统;devices/system/memory子系统;
问:此处的driver初始化和后期的do_initcalls中的驱动初始化有何区别?
5、init_irq_proc();
在proc文件系统中创建irq目录(mkdir/proc/irq),并在其中初始化系统中所有中断对应的目录(mkdir /proc/irq/xxx,xxx为中断类型对应的整数)。
6、do_ctors();
#ifdefCONFIG_CONSTRUCTORS
根据链接脚本的内容,依次调用__ctors_start到__ctors_end之间的内容(包括*(.ctors) 和 *(.init.array) 段)
7、usermodehelper_enable();
调用wake_up(&usermodehelper_disabled_waitq)唤醒等待队列===>打开用户态helper进程。
8、do_initcalls();//调用所有编译内核的驱动模块的初始化函数
依次调用注册的initcall函数,详细的分析流程参考:
http://www.cnitblog.com/zouzheng/archive/2008/08/08/47772.html
注:
1、不同level等级的initcall.initsection本身有一定的执行顺序,因此如果驱动依赖于特定的执行顺序的话需要考虑到这一点。
2、在编写内核模块的时候需要注意顺序,比如你编写的模块使用的是I2C的API,那你的模块的初始化函数的级别必须低于I2C子系统初始化函数的级别(也就是级别数(1~7)要大于I2C子系统)。如果编写的模块必须和依赖的模块在同一级,那就必须注意内核Makefile的修改了。
上述链接描写详细,但代码版本不同,代码有些许差异,通过链接中提到的方法查找不能一次查找到。
1)通过grep –rn“\.initcall*\.init” kernel/kernel3.xx/ 查找目录下对应的内容.initcallxx.init段的内容,结果未找到有价值的宏定义。因此宏定义肯定不以“.initcall##id##.init”的方式定义。
2)扩大搜索范围,直接查找“__initcall”,发现如下三行:
#define __initcall(fn) __define_initcall(“1”, fn)
#define __initcall(fn) device_initcall(fn)
#define module_init(x) __initcall(x);
显然定义层层递进,最终可找到__define_initcall(“1”,fn),参数有数字,故推测__define_initcall宏很可能可以定义.initcall0~7.init的段,其中数字由参数决定。
3)根据猜测查找__define_initcall,找到kernel/kernel-3.18/include/linux/init.h中有其定义,如下:
#define__define_initcall(fn, id) \
static initcall_t __initcall_##fn##id __used \
__attribute__((__section__(“.initcall” #id”.init”)))= fn;\
LTO_REFERRENCE_INITCALL(__initcall_##fn##id)
其中一个“#”表示将参数转化为字符串(两个#表示连接前后两个串),且其中的空格在字符串连接后会被自动忽略(测试发现多个空格均会忽略)。
最终成功找到一个宏定义将其内容安置在.initcallxx.init段中,发现格式为“.initcall”#id ”.init”所以之前搜索“\.initcall*\.init”时找不到。
4)后续阅读只需通过查找__define_initcall的引用即可继续。
9、random_int_secret_init();
}