本文是通过学习李运华老师的《从0开始学架构》课程的随笔
读写分离
读写分离应用场景,写少读多
本质是将访问压力分配到不同的节点上,并没有减轻存储压力、空间换时间;
应优先考虑如:硬件优化、数据库服务器调优、程序调优、数据库操作调优、表优化等方案。
基本实现
1、数据库服务器搭建主从集群(多个服务器),一主N从;
2、数据库主机服务读写操作,从机负责读操作;
3、数据库主机通过复制将数据同步到从机,每台数据库服务器都存储了所有的业务数据;
4、业务服务器将写操作发送给主机,读操作发送给从机;
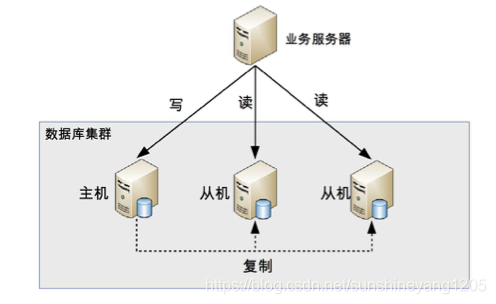
该图片来源于课程《从0开始学架构》
复杂度
(1)、复制延迟
数据库主服务器将数据同步至数据库从服务器时候延迟
解决常见方法
a、写操作后的读操作,指定发给数据库主服务器;
缺点:业务强绑定,如果对代码规范不了解,很容易造成bug;
b、“二次读取”,读数据库从服务器失败后,读一次数据库主服务器;
缺点:如果有很多二次读取,将增大数据库主服务器的压力;
c、关键业务全部读写操作全部指向数据库主服务器,非关键业务采用读写分离;
(2)、分配机制
一般两种方式:程序代码封装和中间件封装
程序代码封装
指在代码中抽象一个数据访问层,实现读写操作分离和数据库服务器连接的管理,基本架构为:
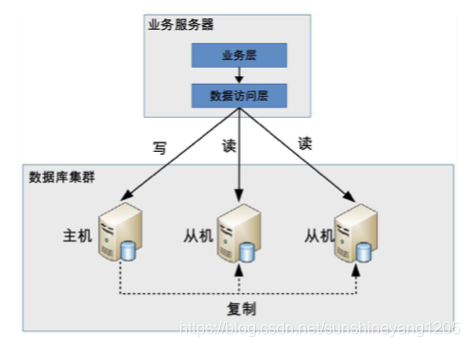
该图片来源于课程《从0开始学架构》
中间件封装
指独立一套系统出来,实现读写操作分离和数据库服务器连接的管理。
分库分表
业务分库
按照业务模块将数据分散到不同的数据库服务器
复杂度:
1、join操作
2、事务问题
3、成本问题
分表
水平拆分
表行数据特别大的表拆分为另外一张表
复杂度:
1、路由:某条数据属于切分后的哪张表,需要增加路由算法进行计算
一般建议分段在100W至2000W之间
(1)、范围路由
例:ID值为1-9999999位数据库1的表;值为10000000-99999999为数据库2的表,以此类推。
优点:可随着数据的增加平滑地扩充新的表
缺点:数据分布不均匀,一张表可能100W,另一张表可能未1000条;
(2)、Hash路由
根据某个列或某几列组合的值进行Hash运算,根据Hash结果将数据分散到不同的数据库表中;
例:ID%10的值来计算 101的数据分配在数据库1的表 102的数据分配在数据库2的表,以此类推。
优点:数据分布均匀
缺点:扩充很麻烦,扩充表的时候,所有数据需要重新分配分布。
(3)、配置路由
配置路由即路由表,用路由表(独立的表)来记录路由信息;
例:新增用户,则路由表新增一条数据,记录了用户ID和表ID,通过用户ID可查询到对应的表。
优点:扩张容易;扩充表,只需要迁移指定数据,并修改路由表即可
缺点→复杂度:
(a)、join操作:查询一个分部在多个表的结果,则需要业务代码或中间件中多次join合并结果。
(b)、count操作:如分页时候就需要获取count
count相加或记录数表(新增一张表,记录表的和,没新增或减少一条数据,则记录表的值增1或减1→这个操作也可以用定时更新)
©、orderby排序:原一个表完成排序返回,现需要业务代码或中间件查询排序再返回。
垂直拆分
列拆分
将表中不常用且占用了大量控件的列拆分为另外一张表
复杂度:表操作的数量增加(原查1张表,现查2张表)
相关可参考博文:
1、https://blog.csdn.net/liming850628/article/details/50723304
2、https://blog.csdn.net/ExceptionalBoy/article/details/78851327
3、https://www.cnblogs.com/marvin/p/4123745.html