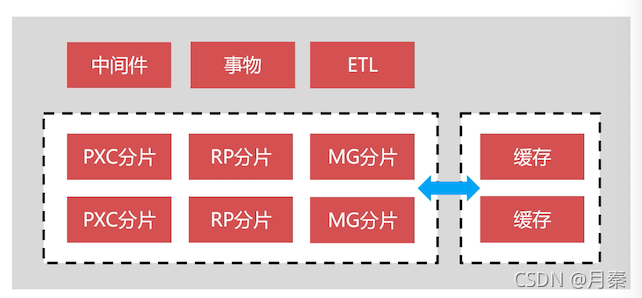
pxc集群:每个节点都必须同步接受数据,适合保存强一致性数据。
rp集群:每个节点时异步接受数据的,不适合保存强一致性数据。
只要一个结点成功接受数据,那么事务就算成功了,如果由于网络原因,读写分离的情况下,就可能导致扣款成功,但是订单状态同步失败的问题。
如果一个请求既操作了pxc又操作了rp的数据,这种夸集群的事务就很难实现。
快速分页优化:
对上千万行的记录进行查找
neti> select id,name from t_test limit 100,100
[2020-06-07 20:09:52] 100 rows retrieved starting from 1 in 37 ms (execution: 9 ms, fetching: 28 ms)
neti> select id,name from t_test limit 10000,100
[2020-06-07 20:10:06] 100 rows retrieved starting from 1 in 48 ms (execution: 15 ms, fetching: 33 ms)
neti> select id,name from t_test limit 1000000,100
[2020-06-07 20:10:15] 100 rows retrieved starting from 1 in 362 ms (execution: 336 ms, fetching: 26 ms)
neti> select id,name from t_test limit 5000000,100
[2020-06-07 20:10:21] 100 rows retrieved starting from 1 in 1 s 244 ms (execution: 1 s 220 ms, fetching: 24 ms)
neti> select id,name from t_test limit 9000000,100
[2020-06-07 20:11:44] 100 rows retrieved starting from 1 in 2 s 247 ms (execution: 2 s 221 ms, fetching: 26 ms)
可以看到越往后面,查询时间越久。
优化方法:
利用主键索引来加速分页查询(前提是主键必须是连续的)
neti> select id,name from t_test where id > 9000000 limit 100
[2020-06-07 20:13:52] 100 rows retrieved starting from 1 in 60 ms (execution: 26 ms, fetching: 34 ms)
该方法还需要查找9000000 以后的数据再显示前100条数据
neti> select id,name from t_test where id > 9000000 and id <= 9000000+100
[2020-06-07 20:15:33] 100 rows retrieved starting from 1 in 42 ms (execution: 10 ms, fetching: 32 ms)
该方法直接限定搜索区间,查询速度更快
SQL语句的优化
1.不要把select语句写成select*
返回结果集数量太多了
需要先读取表结构,换成字段名称
2.谨慎使用模糊查询
%写在左边,无法使用左前缀索引查询
3.对order by排序的字段设置索引
索引是二叉树机制,索引建立就是有序的,所以不用做额外的排序计算
4.少用is null和is not null
会让mysql跳过索引,进行全表查询
null值无法进行排序,所以不会记录在二叉树里面,所以与null值有关的判定都不会邹索引。
5.少用!=运算符
无法利用二叉树机制,无法走索引
6.尽量少用or运算索引
同样会让索引失效,or之前的会走索引,之后就无法走索引
7.避免条件语句中的数据类型转换
8.在表达式左侧使用运算符和函数都会让索引失效