1.autograd自动微分
假如我们有一个向量x=(1,1)当成input,经过一系列运算得到了output变量y,如下图所示:

如图所示,向量x经过与4和自身相乘之后得到向量z,z再求长度,得到y
我们想要求y关于x的微分时,pytorch会帮我们自动求解。
from torch.autograd import Variable
import torch
x = Variable(torch.ones(2), requires_grad = True) #vairable是tensor的一个外包装
z=4xx
y=z.norm()
y
Variable containing:
5.6569
[torch.FloatTensor of size 1]
我们可以看到y的值与我们上图计算的结果一致
需要注意:autograd是专门为了BP算法设计的,所以这autograd只对输出值为标量的有用,因为损失函数的输出是一个标量。如果y是一个向量,那么backward()函数就会失效。不知道BP算法是什么的同学,估计也不知道什么是深度学习,建议先看Zen君提供的教材。
2.autograd的内部机理
我们之所以可以实现autograd多亏了Variable和Function这两种数据类型的功劳。要进行autograd必需先将tensor数据包成Variable。Varibale和tensor基本一致,所区别在于多了下面几个属性。
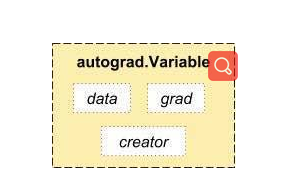
variable是tensor的外包装,variable类型变量的data属性存储着tensor数据,grad属性存储关于该变量的导数,creator是代表该变量的创造者
variable和function它们是彼此不分开的,先上图:
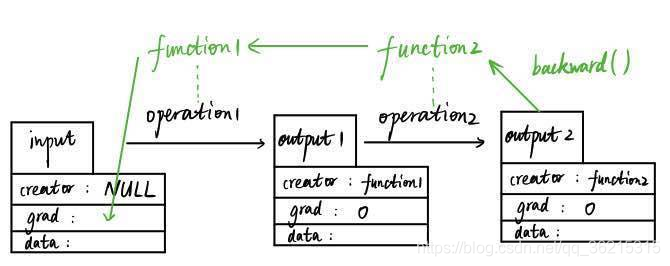
数据向前传输和向后传输生成导数的过程示意图
如图,假设我们有一个输入变量input(数据类型为Variable)input是用户输入的,所以其创造者creator为null值,input经过第一个数据操作operation1(比如加减乘除运算)得到output1变量(数据类型仍为Variable),这个过程中会自动生成一个function1的变量(数据类型为Function的一个实例),而output1的创造者就是这个function1。随后,output1再经过一个数据操作生成output2,这个过程也会生成另外一个实例function2,output2的创造者creator为function2。
在这个向前传播的过程中,function1和function2记录了数据input的所有操作历史,当output2运行其backward函数时,会使得function2和function1自动反向计算input的导数值并存储在grad属性中。
creator为null的变量才能被返回导数,比如input,若把整个操作流看成是一张图(Graph),那么像input这种creator为null的被称之为图的叶子(graph leaf)。而creator非null的变量比如output1和output2,是不能被返回导数的,它们的grad均为0。所以只有叶子节点才能被autograd。