Attention:
深度学习里的Attention model其实模拟的是人脑的注意力模型,举个例子来说,当我们观赏一幅画时,虽然我们可以看到整幅画的全貌,但是在我们深入仔细地观察时,其实眼睛聚焦的就只有很小的一块,这个时候人的大脑主要关注在这一小块图案上,也就是说这个时候人脑对整幅图的关注并不是均衡的,是有一定的权重区分的。这就是深度学习里的Attention Model的核心思想。
Attention模型的基本表述可以这样理解成:
当我们人在看一样东西的时候,我们当前时刻关注的一定是我们当前正在看的这样东西的某一地方,换句话说,当我们目光移到别处时,注意力随着目光的移动也在转移。
这意味着,当人们注意到某个目标或某个场景时,该目标内部以及该场景内每一处空间位置上的注意力分布是不一样的。
这一点在如下情形下同样成立:当我们试图描述一件事情,我们当前时刻说到的单词和句子和正在描述的该事情的对应某个片段最先关,而其他部分随着描述的进行,相关性也在不断地改变。
从上面两种情形来看,对于 Attention的作用角度出发,我们就可以从两个角度来分类 Attention种类:
空间注意力 Spatial Attention
时间注意力 Temporal Attention
这样的分类更多的是从应用层面上,而从 Attention的作用方法上,可以将其分为 Soft Attention 和 Hard Attention,这既我们所说的, Attention输出的向量分布是一种one-hot的独热分布还是soft的软分布,这直接影响对于上下文信息的选择作用。
AM刚开始也确实是应用在图像领域里的,AM在图像处理领域取得了非常好的效果!于是,就有人开始研究怎么将AM模型引入到NLP领域。最有名的当属“Neural machine translation by jointly learning to align and translate”这篇论文了,这篇论文最早提出了Soft Attention Model,并将其应用到了机器翻译领域。后续NLP领域使用AM模型的文章一般都会引用这篇文章(目前引用量已经上千了!!!)
为什么要加入Attention:
- 当输入序列非常长时,模型难以学到合理的向量表示
- 序列输入时,随着序列的不断增长,原始根据时间步的方式的表现越来越差,这是由于原始的这种时间步模型设计的结构有缺陷,即所有的上下文输入信息都被限制到固定长度,整个模型的能力都同样收到限制,我们暂且把这种原始的模型称为简单的编解码器模型。
- 编解码器的结构无法解释,也就导致了其无法设计。
长输入序列带来的问题:
使用传统编码器-解码器的RNN模型先用一些LSTM单元来对输入序列进行学习,编码为固定长度的向量表示;然后再用一些LSTM单元来读取这种向量表示并解码为输出序列。
采用这种结构的模型在许多比较难的序列预测问题(如文本翻译)上都取得了最好的结果,因此迅速成为了目前的主流方法。
这种结构在很多其他的领域上也取得了不错的结果。然而,它存在一个问题在于:输入序列不论长短都会被编码成一个固定长度的向量表示,而解码则受限于该固定长度的向量表示。
这个问题限制了模型的性能,尤其是当输入序列比较长时,模型的性能会变得很差(在文本翻译任务上表现为待翻译的原始文本长度过长时翻译质量较差)。
“一个潜在的问题是,采用编码器-解码器结构的神经网络模型需要将输入序列中的必要信息表示为一个固定长度的向量,而当输入序列很长时则难以保留全部的必要信息(因为太多),尤其是当输入序列的长度比训练数据集中的更长时。”
— Dzmitry Bahdanau, et al., Neural machine translation by jointly learning to align and translate, 2015
使用Attention机制
Attention机制的基本思想是:打破了传统编码器-解码器结构在编解码时都依赖于内部一个固定长度向量的限制。
Attention机制的实现是 通过保留LSTM编码器对输入序列的中间输出结果,然后训练一个模型来对这些输入进行选择性的学习并且在模型输出时将输出序列与之进行关联。
换一个角度而言,输出序列中的每一项的生成概率取决于在输入序列中选择了哪些项。
Attention-based Model 其实就是一个相似性的度量,当前的输入与目标状态约相似,那么在当前的输入的权重就会越大。就是在原有的model上加入了Attention的思想。
没有attention机制的encoder-decoder结构通常把encoder的最后一个状态作为decoder的输入(可能作为初始化,也可能作为每一时刻的输入),但是encoder的state毕竟是有限的,存储不了太多的信息,对于decoder过程,每一个步骤都和之前的输入都没有关系了,只与这个传入的state有关。attention机制的引入之后,decoder根据时刻的不同,让每一时刻的输入都有所不同。
参考博客 浅谈Attention-based Model【原理篇】,对Attention的公式梳理一下。
使用机器翻译为例,我们翻译“机器学习”,在翻译“machine”的时候,我们希望模型更加关注的是“机器”而不是“学习”。

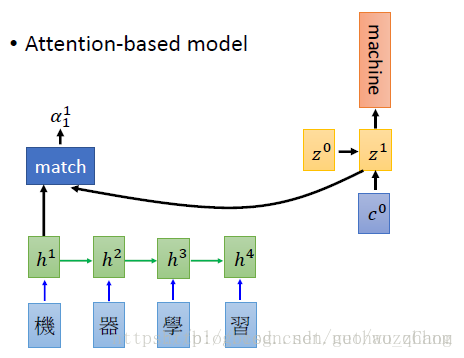
Attention其实就是一个当前的输入与输出的匹配度。
(
为当前时刻RNN的隐层输出向量,而不是原始输入的词向量,
初始化向量,如rnn中的initial memory)
match为计算这两个向量的匹配度的模块,出来的
即为由match算出来的相似度。
所以,match是啥?
对于“match”, 理论上任何可以计算两个向量的相似度都可以,比如:
- 余弦相似度
- 一个简单的 神经网络,输入为h和w,输出为α
- 或者矩阵变换 (Multiplicative attention,Luong et al., 2015)
现在已经由match模块算出了当前输入输出的匹配度,然后我们需要计算当前的输出 和 每一个输入做一次match计算,分别可以得到当前的输出和所有输入的匹配度,由于计算出来并没有归一化,所以我们使用softmax,使其输出时所有权重之和为1。那么和每一个输入的权重都有了,那么我们可以计算出其加权向量和,作为下一次的输入。
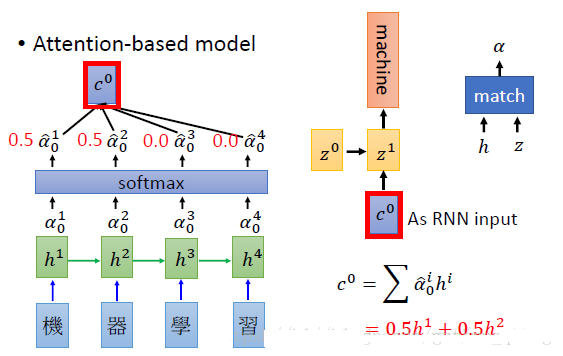
算出
之后,把这个向量作为 RNN 的输入。然后第一个时间点的输出的编码
由
和初始状态
共同决定。我们计算得到
之后,替换之前的
再和每一个输入的encoder的vector计算匹配度,然后softmax,计算向量加权,作为第二时刻的输入……如此循环直至结束。
再看看 Grammar as a Foreign Language 一文当中的公式:
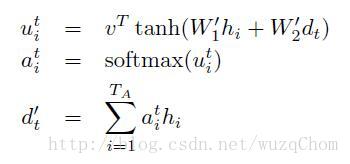
上面的符号表示和前面描述的不太一样,经统一符号的公式如下:

得到
之后,就可以作为第t时刻RNN的input,而
可以作为t时刻RNN的隐状态的输入,这样就能够得到新的隐状态
,如此循环,直到遇到停止符为止。
虽然模型使用attention机制之后会增加计算量,但是性能水平能够得到提升。另外,使用attention机制便于理解在模型输出过程中输入序列中的信息是如何影响最后生成序列的。这有助于我们更好地理解模型的内部运作机制以及对一些特定的输入-输出进行debug。