目录
前言------内容多一点,周末有了点事情,好在今天终于总结完了,加油!
事物
什么是事物
Transaction 其实是一组操作,里面包含了很多的单一的逻辑。只要有一个逻辑没有执行成功,那么这个事物就是失败的,这个时候所有的数据回滚到最初始的状态(回滚)
事物有什么作用
处理一组逻辑,如果其中一个逻辑不成功就是失败。
例子:银行转账,当A转账给B,突然断电,转账失败,数据回滚最初的状态
事物怎么用
1、事物不是针对的数据库,而是只针对数据库连接的对象(connection),如果再开一个对象,默认是自动提交的
2、事物会自动提交的
使用命令行方式演示事物
- 开启事务
start transaction - 提交或者回滚事物
commit:提交事物
rollback:回滚事物
- 关闭自动提交的功能
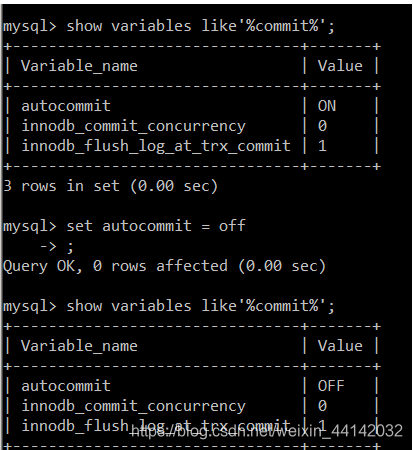
命令:show variables like ‘%commit%’
查询含有commit字符串的所有变量名称(variables变量的意思)
命令:set autocommit = off
关闭自动提交事物的功能(auto自动commit提交,off关闭)
- 演示事物
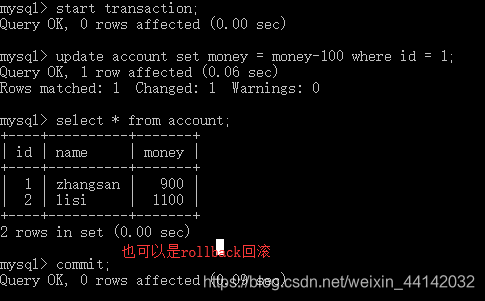
只有当commit才提交数据,数据库表中的数据才会改变,如果不提交,表中数据是不会变的。
原来表中数据zhangsan:1000 lishi:1100,zhangsan减去100,张三的数据在命令行中查的话是改变了,但是数据库中没变,可以使用数据库工具查看。只有commit提交之后才会改变
使用代码的方式演示事物
代码里面的事物,主要针对连接来的(Connection con)
事物,只会针对于 增 删 改 操作,查询不会修改数据,用不到事物
- 通过con.setAutoCommit(false); 来关闭自动提交事物的设置
- 通过con.commit(); 提交事物
- 通过con.rollback(); 回滚事物
@Test
public void textTransaction(){
Connection conn = null;
PreparedStatement ps = null;
ResultSet rs = null;
try {
//默认是自动提交事物的
conn = JDBCUtil.getConn();
//关闭自动提交事物的功能
conn.setAutoCommit(false);
String sql = "update account set money = money - ? where id = ?";
ps = conn.prepareStatement(sql);
//给ID为1的用户减少 100 块钱
ps.setInt(1,100);
ps.setInt(2,1);
ps.executeUpdate();
int a = 10 / 0;
//给ID为2的用户增加 100 块钱
ps.setInt(1,-100);
ps.setInt(2,2);
ps.executeUpdate();
conn.commit();
} catch (SQLException e) {
try {
conn.rollback();
} catch (SQLException e1) {
e1.printStackTrace();
}
e.printStackTrace();
}finally {
JDBCUtil.closeResource(conn,ps,rs);
}
}
事物的特性ACID【面试】
- 原子性
指的是,事物中包含的逻辑,不可分割
- 一致性
指的是,事物执行的前后,数据的一致性
- 隔离性
指的是,事物在执行期间,不受其他事物的影响
- 持久性
指的是,事物执行完毕之后,数据应该持久的保存在磁盘上
事物的安全问题和隔离级别【面试】
安全问题
不考虑事物的隔离级别的设置,那么会出现 读问题,和 写问题
List item
读问题
- 脏读:指的是,一个事物读取到另一个事物还未提交的数据
- 不可重复读:一个事物读到了另一个事物提交的数据,导致两次查询前后数据不一致
- 幻读:一个事物读到了另一个事物已经提交的插入的数据,导致多次查询的结果不一致
写问题(丢失更新)
: 丢失更新
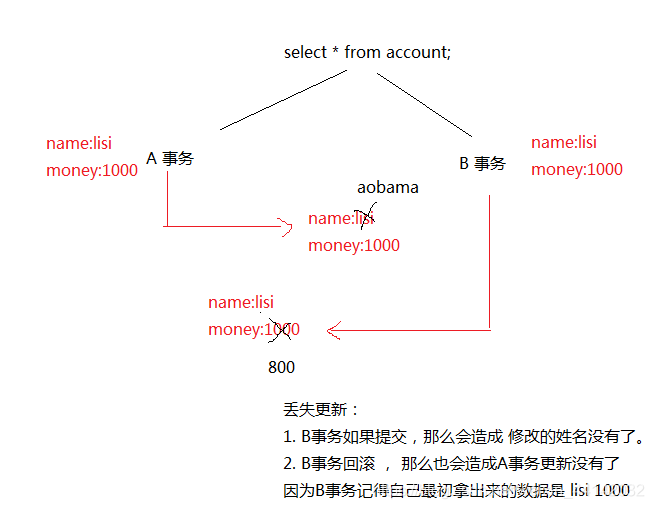
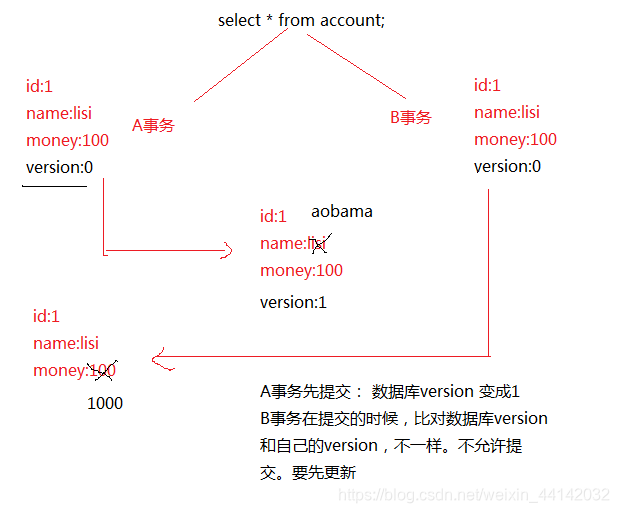
丢失更新解决办法
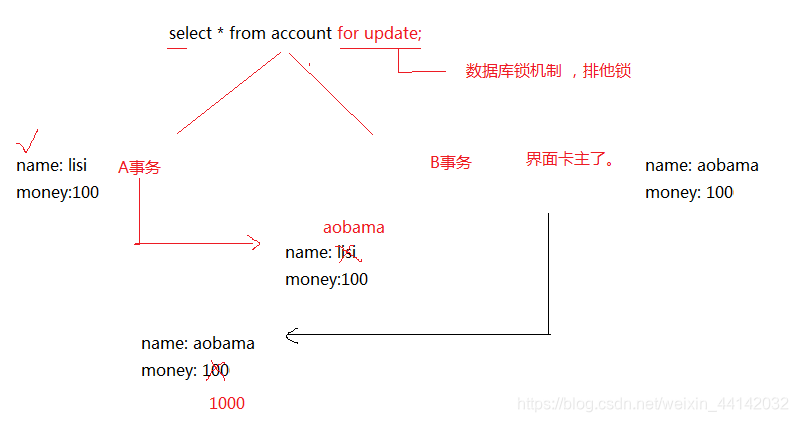
- 悲观锁
可以在查询的时候,加入 for update
- 乐观锁
要求程序员自己控制。
隔离级别
- 读未提交(Read Uncommitted)
引发“脏读”
指的是,一个事物读到另一个事物还未提交的数据,引发“脏读”,读取到的是数据库内存上的数据,而并非是真正磁盘上的数据
例子:
开启一个命令行窗口A, 开始事务,然后查询表中记录。 设置当前窗口的事务隔离> 级别为 读未提交 命令如下:
//查询当前事物的隔离级别 select @@tx_isolation; //设置当前窗口 事物 隔离级别为 read uncommitted set session transaction isolation level read uncommitted;另外在打开一个窗口B, 也开启事务, 然后执行 sql 语句, 但是不提交
在A窗口重新执行查询, 会看到B窗口没有提交的数据。
- 读已提交(Read committed )
解决脏读,引发不可重复读
与前面的读未提交刚好相反,这个隔离级别是 ,只能读取到其他事务已经提交的数据,那些没有提交的数据是读不出来的。
但是这会造成一个问题是:前后读取到的结果不一样。 发生了不可重复!!!, 所谓的不可重复读,就是不能执行多次读取,否则出现结果不一 。
例子1:
开启一个命令行窗口A, 设置A窗口的隔离级别为 读已提交,开始事务,然后查询表中记录。 设置当前窗口的事务隔离级别为 读已提交 命令如下:
set session transaction isolation level read committed;另外在打开一个窗口B, 也开启事务, 然后执行 sql 语句, 但是不提交
在A窗口重新执行查询, 是不会看到B窗口刚才执行sql 语句的结果,因为它还没有提交。
例子2:
- 设置A窗口的隔离级别为 读已提交
- A B 两个窗口都开启事务, 在B窗口执行更新操作。
- 在A窗口执行的查询结果不一致。 一次是在B窗口提交事务之前,一次是在B窗口提交事务之后。
- 重复读(Repeatable Read)
解决脏读,不可重复读。 不能解决幻读
Repeatable Read 【重复读】 - MySql 默认的隔离级别就是这个。
该隔离级别, 可以让事务在自己的会话中重复读取数据,并且不会出现结果不一样的状况,即使其他事务已经提交了,也依然还是显示以前的数据。
事物与事物之间是分开的,互不影响。
例子:
开启一个命令行窗口A, 开始事务,然后查询表中记录。 设置当前窗口的事务隔离级别为 重复读 命令如下:
set session transaction isolation level repeatable read;另外在打开一个窗口B, 也开启事务, 然后执行 sql 语句, 但是不提交
在A窗口重新执行查询, 是不会看到B窗口刚才执行sql 语句的结果,因为它还没有提交。
在B窗口执行提交。
在A窗口中执行查看, 这时候查询结果,和以前的查询结果一致。不会发生改变。
- 可串行化(Serializable)
解决 脏读、不可重复读、幻读
如果有一个连接的隔离级别设置为了串行化 ,那么谁先打开了事务, 谁就有了先执行的权利, 谁后打开事务,谁就只能等着,等前面的那个事务,提交或者回滚后,才能执行。 但是这种隔离级别一般比较少用。 容易造成性能上的问题。 效率比较低。
Serializable 可以防止上面的所有问题,但是都使用该隔离级别也会有些问题。 比如造成并发的性能问题。 其他的事务必须得等当前正在操作表的事务先提交,才能接着往下,否则只能一直在等着。
| 分类 | Value |
|---|---|
| 按效率划分,从高到低 | 读未提交 > 读已提交 > 可重复读 > 可串行化 |
| 按拦截度划分,从高到低 | 可串行化 > 可重复读 > 读已提交 > 读未提交 |
数据库连接池
什么是连接池
连接池就是里面存有多个连接数据库的连接对象,然后统一管理
- 数据库的连接对象创建工作,比较消耗性能。
- 一开始现在内存中开辟一块空间(集合) , 一开先往池子里面放置 多个连接对象。 后面需要连接的话,直接从池子里面去。不要去自己创建连接了。 使用完毕, 要记得归还连接。确保连接对象能循环利用。
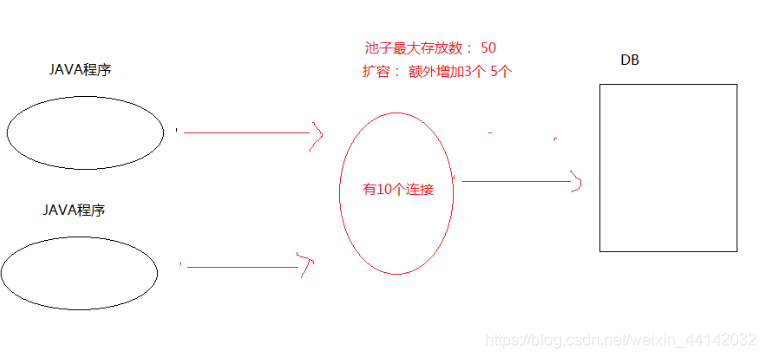
连接池的作用
- 资源重复利用,避免了重复创建连接对象。
连接对象使用完之后,再归还到池子中统一管理- 更快的响应速度
连接池里面在一开始就创建了好多个连接对象,使用的话直接拿就好了,无需再创建
提高效率,因为
自定义连接池
- 代码实现
- MyDataSource类
public class MyDataSource implements DataSource {
static List<Connection> list = new ArrayList<Connection>();
static {
for (int i = 0;i < 10; i++){
Connection conn = JDBCUtil.getConn();
list.add(conn);
}
}
/**
* 通过这个方法获得连接对象
* return Connection
* */
@Override
public Connection getConnection() throws SQLException {
if(list.size() == 0){
//在增加3个连接对象
for (int i = 0; i < 3;i++){
Connection conn = JDBCUtil.getConn();
list.add(conn);
}
}
return list.remove(0);
}
/**
* 用完之后在归还连接对象,调用这个方法
* param conn
* */
public void addBack(Connection conn){
list.add(conn);
}
- DoMain类。,运行测试类
public class doMain {
public static void main(String[] args) {
Connection conn = null;
PreparedStatement ps = null;
//这种写法不能够面向接口编程,多了一个addBack()方法,DataSource dataSource = new MyDataSource();
MyDataSource myDataSource = new MyDataSource();
try {
conn = myDataSource.getConnection();
String sql = "insert into account values (null ,?,?)";
ps = conn.prepareStatement(sql);
ps.setString(1,"wangwu");
ps.setInt(2,2530);
ps.executeUpdate();
} catch (SQLException e) {
e.printStackTrace();
}finally {
myDataSource.addBack(conn);
JDBCUtil.closeResource1(conn,ps);
}
}
}
- 出现的问题:
- 需要记住额外的addBack()方法,不能面向接口编程
- 有的时候还得建立多个连接池,(new MyDataSource()),浪费资源
单例模式可以解决- 无法面向接口编程
-
解决的办法
以addBack() 方法入手 1. 直接修改源代码 行不通 2. 使用继承,重写close方法,但是不知道DataSource接口的实现类,没法继承 3. 使用装饰者模式
装饰者模式
- 分析问题
由于我们自定义的数据库连接池,引发了一个问题,多了一个用完连接归还的addBack()方法,导致不能用面向接口编程。
所以,我们打算用重写Connection类中的close()方法,之前的close()方法是关闭资源,我们重写之后使他不关闭资源,而是把用完的Connection连接对象添加到List的集合中
- 装饰者模式的代码实现
MyDataSource类
public class MyDataSource implements DataSource {
static List<Connection> list = new ArrayList<Connection>();
static ConnectionWriter connectionWriter = null;
static {
for (int i = 0;i < 10; i++){
Connection conn = JDBCUtil.getConn();
list.add(conn);
}
}
/**
* 通过这个方法获得连接对象
* return Connection
* */
@Override
public Connection getConnection() throws SQLException {
if(list.size() == 0){
//在增加3个连接对象
for (int i = 0; i < 3;i++){
Connection conn = JDBCUtil.getConn();
list.add(conn);
}
}
//在抛出去之前包装一下
Connection conn = list.remove(0);
ConnectionWriter c = new ConnectionWriter(conn,list);
return c;
}
ConnectionWriter类
public class ConnectionWriter implements Connection {
Connection conn = null;
List<Connection> list = null;
public ConnectionWriter(Connection conn, List<Connection> list){
super();
this.conn = conn;
this.list = list;
}
@Override
public void close() throws SQLException {
System.out.println("没有归还之前的connection对象有几个:"+list.size());
list.add(conn);
System.out.println("归还之后的connection对象有几个:"+list.size());
}
@Override
public PreparedStatement prepareStatement(String sql) throws SQLException {
return conn.prepareStatement(sql);
}
DoMain测试类
public class doMain {
public static void main(String[] args) {
Connection conn = null;
PreparedStatement ps = null;
DataSource dataSource = new MyDataSource();
try {
conn = dataSource.getConnection();
String sql = "insert into account values (null ,?,?)";
ps = conn.prepareStatement(sql);
ps.setString(1,"wangwu1");
ps.setInt(2,2530);
ps.executeUpdate();
} catch (SQLException e) {
e.printStackTrace();
}finally {
// dataSource.addBack(conn);
JDBCUtil.closeResource1(conn,ps);
}
}
}
开源连接池
自己写的连接池有些问题,然后,有些人就写了一些连接池,其中开源的常用的是c3p0,和 dbcp
c3p0【重点】
什么是c3p0
c3p0是一个开源的连接池,他实现了jdbc和数据源的绑定。主要负责建立和管理数据库连接,支持JDBC3的规范和JDBC2的标准扩展。目前使用他的框架有
Spring 和 Hibernate
c3p0的使用
ComboPooledDataSource类
- 使用配置文件
配置文件c3p0-config.xml 名字必须是这一个
<c3p0-config>
<!-- 默认的数据库连接池-->
<default-config>
<property name="driverClass">com.mysql.jdbc.Driver</property>
<property name="JdbcUrl">jdbc:mysql://localhost:3306/stus</property>
<property name="user">root</property>
<property name="password">123456</property>
<property name="initialPoolSize">10</property>
<property name="maxIdleTime">30</property>
<property name="maxPoolSize">100</property>
<property name="minPoolSize">10</property>
<property name="maxStatements">200</property>
<user-overrides user="test-user">
<property name="maxPoolSize">10</property>
<property name="minPoolSize">1</property>
<property name="maxStatements">0</property>
</user-overrides>
</default-config>
<!-- This app is massive!
这一部分是当使用别的数据库时候,根据<named-config name="oracle"> 中的name判断使用哪个数据库连接池
-->
<named-config name="oracle">
<property name="acquireIncrement">50</property>
<property name="initialPoolSize">100</property>
<property name="minPoolSize">50</property>
<property name="maxPoolSize">1000</property>
<!-- intergalactoApp adopts a different approach to configuring statement caching -->
<property name="maxStatements">0</property>
<property name="maxStatementsPerConnection">5</property>
<!-- he's important, but there's only one of him -->
<user-overrides user="master-of-the-universe">
<property name="acquireIncrement">1</property>
<property name="initialPoolSize">1</property>
<property name="minPoolSize">1</property>
<property name="maxPoolSize">5</property>
<property name="maxStatementsPerConnection">50</property>
</user-overrides>
</named-config>
</c3p0-config>
代码实现:
先导入jar包,c3p0-0.9.1.2.jar
/**
配置文件名必须使用 c3p0-config.xml ,当类加载的时候直接解析读取该文,如果改名就读取不到了,除非自己写源代码
*/
//创建数据库连接池
ComboPooledDatasource dataSource = new ComboPooledDataSource();
//获取连接
Conection conn = dataSource.getConnection();
//。。。后面和以前连接数据库一样
- 不使用配置文件
代码实现:
comborPooledDataSource dataSource= new comboPooledDataSource();
dataSource.setDriverClass("com.mysql:jdbc:Driver");
dataSource.setJdbcUrl("jdbc:mysql://localhost:3306/stus);
dataSource.setUser("root");
dataSource.setPassword("123456");
Connection con = dataSource.getConnection();
//.......
dbcp
什么是dbcp
dbcp也是一种开源的连接池,是java数据库连接池的一种,由Apach开发,主要作用于让程序自己管理连接池的释放和断开
dbcp的使用
- 使用配置文件
自己定义一个dbcpconfig.properties文件,放在src目录下
导入jar包
commons-dbcp-1.4.jar 和 commons-pool-1.5.6.jar
使用DataSource接口的实现类 BasicDataSource类 和 BasicDataSourceFictory类
createDataSource() 方法
#连接设置
driverClassName=com.mysql.jdbc.Driver
url=jdbc:mysql://localhost:3306/stus
username=root
password=123456
#<!-- 初始化连接 -->
initialSize=10
#最大连接数量
maxActive=50
#<!-- 最大空闲连接 -->
maxIdle=20
#<!-- 最小空闲连接 -->
minIdle=5
#<!-- 超时等待时间以毫秒为单位 6000毫秒/1000等于60秒 -->
maxWait=60000
#JDBC驱动建立连接时附带的连接属性属性的格式必须为这样:[属性名=property;]
#注意:"user" 与 "password" 两个属性会被明确地传递,因此这里不需要包含他们。
connectionProperties=useUnicode=true;characterEncoding=gbk
#指定由连接池所创建的连接的自动提交(auto-commit)状态。
defaultAutoCommit=true
#driver default 指定由连接池所创建的连接的事务级别(TransactionIsolation)。
#可用值为下列之一:(详情可见javadoc。)NONE,READ_UNCOMMITTED, READ_COMMITTED, REPEATABLE_READ, SERIALIZABLE
defaultTransactionIsolation=READ_UNCOMMITTED
代码实现:
@Test
public void Text(){
try {
BasicDataSourceFactory factory = new BasicDataSourceFactory();
Properties properties = new Properties();
InputStream is = Dbcp.class.getClassLoader().getResourceAsStream("dbcpconfig.properties");
properties.load(is);
DataSource dataSource = factory.createDataSource(properties);
QueryRunner queryRunner = new QueryRunner(dataSource);
User b = queryRunner.query("select * from account where id = ?", new ResultSetHandler<User>() {
@Override
public User handle(ResultSet resultSet) throws SQLException {
User a = new User();
while (resultSet.next()){
a.setName(resultSet.getString("name"));
a.setMoney(resultSet.getInt("money"));
}
return a;
}
},3);
System.out.println(b.toString());
} catch (Exception e) {
e.printStackTrace();
}
}
- 不使用配置文件
代码实现
//1. 构建数据源对象
BasicDataSource dataSource = new BasicDataSource();
//连的是什么类型的数据库, 访问的是哪个数据库 , 用户名, 密码。。
//jdbc:mysql://localhost/bank 主协议:子协议 ://本地/数据库
dataSource.setDriverClassName("com.mysql.jdbc.Driver");
dataSource.setUrl("jdbc:mysql://localhost/bank");
dataSource.setUsername("root");
dataSource.setPassword("root");
DBUtils数据库的工具类
什么是DBUtils
DBUtils是一个开源的工具类,由Apach开发,对数据库的CRUD操作进行了一些简单的封装,不影响开发性能,简化了CRUD的操作
DbUtils的使用
导入jar包 commons-dbutils-1.4.jar
QueryRunner 类 new QueryRunner(DataSource接口的实现类);
类中的 query() 和 update() 方法
代码实现:
ComboPooledDataSource dataSource = new ComnoPooledDataSource();
QueryRunner queryRunner = new QueryRanner(dataSource);
//执行 增 删 改操作
queryRunner.update("sql语句",参数);
int update = queryRunner.update("update account set money = ? where id = ?", 12000, 3);
//执行查操作
queryRunner.query("sql语句",结果集对象接口,参数);
//1、通过匿名内部类去实现ResultSetHandler接口,
User user = queryRunner.query("select * from account where id = ?", new ResultSetHandler<User> (){
@Override
public User handle(ResultSet resultSet) throws SQLException {
User user1 = new User();
while (resultSet.next()){
user1.setName(resultSet.getString("name"));
user1.setMoney(resultSet.getInt("money"));
}
return user1;
}
},3);
System.out.println(user.toString());
//2、ResultSetHandler是一个接口,直接去new框架中写好的实现类
//查询一个用户,用户有多个属性,用一个对象去接收他 ,定义的时候注意变量一定要与数据库的列名一样才能传递过来数据
// 为什么要传入一个字节码对象?通过反射获取一个实例
User query = queryRunner.query("select * from account where id = ?", new BeanHandler<User>(User.class),3);
System.out.println(query.toString());
//获取多个用户
List<User> list = queryRunner.query("select *from account", new BeanListHandler<User>(User.class));
Iterator<User> iterator = list.iterator();
while (iterator.hasNext()){
User u = iterator.next();
System.out.println(u.toString());
}
ResultSetHandler接口的常用的实现类
-
最常用的两个实现类(封装成对象)
BeanHandler: 查询单个数据,封装成一个对象,。 在对象中的属性应该和 数据库中列名一致(对象中的属性对应的是表中列的值), 否则不会数据封装不过来 BeanListHandler:查询多个数据,然后每个数据封装成一个对象,然后,多个对象存在一个集合中 -
封装成数组
ArrayHandler:查询单个数据,然后封装成数组
ArrayListHandler:查询多个数据,然后每个数据封装成一个数组(数组中的元素是表中每一列的值),然后多个数组存到List集合
- 封装成Map集合
Maphandler:查询单个数据,然后封装成Map集合
MapListHandler:查询多个数据,封装成一个集合,集合里面的元素是map。
不常用的实现类
ColumnListHandler
KeyedHandler
ScalarHandler 通常处理一些sql语句中的 count() sum() min() max() avg() ,返回的是 Long数据类型,只能用Long类型去接受,不能用int
DbUtils内部源码解析
源数据:解释数据的数据
获取参数的数据库相关的源数据
ParameterMetaData metaData = ps.getParameterMetaData();
获取占位符有几个
int count = metaData.getParameterCount();
泛型的使用
元数据
Meata data
描述数据的数据 String sql , 描述这份sql字符串的数据叫做元数据
数据库元数据 DatabaseMetaData
参数元数据 ParameterMetaData
结果集元数据 ResultSetMetaData
- 增、删、改 、的update()方法
public class CRUDUtils {
@Test
public void updateText(){
// update("insert into account values (null,?,?)","mingming",153);
update("delete from account where id =?",7);
}
//实现增,删,改的功能
public void update(String sql,Object ... param){
try {
Connection conn = JDBCUtil.getConn();
PreparedStatement ps = conn.prepareStatement(sql);
//源数据:定义数据的数据,
ParameterMetaData metaData = ps.getParameterMetaData();
//获取原数据 中占位符的个数,也就是 ? 的个数
int parameterCount = metaData.getParameterCount();
for (int i = 0; i<parameterCount;i++){
ps.setObject(i+1,param[i]);
}
ps.executeUpdate();
} catch (SQLException e) {
e.printStackTrace();
}
}
}
- 查询 query() 方法
- CRUDUtils类
public class CRUDUtils {
@Test
public void queryText(){
User user = query("select * from account where id = ?", new ResultSetHandler<User>() {
@Override
public User hand(ResultSet resultSet) throws SQLException {
User user = new User();
while (resultSet.next()) {
user.setName(resultSet.getString("name"));
user.setMoney(resultSet.getInt("money"));
}
return user;
}
}, 3);
}
//实现查的功能
public <T> T query(String sql,ResultSetHandler<T> resultSetHandler,Object ... param){
try {
Connection conn = JDBCUtil.getConn();
PreparedStatement ps = conn.prepareStatement(sql);
//获取参数的数据库相关的源数据
ParameterMetaData metaData = ps.getParameterMetaData();
//获取占位符有几个
int count = metaData.getParameterCount();
for (int i = 0; i<count;i++){
ps.setObject(i+1,param[i]);
}
//这个地方主要是返回一个resultSet,要给方法的执行者封装,并返回一个封装对象
ResultSet resultSet = ps.executeQuery();
//将封装的使用权交给函数的调用者
T t = (T)resultSetHandler.hand(resultSet);
return t;
} catch (SQLException e) {
e.printStackTrace();
}
return null;
}
}
2.自定义的 ResultSetHandler接口
public interface ResultSetHandler<T> {
//查询结果集,返回封装对象
T hand(ResultSet resultSet) throws SQLException;
}