注:因为毕业论文需要用到相关知识,借着TF 2.0发布的时机,重新捡起深度学习。在此,也推荐一下优达学城与TensorFlow合作发布的TF 2.0入门课程,下面的例子就来自该课程。
原文发布于博客园:https://www.cnblogs.com/Belter/p/10626418.html
本文中所有代码都在文末第二个链接中,转载请注明出处!
机器学习与深度学习
深度学习是机器学习的一个分支,当下也是该领域发展最快、最受关注的一个分支。上周刚刚公布的2018年图灵奖就颁发给了对深度学习的发展做出了重要贡献的三位科学家:Yoshua Bengio、Geoffrey Hinton和Yann LeCun。相对于传统的机器学习算法,深度学习最大的区别在于:在训练的过冲中,由神经网络自主学习数据的表示,而不需要人工做特征工程。
之前写了多篇与机器学习有关的博文,以下几篇与深度学习有关,可以帮助理解基础知识:
因为深度学习是机器学习的一个分支,与传统的机器学习方法有非常多的相似之处。概括如下:
- 解决的主要问题:分类(二分类或多分类),回归,聚类;
- 学习的基本过程:在有监督学习(分类和回归问题)中,都是输入“数据 + 标签(答案)”,获得“算法”(从数据到答案的某种映射关系);
- 训练过程都是对代价函数的优化过程;
- 都面临过拟合的挑战,因此都需要正则化方面的技术;
- 都可以使用梯度下降法来优化参数.
当然深度学习中,也有一些有别于传统机器学习的主题:
- 网络的结构:层数,每一层的神经单元数;
- 激活函数:作用于隐藏层神经元,使得数据的变化过程从线性到非线性;
- 反向传播:用于多层神经网络中误差(或梯度)从网络的输出层向输入层传播;
- 其他特殊网络结构:CNN中的卷积、长短期记忆网络、编码器和解码器等.
多层感知机
多层感知机(multilayer percepton, MLP)也叫深度前馈网络或前馈神经网络,是典型的深度学习模型。其目的是近似某个函数$f^*$。当前馈神经网络被拓展成包含反馈连接时,它们被称为循环神经网络(recurrent neural network, RNN)。
关于多层感知机的基础知识,可以参考我之前的博客——【机器学习】神经网络实现异或(XOR),或下面的两篇博主"python27"的学习笔记:
一个简单的例子
虽然接触到深度学习的知识已经很长时间了,但是在平时遇到分类或是回归相关的问题,还是会优先选择传统的机器学习算法。有时候是因为数据量比较小,但是还有一个比较重要的原因是自己实践太少,对于深度学习这个工具,用起来还不顺手。之前学习的时候,在TensorFlow、Pytouch和Keras之间很难做出选择。现在TF 2.0借鉴Keras中的API风格,既保持了性能的优势,也更加简单易学。加上最近刚刚发布的课程,因此就决定选择TF 2.0作为自己以后练习深度学习算法的工具。
将摄氏度转换成华氏度
温度的不同单位之间的转换有明确的定义,知道其中一种单位的温度值可以通过下面的公式精确的计算出另一种单位下的温度值。
$$ f = c \times 1.8 + 32 $$
如果我们已知该公式,将该公式写成一个函数,输入为$c$,输出为$f$,那么这就是一个入门级的编程练习题。
但是假如我们现在知道几个数值对,即输入和答案,该公式并不知道。此时就可以利用机器学习的方法,求出一个近似的从$c$到$f$的映射关系。
下面是代码:
1 from __future__ import absolute_import, division, print_function 2 import tensorflow as tf 3 tf.logging.set_verbosity(tf.logging.ERROR) 4 5 import numpy as np 6 7 # 输入的摄氏温度以及其对应的华氏温度,前面两个故意写错了 8 celsius_q = np.array([-40, -10, 0, 8, 15, 22, 38], dtype=float) 9 fahrenheit_a = np.array([-40, 14, 32, 46, 59, 72, 100], dtype=float) 10 11 for i,c in enumerate(celsius_q): 12 print("{} degrees Celsius = {} degrees Fahrenheit".format(c, fahrenheit_a[i])) 13 14 # 输入后连接了只有一个神经单元的隐藏层 15 l0 = tf.keras.layers.Dense(units=1, input_shape=[1]) 16 17 # 将网络层添加到序列模型中 18 model = tf.keras.Sequential([l0]) 19 20 # 编译神经网络模型 21 model.compile(loss='mean_squared_error', 22 optimizer=tf.keras.optimizers.Adam(0.1)) 23 24 # 训练模型 25 history = model.fit(celsius_q, fahrenheit_a, epochs=500, verbose=False) 26 print("Finished training the model")
在这个例子中,包括以下要素:
- 训练数据:一共有7个样本(输入 + 答案),有两个样本的值不准确(在实际项目中,有可能是因为测量或记录导致的误差);
- 层(layers):神经网络是以层为基本组成单位的,每层有两个最基本的参数units和activation,分别表示该层神经单元的个数和激活函数(这里没有设置第二个参数就表示不对该层的神经单元进行任何变换);
- 层的类型:层的不同类型,代表了层之间不同的连接方式,这里使用的是全连接层(Dense),表示各层之间所有点都直接相连;
- 模型:组织不同“层”的方式,这里使用的序列模型(Sequential)按照层的顺序从输入到输出叠加各个层;
- 编译(compile):训练之前必须编译,在编译的时候需要指定两个非常重要的参数——loss和optimizer,loss就是代价函数,optimizer是训练模型的方法;
- 训练模型(fit):必要参数为输入数据,对于的标签(答案),迭代次数(epochs)等.
上面15行和18行通常会写在一起:
model = tf.keras.Sequential([ tf.keras.layers.Dense(units=1, input_shape=[1]) ])
模型训练的过程中,损失函数的值会随着训练次数发生变化。这些变化由fit函数返回,记录在history中。画出来如下:
import matplotlib.pyplot as plt plt.xlabel('Epoch Number') plt.ylabel("Loss Magnitude") plt.plot(history.history['loss'])
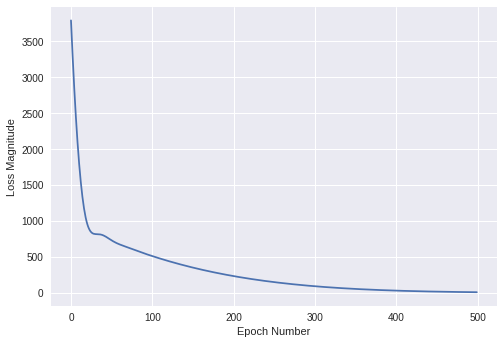
图1:loss随着训练次数的增加而减小
这个模型非常简单,如果不算输入层,整个模型只有1层:输入层连接了只有一个神经单元的层l0,该层处理之后的数据直接作为输出值。
因此该模型的网络结构如下:

图2:上面例子中神经网络的结构
上图中的l0只有一个神经单元,另外还有一个偏置单元(输入值x上方的蓝色点,除了输入层外,每层默认都会有一个作用于该层的偏置单元)。因此,从输入到输出可以表示为:
$$y = x*w + b$$
神经网络的结构本质上是对最终模型的一种假设,这里的假设恰好与真实模型完全相同:线性模型,两个参数。但是在完全不知道真实模型的情况下,大部分时候模型的容量可能都远超过了真实模型,表现在参数多(模型的自由度大),结构复杂,添加了非线性变换的激活函数,因此容易导致过拟合。
训练完成后,可以查看模型各层的参数(偏置单元虽然画在了输入层上方,但还是算作l0层的参数):
print("These are the layer variables: {}".format(l0.get_weights()))
下面是输出:
These are the layer variables: [array([[1.8220955]], dtype=float32), array([29.117624], dtype=float32)]
第一个值(1.822,x的参数)与真实值1.8非常接近,第二个值(29.118,偏置单元的取值)与真实值32也比较接近。由此可见,虽然训练数据中包含两个误差比较大的点,但是最终模型还是比较准确的找到了这两组数据之间的基本规律:$y = 1.82x + 29.12$
训练好模型之后,可以使用下面的方法预测新值:
print(model.predict([100.0]))
输出为"[[211.32718]]",该值与真实值212非常接近。
以上就是假设在不知道温度两种单位之间的转换公式的情况下,通过非常简单的神经网络学习到两组数据之间关系的过程。
学习到与真实的转换公式如此接近的结果,强烈依赖于最开始设定的网络结构(一种先验,对最终模型的假设)。在不知道真实模型的情况下,通常会假设一个比较复杂的网络结构。此时模型参数多,自由度大,模型的容量和搜索空间也是远超过了真实模型,此时真实模型一定被包含其中,但不一定能找到,或者找到非常接近全局最优解的局部最优解。
下面是另一种网络结构的假设:
1 l0 = tf.keras.layers.Dense(units=4, input_shape=[1]) 2 l1 = tf.keras.layers.Dense(units=4) 3 l2 = tf.keras.layers.Dense(units=1) 4 model = tf.keras.Sequential([l0, l1, l2]) 5 model.compile(loss='mean_squared_error', optimizer=tf.keras.optimizers.Adam(0.1)) 6 model.fit(celsius_q, fahrenheit_a, epochs=500, verbose=False) 7 print("Finished training the model") 8 print(model.predict([100.0])) 9 print("Model predicts that 100 degrees Celsius is: {} degrees Fahrenheit".format(model.predict([100.0]))) 10 print("These are the l0 variables: {}".format(l0.get_weights())) 11 print("These are the l1 variables: {}".format(l1.get_weights())) 12 print("These are the l2 variables: {}".format(l2.get_weights()))
输出如下:
Finished training the model
[[211.74747]]
Model predicts that 100 degrees Celsius is: [[211.74747]] degrees Fahrenheit
These are the l0 variables: [array([[ 0.45070484, -0.611826 , 0.1898421 , 0.0913914 ]],
dtype=float32), array([ 3.4355907, -3.5666099, -2.7151687, 3.45835 ], dtype=float32)]
These are the l1 variables: [array([[ 0.22470416, 1.2858697 , 0.81416523, 0.359274 ],
[ 0.38035178, -0.86285967, 0.34824482, -0.30044237],
[-0.16603428, -0.5080208 , -0.27835467, -0.6047108 ],
[-0.5545173 , 0.9019376 , 0.19518667, -0.2925983 ]],
dtype=float32), array([-3.1969943, 3.4892511, 1.7240645, 3.4472196], dtype=float32)]
These are the l2 variables: [array([[-0.30633917],
[ 1.4714689 ],
[ 0.31956905],
[ 0.41886073]], dtype=float32), array([3.3831294], dtype=float32)]
可以看到新模型预测100摄氏度的结果也非常接近其真实的华氏温度。此时模型的结构如下:
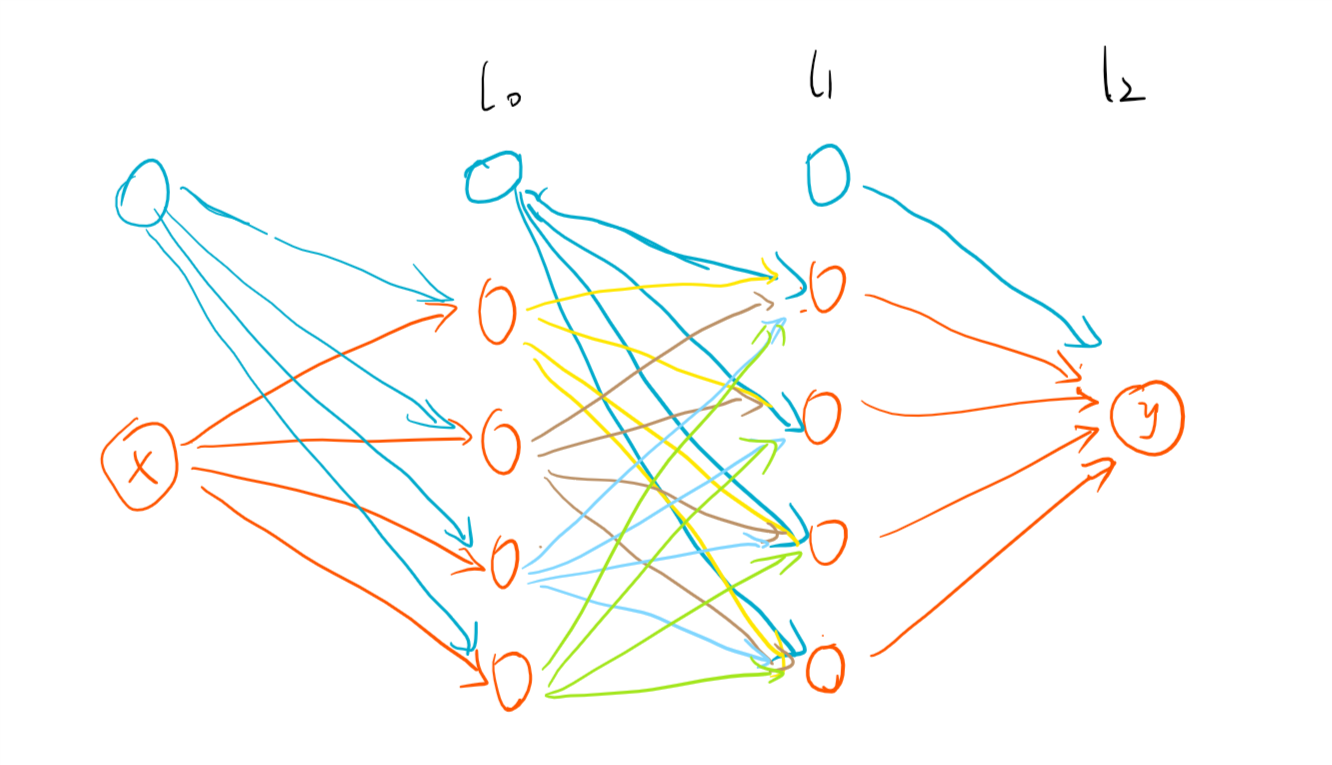
图3:第二个模型的网络结构
不算输入层,这个模型一共有3层。其中两个隐藏层各自含有4个神经单元(蓝色点表示每层的偏置单元)。除了输入层外,其他每个神经单元的取值都由直接与之相连的点决定:例如l2层从上往下数第2个橙色点的取值由上一层4个点的取值和偏置单元的取值决定。可以概括的表示如下:
$$y' = x·w + b$$
其中$x$表示上一层的所有神经单元构成的向量,$w$是连接$y'$与上一层所有单元的参数,$b$是偏置单元。因为这里还是没有设置激活函数,因此每一层中的各个单元都是上一层所有单元取值的线性组合。
虽然第二个模型也能很好的完成预测任务,但是与真实的转换公式之间差异巨大,而且可解释性也变差了。
Reference
https://cn.udacity.com/course/intro-to-tensorflow-for-deep-learning--ud187
https://github.com/OnlyBelter/examples/blob/master/courses/udacity_intro_to_tensorflow_for_deep_learning/l02c01_celsius_to_fahrenheit.ipynb