我们此前已经知道程序是由指令和数据组成的,问题是指令放在什么地方呢?数据放在什么地方呢?在写bash脚本时,数据是保存在变量中的,如果打开的是文件的话,文件就保存在进程的地址空间中作为数据流来进行访问。如:一个BBS的webapp,在这个BBS上注册了近百万个用户,如果某一个用户登录论坛时,程序需要验证这个用户是否存在,那于是要验证用户的账号对不对、用户所给的密码与这个账号是否相匹配。如果一旦正确还要给他授权,如:授权它能够在哪发帖,而有着100万用户的论坛可能里边有1亿个帖子,当一个用户登录的时候,我们的程序,就以php为例,这个程序本身必须要能够去找到这个用户,怎么找?到哪找?用户存储在什么地方?这是很关键的问题。像我们此前程序处理文件的时候,如果数据太大了,我们不足以保存在内存当中或者用起来不方便的话,我们可以把它们保存在一个临时文件当中,而后对这个临时文件再读进来而后进行处理就可以了。而操作系统用户登录的时候是怎么去读取用户信息的?通过/etc/passwd,而/etc/passed文件很小,几十个用户甚至数百个用户就变得很大了,而100万个用户,在100万个中找一个怎么找?还以操作系统为例,当root用户登录的时候,那么应该如何查找当前系统上有没有root用户呢?
最简单的就是使用grep,但是在这么多众多用户当中grep是一个一个比较的,拿着指定指定的字符串逐行逐行进行扫描,那我们扫描个10行50行没有问题,但是扫描100万行所耗的时间、资源太大了并且速度会很慢。事实上我们找的就是用户本身,也没有必要每一行中的每一个字符都去比较一下,只需要比较某一行当中的那一段就可以了。首先我们可以将这个文件切割成段,切成各个不同的字段,只拿其中一个字段进行比较就可以了,这是第一种。
第二种,我们只比较一个字段,但是范围仍然很大,从上到下挨个比较也是很麻烦的,如何加速这个过程呢?可以排序,排序后通过二分法查找。最终平均下来大概需要查找14次左右。但这有一个前提,文件需要提前排序,但用户文件不一定是按用户名存放的,此时又得按用户查找,它又不一定是按照用户名排序的,如何做?只需将所有用户名提出来单独建一个文件即可,再建一个文件,只存放用户名,并且这个文件是自动建立的,而且还是有序的。再进行查找时,只需要针对这个文件寻找即可。若想再找与这个用户名有关的其它信息,只需通过一个指针指向实际数据所在的位置即可。而这个帮助我们查找的文件称为索引文件。
二分法是一种查询方法,但这种需要查找14次的方法太慢了,我们可以使用稀疏索引,如B+树索引,B+树索引结合使用稠密索引和稀疏索引来完成对文件的索引,使得一般情况下我们平均找的每一个数据4次查找就可以了。但还有问题就是,若100万的用户信息放在一个文本文件中,如何建立索引呢?是根据用户名建立,还是用户ID建立呢?如果使用用户名建立下一次希望通过ID查找怎么办?所以可能一个索引还不够,因为索引查找标准不一样,而查找标准称为搜索码(搜索关键字)。因此索引应该跟搜索码相匹配,那么谁去管理索引呢吗,若又新增(删除)了一个用户,索引也需要新增(删除),这就需要开发一个应用程序完成两个文件之间的关联性,不然得手动维护两个文件,非常繁琐。这个程序能够根据指定的标准自动创建对应字段的索引,并且新增(删除)数据时能自动新增(删除)索引,它能帮我们维护索引关联性。
但此时有了维护索引关联性的程序后,查询操作还需由对应的应用程序自己通过算法开发一段程序。这是非常繁琐的。因此可以将查找算法做成一个公共模块,谁要用拿来即可。也可以将查找算法做进管理软件中,让管理软件实现,这是两种不同的管理机制。
任何增删改操作之前其实是都需要做查询操作的,而每一次更新都需要查询,对程序来说挺麻烦的,因此可以这些功能放进这个管理程序中。
因此程序在进行增删改查之前需要有一个通信标准,约定好操作的表示方式、数据返回后的格式;TCP/IP协议可以实施,但功能的实现需要程序实现。web服务叫http服务,得有实现http功能的软件如Apache才可以。
DBMS:(DataBase Management System,数据库管理系统)专门负责数据管理的工具;
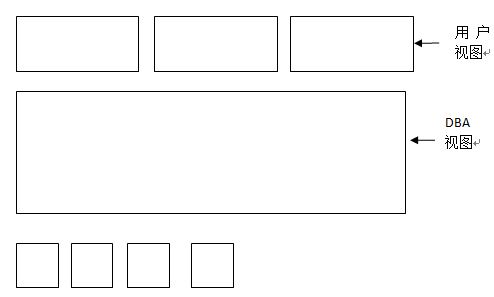
一个文件保存在磁盘上是一种数据流(二进制码),对用户来讲,如/etc/passwd是一个文本文件,它有一行一行的数据,那在用户看来和磁盘看来不是一码事,因此这是两种不同的展现方式。作为系统管理员来讲,就是负责提供这样一种机制让用户的数据能够保存下来为一种格式,而最终展示的又是另外一种格式。作为系统工程师来讲这两种格式都能看到。
而把用户能看到的结果称为用户视图。而磁盘真正保存的结果的称为物理视图。
那么若数据量非常大,该如何组织?
以用户视图为例:
数据的组织结构
层次型结构(有上下级关系)
网状型结构
关系型结构
RDBMS(Relational DataBase Management System,关系型数据库管理系统):能够负责将用户的数据组织成以表的方式来表示并且能够帮我们去维护这些表和表之间关系的这麽一个软件。
一个RDBMS应该具备的功能:
1、数据库创建、删除、修改(既然要提供数据,那么数据库中需要包含多张表,表和表直接有关系,库里面还有索引以方便用户查找)
2、创建表、删除表、修改表
3、索引的创建、删除
4、用户和权限的管理
5、数据增、删、改
6、数据的查询
上述功能都需要通过命令来完成,而这些命令本身从它完成的意义上可以分为三类:
DML(Date Manapulate Language,数据操作语言)
INSERT、REPLACE、UPDATE、DELETE
DDL(Data Defination Language,数据定义语言)
CREATE、ALTER、DROP
DCL(Data Control Language,数据控制语言)
GRANT、REVOKE
SELECT
常见的RDBMS:
egreSQL(世界上第一款关系型数据库,加州大学伯克利分校研发)
DB2(IBM公司的)
早期世界著名的三大数据库:Oracle、Sybase(Sybase公司的)、Infomix(infomix公司的,被Oracle收购)
SQL Server(早期由Sysbase和Microsoft共同开发的,是Sysbase的另外一个变种,只能运行在Windows,性能和数据安全性都很一般)
MySQL、PostgreSQL(在egreSQL基础上做的二次开发并开源出来,简称为片给pgSQL),EnterpriseDB(有一家商业公司以企业级的视角重新包装PostgreSQL)
MariaDB(MySQL作者利用早些年MySQL的开源版本开发的)
MySQL早先是非常小的数据库,连SQL接口都没有,后来MySQL的作者开发了SQL接口。
Perconna公司组织了一大帮的程序员对MySQL进行了优化和改进,改进后重新发布,经过优化后的MySQL性能比原来版本好很多。并且软件本身不收费只卖服务
世界上早期著名的公司:
Oracle(软件商)
IBM(软硬件商)
SUN(软硬件商):因为没有自己的数据库,后来买了MySQL
Oracle后来收购了Sun,与IBM红蓝两阵营形成对抗之势。
BEA公司:主要是提供Weblogic,被Oracle收购,83亿美元。
PeopleSoft:提供关系型管理软件的公司,被Oracle收购,128亿美元。
阿里巴巴去IOE化:
I:IBM的小型机
O:Oracle
E:EMC(世界级专业做存储设备的(做硬件的),如RAID、网络存储,昂贵但性能非常好)的存储设备
所以数据安全性很重要,而且数据业务很重要不能中断了,所以Oracle都放在EMC上,而Oracle要运行需要大量的CPU的运行能力需要运行在IBM的小型机上。
去IOE后依靠Linux提供一大堆PC机集群来提供海量用户的请求,把数据放在由众多PC机组成的存储集群上,而存储集群上运行的是经过自己改写后的MySQL。最后发现比原来性能更强。
OpenOffice:SUN的一套开源产品,Oracle收购后被商业化
LibreOffice:OpenOffice的作者开发的,某些性能比Openoffice更先进
关系型数据库管理系统尽管有这样那样的好处,但是由于关系型数据库设计本身定义了很多规范叫范式,如:第一范式、第二范式,这些范式极大的束缚了关系型数据库,使得关系型数据库一次查询为了满足范式,尽可能降低冗余度,设计了n个表,将来要发起一个大的查询时,必须要把多个表关联起来才能查询,而且表关联需要从内存中完成,那就意味着需要把数据从磁盘读入内存,连接起来才能完成查询,非常慢。于是现在的数据库设计就反关系化了。
反关系模型:(不再满足关系型数据库的特性了)noSQL(非关系性数据库,不再满足于关系模型的处理,而是根据业务处理的需要关注读写性能,它们也在一定程度上满足数据管理的需求,noSQL只是一种技术,它不是一种软件(与SQL一个道理))
常用noSQL:
MongoDB(文档数据库)
Redis(缓存(内存)数据库)
HBase(能够把在自我内部实现数据管理的非关系性数据库,是一个稀疏的基于键值对的数据库)