之前小程介绍了使用机器学习的办法来解决“音频标签化”的问题,并且提到了训练样本audioset跟youtube-8m的dataset,而训练模型上也提到了youtube-8m的模型。
本文对youtube-8m的模型做进一步讲解,重点介绍如何使用youtube-8m进行训练、评估与测试。
(一)youtube-8m是什么?
机器学习离不开训练样本跟训练模型,对于“音频标签化”,小程多次提到youtube-8m的训练模型,那这个youtube-8m到底是什么? 在下面这个项目的介绍里面,可以完整地了解youtube-8m到底是什么:
https://github.com/google/youtube-8m
小程用自己的话,再翻译一下。youtube-8m是google开源出来的一个用于视频标签化的启动项目,这个项目已经实现使用youtube-8m dataset(以下简称为8m-dataset)来训练、评估与测试的框架。但是,对于具体的业务需求,或者为了追求更好的训练结果(甚至可以参加比赛),读者应该基于这个框架,扩展出自己的训练模型。
所以,youtube-8m是一个基于tensorflow的机器学习的训练框架,而且已经可以使用8m-dataset样本。
(二)如何使用youtube-8m?
既然youtube-8m是一个启动项目,那么怎么使用youtube-8m来满足自己的业务需求呢? 并非所有业务需求都适合使用youtube-8m,但这里讲的是“音频标签化”也就是音频分类的业务需求是适合使用youtube-8m的。
同样,对于youtube-8m的使用,在其项目关联页面,也有介绍,读者可以详细阅读:
https://github.com/google/youtube-8m
(1)环境
环境上,首先要安装了python2.7+,并且安装了tensorflow1.8+。
可以这样检测python跟tensorflow的版本信息:
python --version
python -c ‘import tensorflow as tf; print(tf.version)’
对于python2.7的macos,可以这样安装tensorflow(需在翻墙状态;可优先考虑在虚拟环境中安装tf):
pip install --upgrade https://storage.googleapis.com/tensorflow/mac/cpu/tensorflow-1.8.0-py2-none-any.whl
关于python以及tensorflow的安装,读者可以关注“广州小程”微信公众号,并在相应的菜单项中(比如“平台开发”或“机器学习”)查阅相关的文章(比如python语言1)。
接下来具体讲解youtube-8m的使用。
(2)样本
youtube-8m框架,既可以使用8m-dataset,也可以使用audioset样本(代码做一些修改就可以使用audioset),这里以8m-dataset进行训练。
跟audioset一样,8m-dataset样本也只是特征的数据集,并非原始的视频或音频数据。
8m-dataset样本,按特征的处理,划分为两类,一类是基于帧的样本(frame-level),一类是基于视频的样本(video-level)。
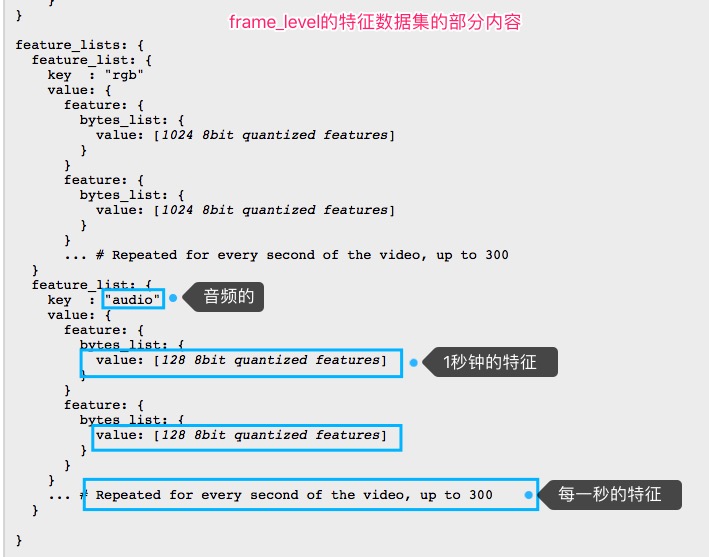
基于帧的样本的特征内容是这样的:
基于视频的样本的特征内容是这样的:
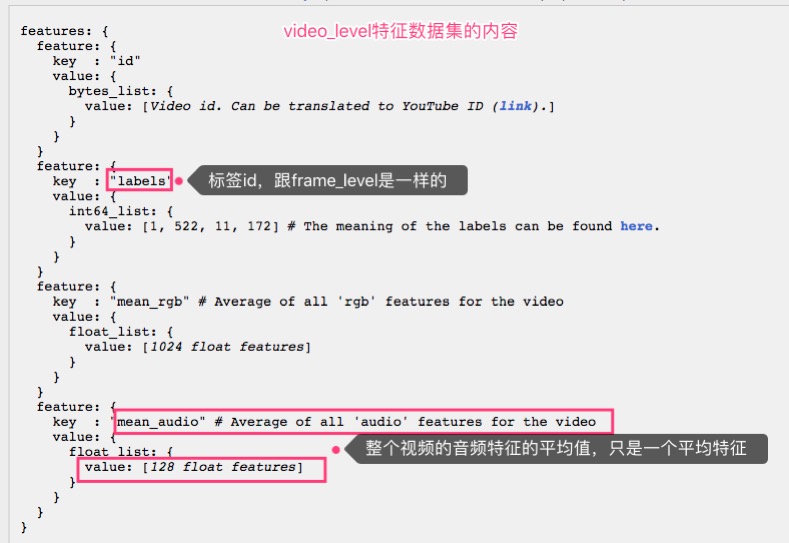
可以看出,video-level样本是对整个视频的特征作了平均,而frame-level则按帧记录了特征。这里使用机器学习的目的是实现音频标签化,可以使用每一帧的音频特征来训练,所以这里选择基于帧的样本,即frame-level的样本。
作为示范,这里并不使用全部8m-dataset样本,而只是下载其中一部分样本。
按项目的介绍,可以这样下载8m-dataset样本(网络在翻墙状态):
curl data.yt8m.org/download.py | shard=1,1000 partition=2/frame/train mirror=us python
curl data.yt8m.org/download.py | shard=1,1000 partition=2/frame/validate mirror=us python
curl data.yt8m.org/download.py | shard=1,1000 partition=2/frame/test mirror=us python
使用了http://data.yt8m.org/download.py这个脚本来下载,shard参数指定了下载数量的比例,shard=1,1000表示下载千分之一的数量,去掉这个参数则表示全部下载。
分别执行以上三个下载命令,可以下载到三部分样本,分别用于训练、评估(校验)与测试,比如小程下载到的内容是这样的:
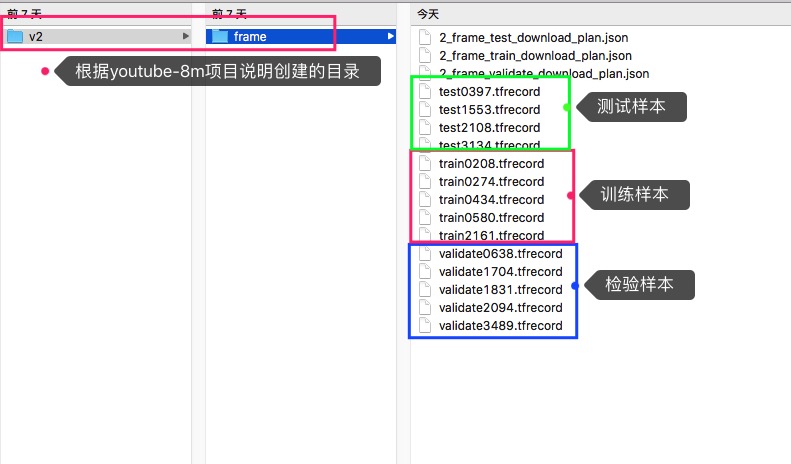
对于样本下载存放的目录,可以参考youtube-8m项目介绍的那样来创建。
然后就可以使用这些样本,分别进行训练、评估与测试。
(3)训练
先把youtube-8m项目clone下来:
git clone https://github.com/google/youtube-8m.git
这时可以看到youtube-8m项目的目录结构是这样的:
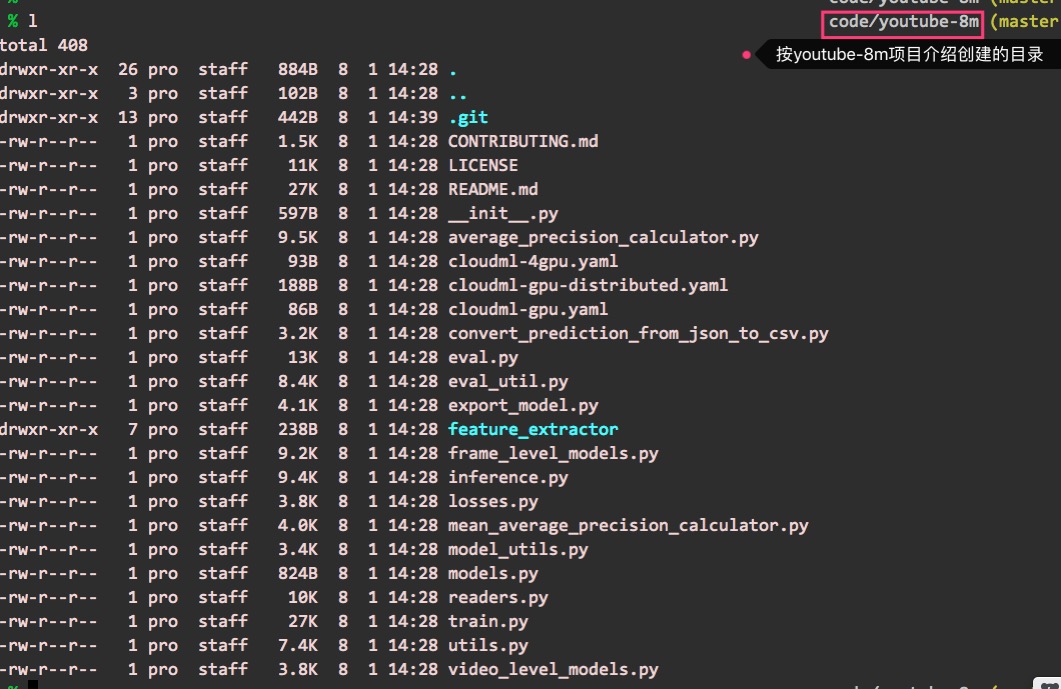
对于每个文件的作用,读者也可以在项目的介绍页面中查阅。
接下来,训练基于帧(frame-level)的模型:
python train.py --frame_features --model=FrameLevelLogisticModel --feature_names=‘rgb,audio’ --feature_sizes=‘1024,128’ --train_data_pattern="…/…/v2/frame/train*.tfrecord" --train_dir …/…/v2/models/frame/sample_model --start_new_model
参数train_data_pattern为训练样本所在目录,train_dir为生成模型所存放的目录。
对于train.py使用的参数,可以这样查看:
python train.py --help
可以看到这样的信息:
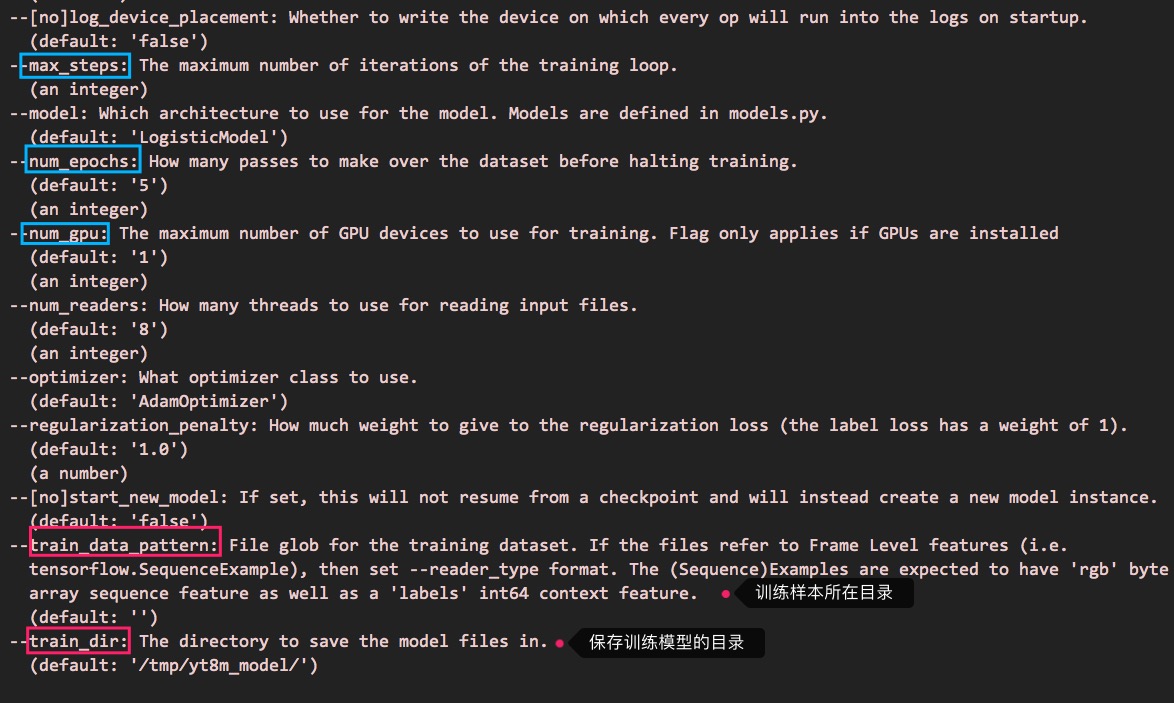
需要注意,训练这一步,最好用gpu来运行,才能保证较好的执行速度,如果在一般的机器上运行,很可能时间漫长且极占资源。
训练结束后(或被中断),在训练参数中指定的模型存放的目录中,可以看到这样的文件:
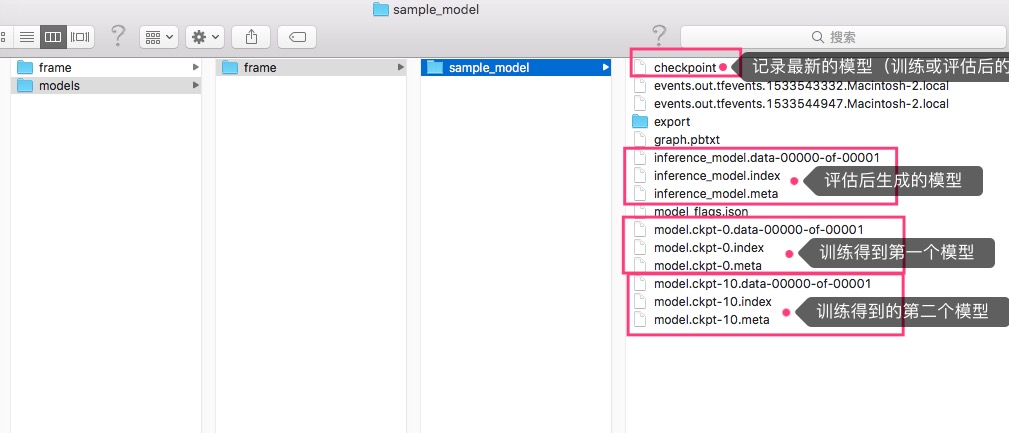
可以看到,训练过程中生成了两组模型文件,比如model.ckpt-10.xx等,而其中的inference_model.xxx文件,是小程执行了下面介绍的“评估”这一步后生成的文件。
可以看到,在训练的过程中会生成很多checkpoint文件(预测模型),评定哪一个是最佳的预测模型也是一个工作。
(4)评估
可以这样进行评估:
python eval.py --eval_data_pattern="…/…/v2/frame/validate*.tfrecord" --train_dir …/…/v2/models/frame/sample_model
参数train_dir指定了训练模型所在目录,eval.py会根据checkpoint文件加载“最新的”模型进行评估(也可以指定加载哪一组模型)。
执行评估,可以看到这样的输出(基于小程下载的样本以及训练的结果):
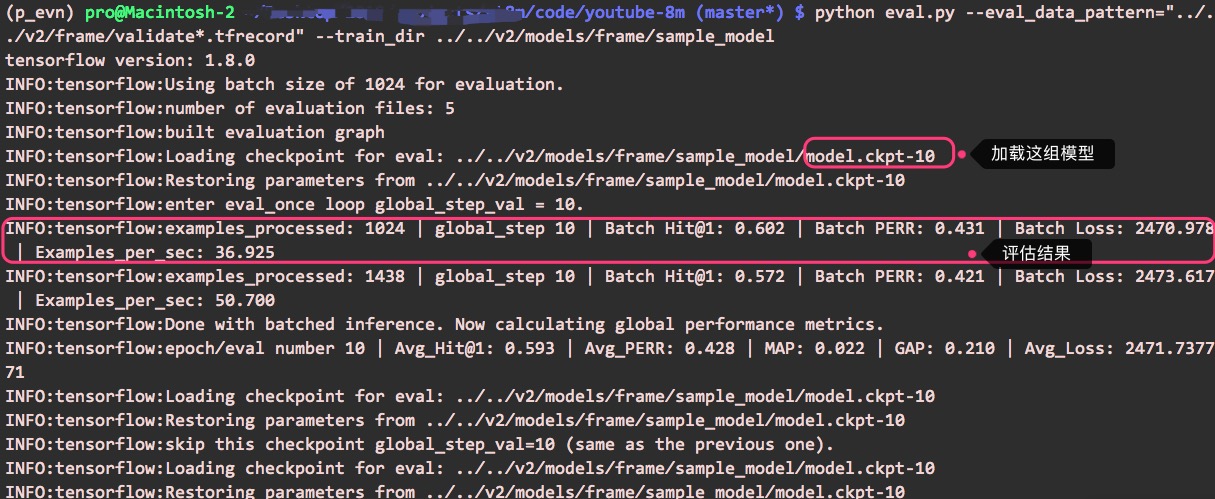
同时会生成一组新的模型(inference_model.xxx),读者可以参考上面训练结果的截图。
(5)测试
测试就是应用模型进行实际的使用(也可以评估预测模型的准确度等),可以这样进行测试:
python inference.py --train_dir …/…/v2/models/frame/sample_model --output_file=test.csv --input_data_pattern="…/…/v2/frame/test*.tfrecord"
参数train_dir跟评估的使用类似,参数output_file指定测试结果的保存文件,参数input_data_pattern指定测试样本。
执行测试,可以看到这样的输出:

然后,可以查看测试结果,这里保存在test.csv文件中,csv文件是纯文本文件,一般用于保存记录。测试结果类似这个截图:
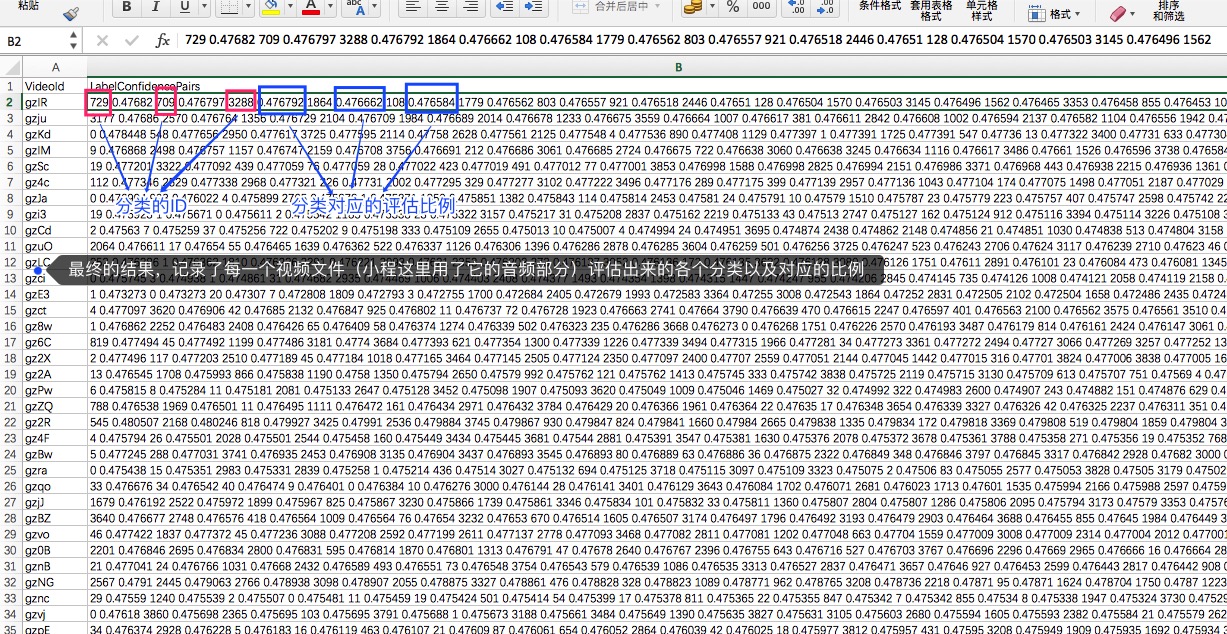
从测试结果中可以看到,已经有分类的结果,每一个分类都有对应的预测比例。但是,要想得到准确率与召回率较高的结果,还需要做更多的工作。
总结一下,本文主要介绍了如何使用youtube-8m这个项目,包括训练、评估与测试。对于训练的参数、随机性,以及如何取得较好的训练结果等,以后再作介绍。