现代投资组合理论(Modern Portfolio Theory,MPT)告诉我们投资者应该分散投资来实现最小化风险最大化投资回报。大邓刚开始学习这方面知识,用了将近一天的时候才搞懂MPT理论的推导,顺便复习了部分高中数学知识,这样会让我们更加有新信心的去使用自己编写的代码。现在我们从实战开始接触理论。
如果有想学习python的程序员,可来我的python学习扣qun:711944363,免费送python的视频教程噢!我每晚上8点还会在群内直播讲解python知识,欢迎大家前来学习。
一、资产组合理论导论
1.1 风险厌恶(Risk aversion)
在投资组合理论中,我们常常使用方差来刻画资产的风险。这里举个例子,方便大家理解。
假设你现在将要进行投资,有两种策略:
- 资产A给你带来的收益是200元,或者0元。每种情况发生的概率也是各50%
- 资产B给你带来的收益是400元,或者-200元(亏损)。每种情况发生的概率也是各50%
资产的数学期望收益
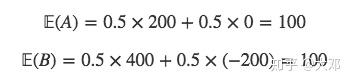
两种投资策略的波动性-标准差
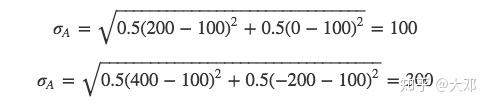
如果你是风险偏好者,你可能会选择B,因为B的潜在的最大收益最大。但是MPT理论认为大多数的投资者是风险厌恶者,不喜欢玩心跳,所以更倾向于选择A。
1.2资产组合池(portfolio)
假设我们将采用分散投资,每种资产的比例为 ``w1、w2、w3...wn``,我们知道所有投资比例之和为1,即 ``w1+w2+w3+...+wn=1`` 。假设R0、R1、R2...Rn分别代表每种资产的收益,则资产组合投资收益为
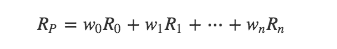
我们预期的投资组合收益为

1.3 相关性
在计算资产组合风险前,我们需要先回忆一下高中数学中的方差和相关性的计算方法。方差和相关性主要是刻画任意两个变量之间的线性关系。
X和Y的方差计算公式

1.4 风险
现在我们将要计算资产组合的风险,这里使用 ``资产组合收益的方差`` 来刻画投资风险。
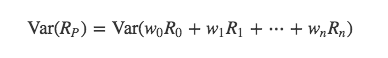
本来大邓直接看到推导完的结果,但是忽略了中间过程,心里怎么也不相信。所以花了很多时间用来找推导过程的教程和视频,终于找到一份比较详细的,现在贴给大家看。我们将该公式中的加总用累加zigma符号表示,一步步的进行推导
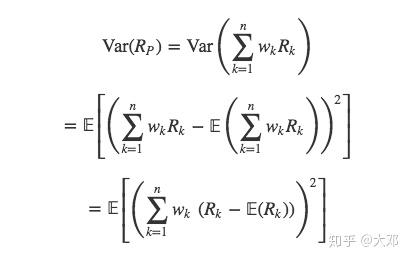
现在我们先看看简单的例子,如何将累加和的平方展开?
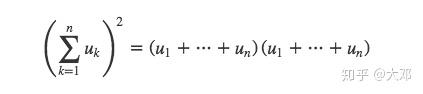
我们再将上面的公式抽象一下

因此,资产组合收益的方差可以表示为
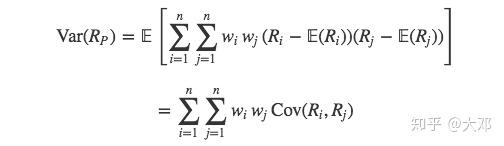
最后我们将上面的符号全部用向量(或矩阵)来表示,这样后期我们使用python写代码时候可以直接使用numpy表达。
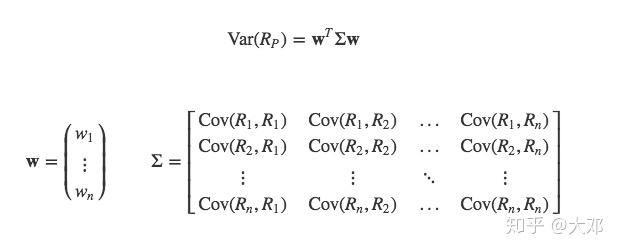
二、实战
2.1 加载数据
这里我参考JoinQuant中的一篇文章,其选取的股票的收益比较符合正太分布,我就直接拿来用吧。
'000651', ##格力电器
'600519', ##贵州茅台
'601318', ##中国平安
'000858', ##五粮液
'600887', ##伊利股份
'000333', ##美的集团
'601166', ##兴业银行
'601328', ##交通银行
'600104' ##上汽集团 我们使用tushare来获取股票数据,tushare的get_hist_data(stock_code, start, end)函数获取stock_code从start到end期间内的所有交易数据,返回的是dataframe类型。这里我们都是用close列的数据,即只用收盘价数据。
import tushare as ts
def fetch_stock_data(stock_code, stock_name, start, end):
df = ts.get_hist_data(stock_code, start=start, end=end) #前复权
df = df.close
df.name = stock_name
return df
geli = fetch_stock_data('000651', '格力电器', '2016-05-28', '2018-03-26')
geli.head()Run
date
2018-03-26 48.13
2018-03-23 48.88
2018-03-22 49.90
2018-03-21 51.70
2018-03-20 52.20
Name: 格力电器, dtype: float64现在我们将所有股票都的收盘数据都装进pandas.DataFrame中,每一列代表一只股票,每一行代表一天的收盘价
import pandas as pd
data = pd.DataFrame({'格力电器':fetch_stock_data('000651', '格力电器', '2016-05-28', '2018-03-26'),
'贵州茅台':fetch_stock_data('600519', '贵州茅台', '2016-05-28', '2018-03-26'),
'中国平安':fetch_stock_data('601318', '中国平安', '2016-05-28', '2018-03-26'),
'五粮液':fetch_stock_data('000858', '五粮液', '2016-05-28', '2018-03-26'),
'伊利股份':fetch_stock_data('600887', '伊利股份', '2016-05-28', '2018-03-26'),
'美的集团':fetch_stock_data('000333', '美的集团', '2016-05-28', '2018-03-26'),
'兴业银行':fetch_stock_data('601166', '兴业银行', '2016-05-28', '2018-03-26'),
'交通银行':fetch_stock_data('601328', '交通银行', '2016-05-28', '2018-03-26'),
'上汽集团':fetch_stock_data('600104', '上汽集团', '2016-05-28', '2018-03-26')})
data = data.dropna()
data.head()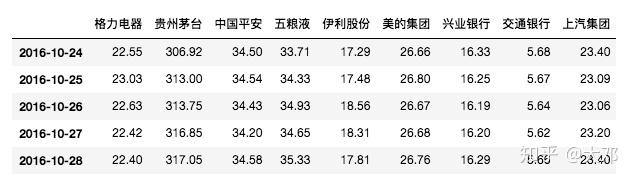
data.to_excel('stock_data.xlsx')我将整理好的数据保存到了 ``stock_data.xlsx`` 中,方便大家即使无法使用tushare也有数据可供分析。
import pandas as pd
data = pd.read_excel('stock_data.xlsx')
data.head()
将每个股票价格与最初始(2016年10月24日)的价格作比较,并据此得到之后的股价走势图
#将date列从newdata中踢出
date = data.pop('date')
#data.iloc[0, :] 选取第一行的数据
newdata = (data/data.iloc[0, :])*100昨天我们分享的可视化使用的pyplotz库,该库支持所有基于matplotlib的可视化库。今天我们用plotly这个动态可视化库来作图,正好复习下前面分享的plotly-express库,注意plotly-express是基于plotly
from plotly.offline import init_notebook_mode, iplot, plot
import plotly.graph_objs as go
init_notebook_mode()
stocks = ['格力电器', '贵州茅台', '中国平安', '五粮液', '伊利股份', '美的集团', '兴业银行', '交通银行', '上汽集团']
def trace(df, date, stock):
return go.Scatter(x = date, #横坐标日期
y = df[stock],
name=stock)#纵坐标为股价与(2016年10月24日)的比值
data = [trace(newdata,date,stock) for stock in stocks]
iplot(data)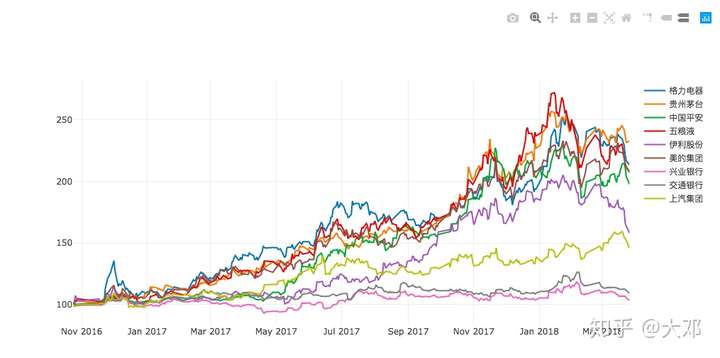
2.2 计算不同股票的均值、协方差
每年有252个交易日,用每日收益率乘以252得到年华收益率。现在需要计算每只股票的收益率,在金融领域中我们一般使用对数收益率。这里体现了pandas的强大,df.pct_change()直接就能得到股票收益率
import numpy as np
log_returns = np.log(newdata.pct_change()+1)
log_returns = log_returns.dropna()
log_returns.mean()*252Run
格力电器 0.582497
贵州茅台 0.648666
中国平安 0.524031
五粮液 0.561282
伊利股份 0.352049
美的集团 0.560136
兴业银行 0.024539
交通银行 0.068539
上汽集团 0.289760
dtype: float642.3 进行正态检验
马科维茨的投资组合理论需要满足收益率符合正态分布,scipy.stats库为我们提供了正态性测试函数
scipy.stats.normaltest 测试样本是否与正态分布不同,返回p值。
import scipy.stats as scs
def normality_test(array):
print('Norm test p-value %14.3f' % scs.normaltest(array)[1])
for stock in stocks:
print('\nResults for {}'.format(stock))
print('-'*32)
log_data = np.array(log_returns[stock])
normality_test(log_data)Run
Results for 格力电器
--------------------------------
Norm test p-value 0.000
Results for 贵州茅台
--------------------------------
Norm test p-value 0.000
Results for 中国平安
--------------------------------
Norm test p-value 0.000
Results for 五粮液
--------------------------------
Norm test p-value 0.051
Results for 伊利股份
--------------------------------
Norm test p-value 0.000
Results for 美的集团
--------------------------------
Norm test p-value 0.453
Results for 兴业银行
--------------------------------
Norm test p-value 0.000
Results for 交通银行
--------------------------------
Norm test p-value 0.000
Results for 上汽集团
--------------------------------
Norm test p-value 0.000从上面的检验中,伊利股份和兴业银行股票收益率不符合正态分布。
2.4 投资组合预期收益率、波动率
我们先随机生成一维投资组合权重向量(长度为9,与股票数量相等),因为中国股市的不允许卖空,所以投资组合权重向量中的数值必须在0到1之间。
weights = np.random.random(9)
weights /= np.sum(weights)
weights array([0.13403144, 0.11703939, 0.14125659, 0.02530677, 0.10496042,
0.16106127, 0.05155371, 0.10361131, 0.16117911])投资组合预期收益率等于每只股票的权重与其对应股票的年化收益率的乘积。
np.dot(weights, log_returns.mean())*252 0.4035947984701051投资组合波动率(方差)
np.dot(weights, np.dot(log_returns.cov()*252, weights)) 0.035798322938178584投资组合收益的年化风险(标准差)
np.sqrt(np.dot(weights, np.dot(log_returns.cov()*252, weights))) 0.189204447458770332.5 随机生成大量的投资组合权重
生成1000种随机的投资组合,即权重weights的尺寸为(1000\*9)。
import matplotlib.pyplot as plt
%matplotlib inline
port_returns = []
port_variance = []
for p in range(1000):
weights = np.random.random(9)
weights /=np.sum(weights)
port_returns.append(np.sum(log_returns.mean()*252*weights))
port_variance.append(np.sqrt(np.dot(weights.T, np.dot(log_returns.cov()*252, weights))))
port_returns = np.array(port_returns)
port_variance = np.array(port_variance)
#无风险利率设定为3%
risk_free = 0.03
plt.figure(figsize=(8, 6))
plt.scatter(port_variance, port_returns, c=(port_returns-risk_free)/port_variance, marker = 'o')
plt.grid(True)
plt.xlabel('Expected Volatility')
plt.ylabel('Expected Return')
plt.colorbar(label = 'Sharpe Ratio')
2.5.1 投资组合优化1—夏普率最大
建立statss函数来记录重要的投资组合统计数据(收益,方差和夏普比)。scipy.optimize可以提供给我们最小优化算法,而最大化夏普率可以转化为最小化负的夏普率。
import scipy.optimize as sco
def stats(weights):
weights = np.array(weights)
port_returns = np.sum(log_returns.mean()*weights)*252
port_variance = np.sqrt(np.dot(weights.T, np.dot(log_returns.cov()*252,weights)))
return np.array([port_returns, port_variance, port_returns/port_variance])
#最小化夏普指数的负值
def min_sharpe(weights):
return -stats(weights)[2]
#给定初始权重
x0 = 9*[1./9]
#权重(某股票持仓比例)限制在0和1之间。
bnds = tuple((0,1) for x in range(9))
#权重(股票持仓比例)的总和为1。
cons = ({'type':'eq', 'fun':lambda x: np.sum(x)-1})
#优化函数调用中忽略的唯一输入是起始参数列表(对权重的初始猜测)。我们简单的使用平均分布。
opts = sco.minimize(min_sharpe,
x0,
method = 'SLSQP',
bounds = bnds,
constraints = cons)
optsRun
fun: -2.7277947674404794
jac: array([ 1.08440101e-01, -4.65214252e-05, 3.44902277e-04, 7.20474541e-01,
5.15412062e-01, -2.46465206e-05, 3.42730999e-01, -1.48534775e-04,
-5.43147326e-04])
message: 'Optimization terminated successfully.'
nfev: 111
nit: 10
njev: 10
status: 0
success: True
x: array([1.07588996e-16, 4.93897426e-01, 2.37878143e-01, 6.47455750e-17,
5.74725095e-17, 1.14655596e-01, 8.60056411e-17, 6.88721816e-02,
8.46966532e-02])最优投资组合权重向量,小数点保留3位
opts['x'].round(3) array([0. , 0.494, 0.238, 0. , 0. , 0.115, 0. , 0.069, 0.085])sharpe最大的组合3个统计数据分别为:
stats(opts['x']).round(3)
array([0.539, 0.197, 2.728])2.5.2 投资组合优化2——方差最小
接下来,我们通过方差最小来选出最优投资组合。
#但是我们定义一个函数对 方差进行最小化
def min_variance(weights):
return stats(weights)[1]
optv = sco.minimize(min_variance,
x0,
method = 'SLSQP',
bounds = bnds,
constraints = cons)
optvRun
fun: 0.1260429626044057
jac: array([0.15127511, 0.12627605, 0.1532943 , 0.14743594, 0.12581278,
0.1258321 , 0.12612321, 0.1258938 , 0.12583541])
message: 'Optimization terminated successfully.'
nfev: 88
nit: 8
njev: 8
status: 0
success: True
x: array([0.00000000e+00, 2.13881938e-01, 0.00000000e+00, 8.07576429e-18,
3.06402571e-02, 1.40860179e-02, 3.22191709e-01, 3.65127109e-01,
5.40729695e-02])方差最小的最优投资组合权重向量
optv['x'].round(3) array([0. , 0.214, 0. , 0. , 0.031, 0.014, 0.322, 0.365, 0.054])得到的投资组合预期收益率、波动率和夏普指数
stats(optv['x']).round(3) array([0.206, 0.126, 1.634])2.5.3 组合的有效边界
有效边界是由一系列既定的目标收益率下方差最小的投资组合点组成的。在最优化时采用两个约束,1.给定目标收益率,2.投资组合权重和为1。
def min_variance(weights):
return statistics(weights)[1]
#在不同目标收益率水平(target_returns)循环时,最小化的一个约束条件会变化。
target_returns = np.linspace(0.0,0.5,50)
target_variance = []
for tar in target_returns:
#给定限制条件:给定收益率、投资组合权重之和为1
cons = ({'type':'eq','fun':lambda x:stats(x)[0]-tar},{'type':'eq','fun':lambda x:np.sum(x)-1})
res = sco.minimize(min_variance, x0, method = 'SLSQP', bounds = bnds, constraints = cons)
target_variance.append(res['fun'])
target_variance = np.array(target_variance)下面是最优化结果的展示。
叉号:构成的曲线是有效前沿(目标收益率下最优的投资组合)
红星:sharpe最大的投资组合
黄星:方差最小的投资组合
plt.figure(figsize = (8,4))
#圆点:随机生成的投资组合散布的点
plt.scatter(port_variance, port_returns, c = port_returns/port_variance,marker = 'o')
#叉号:投资组合有效边界
plt.scatter(target_variance,target_returns, c = target_returns/target_variance, marker = 'x')
#红星:标记夏普率最大的组合点
plt.plot(stats(opts['x'])[1], stats(opts['x'])[0], 'r*', markersize = 15.0)
#黄星:标记方差最小投资组合点
plt.plot(stats(optv['x'])[1], stats(optv['x'])[0], 'y*', markersize = 15.0)
plt.grid(True)
plt.xlabel('expected volatility')
plt.ylabel('expected return')
plt.colorbar(label = 'Sharpe ratio')Run
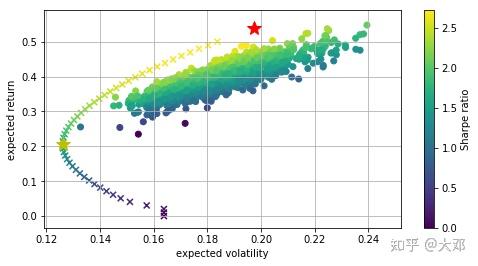
从黄色五角星到红色五角星是投资最有效的组合,这一系列的点所组成的边界就叫做投资有效边界 。这条边界的特点是同样的风险的情况下获得的收益最大,同样的收益水平风险是最小的。从这条边界也印证了风险与收益成正比,要想更高的收益率就请承担更大的风险,但如果落在投资有效边界上,性价比最高。