版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/qq_38038143/article/details/88641288
前言
使用Yarn 作为集群管理器,启动Spark 时,无法再从SparkUI-4040 端口查看相应的信息。只能从Hadoop 的Yarn、历史服务器查看,但是默认是没有开启。所以,这里展示如何配置开启历史服务器、查看日志。
Hadoop-2.7.3
Spark-2.4.0
1. HDFS 配置
确保你的Hadoop 已经完成配置,并且已经能够正常启动。
下面,在已有的Hadoop 配置上,增加配置。
- mapred-site.xml
<!--Spark Yarn-->
<property>
<name>mapreduce.jobhistory.address</name>
<value>master:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>master:19888</value>
</property>
- yarn-site.xml
<!--Spark Yarn-->
<!-- 是否开启聚合日志 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 配置日志服务器的地址,work节点使用 -->
<property>
<name>yarn.log.server.url</name>
<value>http://master:19888/jobhistory/logs/</value>
</property>
<!-- 配置日志过期时间,单位秒 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>86400</value>
</property>
将master 改为你的主节点的主机名,直接复制到文件末尾即可。
修改完成后,将这两个配置文件分别复制到各个子节点。
并且,复制到Spark 安装目录下的 conf/ 目录(注:如果没有复制过hdfs-yarn.xml,还应将其复制过去)
2. Spark 配置
spark-defaults.sh
文件末尾添加(conf/ 目录下):
# 事件日志
spark.eventLog.enabled=true
spark.eventLog.compress=true
# 保存在本地
# spark.eventLog.dir=file://usr/local/hadoop-2.7.3/logs/
# spark.history.fs.logDirectory=file://usr/local/hadoop-2.7.3/logs/
# 保存在hdfs上
spark.eventLog.dir=hdfs://master:9000/tmp/spark-yarn-logs
spark.history.fs.logDirectory=hdfs://master:9000/tmp/spark-yarn-logs
spark.yarn.historyServer.address=spark-master:18080
创建HDFS 日志目录:
该目录与上述yarn-site.xml 中的目录需要一致:
hdfs dfs -mkdir -p /tmp/spark-yarn-logs
3. 启动
# 启动HDFS
start-all.sh
# 启动Hadoop 历史服务器
mr-jobhistory-daemon.sh start historyserver
# 启动Spark 集群
sbin/start-all.sh
# 启动Spark 历史服务器
sbin/start-history-server.sh
博主的集群各节点进程如下:

其中,JobHistoryServer 是Hadoop历史服务器。HistoryServer 是Spark 历史服务器。
4. 查看日志
-
HDFS 查看
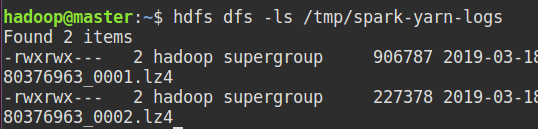
-
http://master:18080 历史服务器
比如博主这里有以前运行的两个应用的日志。

比如,点击 application_1552880376963_0002 查看相关信息(界面和 4040 端口几乎相同):

-
http://master:19888 任务历史

需要注意的是:
- 每次重新启动集群时都需要开启Hadoop 和 Spark 的历史服务器进程。
- 如果当前正在运行一个应用,在HDFS 会看到生成相应的文件(但后缀与其他文件不同)。并且在历史服务器中查看不到正在运行应用的相关信息(与历史二字相符,可以在Yarn管理地址:http://master:8099/cluster 查看)。只有在应用结束时,HDFS上的文件后缀会自动被更改,历史服务器也能查看到相应信息。
其他内容还在探索中。
参考:https://blog.csdn.net/xfks55/article/details/80857885?tdsourcetag=s_pctim_aiomsg