kafka连接flink操作流程
1、简介
1.1、Kafka Consumer提供了2种API:high level与low level(SimpleConsumer)。
(1)high level consumer的API较为简单,不需要关心offset、partition、broker等信息,kafka会自动读取zookeeper中该consumer group的last offset。
(2)low level consumer也叫SimpleConsumer,这个接口非常复杂,以下几种情况才会用到:
1、Read a message multiple times
2、Consume only a subset of the partitions in a topic in a process
3、Manage transactions to make sure a message is processed once and only once
2、Flink的开发准备
Flink提供了high level的API来消费kafka的数据:flink-connector-kafka-0.10_2.10。注意,这里的0.10代表的是kafka的版本,你可以通过maven来导入kafka的依赖,具体如下:
例如你的kafka安装版本是“kafka_2.10-0.10.2.1”,即此版本是由scala2.10编写,kafka的自身版本是0.10.2.1.那此时你需要添加如下的内容到maven的pom.xml文件中:
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka-0.10_2.10</artifactId>
<version>${flink.version}</version></dependency>
注意:
${flink.version}是个变量,自己调整下代码,例如可以直接写1.3.2。我的项目 里采用的是添加了properties来控制
${flink.version}:
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<flink.version>1.3.2</flink.version></properties>
当时我入门的时候觉得很奇怪为什么会有maven出现,那是因为在这个demo中flink和kafka的连接部分使用了scala,而相关运用会在本文的后半部分出现。
3、集群环境准备
这里主要是介绍下Flink集群与kafka集群的搭建。
基础的软件安装包括JDK、scala、hadoop、zookeeper、kafka以及flink就不介绍了,直接看下flink的集群配置以及kafka的集群配置。
zookeeper–3.4.6
hadoop–2.7.3
kafka_2.10-0.10.1.2.6.3.0-235
flink–1.3.2
3.1、Flink集群配置(standalone且没有用zookeeper的HA)
(本文默认配置的三台虚拟机为master1、master2、slave1)
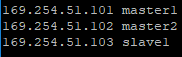
如图是我的虚拟机的映射 /etc/hosts
3.1.1.下载Flink压缩包
下载地址:http://flink.apache.org/downloads.html。
我集群环境是hadoop2.7,Scala2.11版本的,所以下载的是:
flink-1.3.2-bin-hadoop27-scala_2.11.tgz。
3.1.2.解压
分别上传至master1、master2、slave1的相同目录(默认下载的地址为 /opt/下)
,找到压缩版并执行如下命令解压:
tar xzf flink-1.3.2-bin-hadoop27-scala_2.11.tgz
3.1.3.配置master节点
选择一个 master节点(JobManager)然后在conf/flink-conf.yaml中设置jobmanager.rpc.address 配置项为该节点的IP 或者主机名。确保所有节点有有一样的jobmanager.rpc.address 配置。
jobmanager.rpc.address: master1
jobmanager.rpc.port: 6123
jobmanager.heap.mb: 1024
taskmanager.heap.mb: 1024
taskmanager.numberOfTaskSlots: 1
taskmanager.memory.preallocate: false
parallelism.default: 1
jobmanager.web.port: 8081
作者这里是在master1中配置上文信息然后将其拷贝至其他两台虚拟机(master2、slave1)
(关于配置作用参考我写的另外两篇“Flink Jobmanager HA配置(standalone)”、“Flink运行时之TaskManager执行Task”)
3.1.4.配置slaves
将所有的 slave 节点 (TaskManager)的IP 或者主机名(一行一个)填入/opt/flink-1.3.2/conf/slaves文件中,并保证三个节点的slaves文件都一致
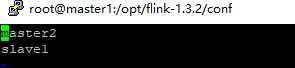
3.1.5.注意
问https://ci.apache.org/projects/flink/flink-docs-release-1.0/setup/config.html查看更多可用的配置项。为了使Flink 更高效的运行,还需要设置一些配置项。
以下都是非常重要的配置项:
1、TaskManager总共能使用的内存大小(taskmanager.heap.mb)
2、每一台机器上能使用的 CPU 个数(taskmanager.numberOfTaskSlots)
3、集群中的总 CPU个数(parallelism.default)
4、临时目录(taskmanager.tmp.dirs)
3.2、kafka集群配置
3.2.1、环境变量
省略(其实不配置也没事,只不过要知道自己文件安装的kafka的bin目录在哪,每次在bin目录下启动)
3.2.2、配置config/zookeeper.properties
由于kafka集群依赖于zookeeper集群,所以kafka提供了通过kafka去启动zookeeper集群的功能,当然也可以手动去启动zookeeper的集群而不通过kafka去启动zookeeper的集群。 (配置内容如下)
dataDir=/usr/hdp/2.6.3.0-235/zookeeper/data
(注意这里的dataDir最好不要指定/tmp目录下,因为机器重启会删除此目录下的文件。且指定的新路径必须存在。)
dataLogDir=/usr/hdp/2.6.3.0-235/zookeeper
clientPort=2181
maxClientCnxns=100
tickTime=2000
initLimit=10
syncLimit=5
3.2.3、配置config/server.properties
这个文件是启动kafka集群需要指定的配置文件,注意2点:
# The id of the broker. This must be set to a unique integer for each broker.
broker.id=0
############################# Socket Server Settings #############################
# The port the socket server listens on#port=9092
listeners=PLAINTEXT://:9092
broker.id在kafka集群的每台机器上都不一样,我这里3台集群分别是0、1、2.
############################# Zookeeper #############################
# Zookeeper connection string (see zookeeper docs for details).# This is a comma separated host:port pairs, each corresponding to a zk# server. e.g. "127.0.0.1:3000,127.0.0.1:3001,127.0.0.1:3002".# You can also append an optional chroot string to the urls to specify the# root directory for all kafka znodes.
zookeeper.connect=master1:2181,master2:2181,slave1:2181
# Timeout in ms for connecting to zookeeper
zookeeper.connection.timeout.ms=6000
zookeeper.connect要配置kafka集群所依赖的zookeeper集群的信息,hostname:port。
3.2.4、复制kafka路径及环境变量到其他kafka集群的机器,并修改server.properties中的broker_id. (master2的broker_id = 1,slave1的broker_id = 2)
3.3、启动kafka集群+Flink集群
3.3.1、首先启动zookeeper集群(3台zookeeper机器都要启动):
root@master1:/usr/local/zookeeper/zookeeper-3.4.6# ./bin/zkServer.sh start
root@master2:/usr/local/zookeeper/zookeeper-3.4.6# ./bin/zkServer.sh start
root@slave1:/usr/local/zookeeper/zookeeper-3.4.6# ./bin/zkServer.sh start
验证zookeeper集群:
进程是否启动;zookeeper集群中是否可以正常显示leader以及follower。
root@master1:/usr/local/zookeeper/zookeeper-3.4.6# jps3295 QuorumPeerMain
root@master1:/usr/local/zookeeper/zookeeper-3.4.6# ./bin/zkServer.sh statusJMX enabled by defaultUsing config: /usr/local/zookeeper/zookeeper-3.4.6/bin/…/conf/zoo.cfgMode: follower
root@mater2:/usr/local/zookeeper/zookeeper-3.4.6# ./bin/zkServer.sh statusJMX enabled by defaultUsing config: /usr/local/zookeeper/zookeeper-3.4.6/bin/…/conf/zoo.cfgMode: follower
root@mater2:/usr/local/zookeeper/zookeeper-3.4.6#
root@mater2:/usr/local/zookeeper/zookeeper-3.4.6# ./bin/zkServer.sh statusJMX enabled by defaultUsing config: /usr/local/zookeeper/zookeeper-3.4.6/bin/…/conf/zoo.cfgMode: leader
root@mater2:/usr/local/zookeeper/zookeeper-3.4.6/bin#
3.3.2、启动kafka集群(3台都要启动)
root@master1:/usr/local/kafka/kafka_2.10-0.8.2.1# ./bin/kafka-server-start.sh conf/server.properties &
root@master2:/usr/local/kafka/kafka_2.10-0.8.2.1# ./bin/kafka-server-start.sh conf/server.properties &
root@slave1:/usr/local/kafka/kafka_2.10-0.8.2.1# ./bin/kafka-server-start.sh conf/server.properties &
验证:
进程;日志
3512 Kafka
3.3.3、启动hdfs(master上启动即可)
[root@master1 ~]#systemctl start hadoop-hdfs-namenode
[root@master1 ~]#systemctl start hadoop-hdfs-datanode
[root@master2 ~]#systemctl start hadoop-hdfs-secondarynamenode
[root@master2 ~]#systemctl start hadoop-hdfs-datanode
[root@slave1 ~]#systemctl start hadoop-hdfs-datanode
验证:进程及webUI
webUI:50070,默认可配置
3.3.4、启动Flink集群(master即可,当初Flink解压在哪就在哪启动)
[root@master1 flink-1.3.2]# ./bin/start-cluster.sh
Starting cluster.
Starting jobmanager daemon on host master1.
Starting taskmanager daemon on host master2.
Starting taskmanager daemon on host slave1.
验证:进程及WebUI
root@master1:# jps4411 JobManager
root@master2:# jps4151 TaskManager
root@slave1:# jps4110 TaskManager
WebUI:8081(默认,可配置)
4、编写Flink程序,实现consume kafka的数据(demo)
4.1、代码
这里就是简单的实现接收kafka的数据,要指定zookeeper以及kafka的集群配置,并指定topic的名字。
最后将consume的数据直接打印出来。
import java.util.Properties
import org.apache.flink.streaming.api.{CheckpointingMode, TimeCharacteristic}
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer010
import org.apache.flink.streaming.util.serialization.SimpleStringSchema
/**
* 用Flink消费kafka
*/
object ReadingFromKafka {
private val ZOOKEEPER_HOST = "master:2181,worker1:2181,worker2:2181"
private val KAFKA_BROKER = "master1:9092,master2:9092,slave1:9092"
private val TRANSACTION_GROUP = "transaction"
def main(args : Array[String]){
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
env.enableCheckpointing(1000)
env.getCheckpointConfig.setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE)
// configure Kafka consumer
val kafkaProps = new Properties()
kafkaProps.setProperty("zookeeper.connect", ZOOKEEPER_HOST)
kafkaProps.setProperty("bootstrap.servers", KAFKA_BROKER)
kafkaProps.setProperty("group.id", TRANSACTION_GROUP)
//topicd的名字是new,schema默认使用SimpleStringSchema()即可
val transaction = env
.addSource(
new FlinkKafkaConsumer010[String]("new", new SimpleStringSchema(), kafkaProps)
)
transaction.print()
env.execute()
}
}
4.2、打包:
本文的打包将在windows操作系统下进行,运用到maven+scala+idea,用插件的形式进行打包(相关文档参考:“Flink与Kafka连接的jar包创建过程”)
4.3、发布到集群
root@master:/opt/flink-1.3.2/bin# flink run -c wikiedits.ReadingFromKafka /root/Documents/wiki-edits-0.1.jar
(这里的wikiedits.ReadingFromKafka是scala中mainclass的路径,/root/Documents/wiki-edits-0.1.jar则是你打完的包的路径)
验证:进程及WebUI
root@master:/opt/flink-1.3.2/bin# jps6080 CliFrontend
5、kafka produce数据,验证flink是否正常消费
5.1、通过kafka console produce数据
之前已经在kafka中创建了名字为new的topic,因此直接produce new的数据:
root@master1:/usr/hdp/2.6.3.0-235/kafka/bin# kafka-console-producer.sh --broker-list master:9092,worker1:9092,worker2:9092 --topic test
生产数据:
5.2、查看flink的标准输出中,是否已经消费了这部分数据:
root@master2:/opt/flink-1.3.2/log# ls -l | grep out
-rw-r--r-- 1 root root 254 6月 29 09:37 flink-root-taskmanager-0-worker2.out
root@worker2:/usr/local/flink/flink-1.0.3/log#
我们在worker2的log中发现已经有了数据,下面看看内容:
OK,没问题,flink正常消费了数据。
6、总结
kafka作为一个消息系统,本身具有高吞吐、低延时、持久化、分布式等特点,其topic可以指定replication以及partitions,使得可靠性和性能都可以很好的保证。
Kafka+Flink的架构,可以使flink只需关注计算本身。