了解Hadoop架构
Hadoop可运行于一般的商用服务器上,具有高容错、高可靠性、高扩展性等特点。(特别适合写一次,读多次的场景)
其架构如下:
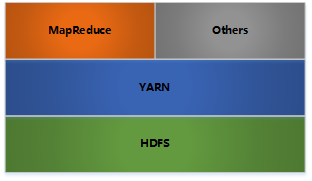
HDFS: 分布式文件存储(可靠性由心跳机制和冗余提供)
YARN: 分布式资源管理
MapReduce: 分布式计算
Others: 利用YARN的资源管理功能实现其他的数据处理方式
内部各个节点基本都是采用主从架构。
之前HDFS和MapReduce都有过介绍(https://blog.csdn.net/No_Game_No_Life_/article/details/87919751),这里说说YARN:
YARN - ResourceManager
负责全局的资源管理和任务调度,把整个集群当成计算资源池,只关注分配,不管应用,且不负责容错。
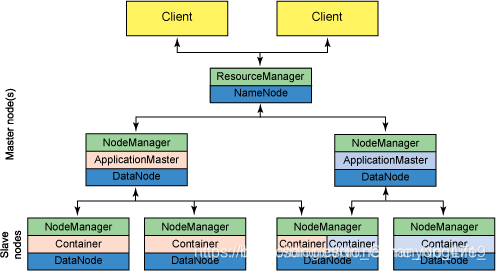
- ResourceManager是全局的,负责对于系统中的所有资源有最高的支配权。
- ApplicationMaster 每一个job有一个ApplicationMaster 。
- NodeManager,NodeManager是基本的计算框架。
- NodeManager 是客户端框架负责 containers, 监控他们的资源使用 (cpu, 内存, 磁盘, 网络) 和上报给 ResourceManager/Scheduler.
- ApplicationMaster首先它是一个框架库,它的功能官网说的不够系统,大意,由于NodeManager 执行和监控任务需要资源,所以通过ApplicationMaster与ResourceManager沟通,获取资源。换句话说,ApplicationMaster起着中间人的作用。
我觉得这里的一套主从系统和zookeeper的主从不一样,NameNode不负责任务的分配,而是通过yarn进行资源的管理和分配。并且HDFS的NameNode与zookeeper的主节点作用不一样,zk的主节点是选举产生,并且能够被second主节点所替代。但是HDFS的Second NameNode不负责NameNode的崩溃。
适合
- 大规模数据
- 流式数据(写一次,读多次)
- 商用硬件(一般硬件)
不适合 - 低延时的数据访问
- 大量的小文件
- 频繁修改文件(基本就是写1次)
Hadoop 读取数据
通过InputFormat决定读取的数据的类型,然后拆分成一个个InputSplit,每个InputSplit对应一个Map处理,RecordReader读取InputSplit的内容给Map。
- InputFormat
决定读取数据的格式,可以是文件或数据库等。
功能
- 验证作业输入的正确性,如格式等
- 将输入文件切割成逻辑分片(InputSplit),一个InputSplit将会被分配给一个独立的Map任务
- 提供RecordReader实现,读取InputSplit中的"K-V对"供Mapper使用
方法
List getSplits(): 获取由输入文件计算出输入分片(InputSplit),解决数据或文件分割成片问题
RecordReader <k,v>createRecordReader():</k,v> 创建RecordReader,从InputSplit中读取数据,解决读取分片中数据问题
- InputSplit
代表一个个逻辑分片,并没有真正存储数据,只是提供了一个如何将数据分片的方法。一个InputSplit给一个单独的Map处理。
public abstract class InputSplit {
/**
* 获取Split的大小,支持根据size对InputSplit排序.
*/
public abstract long getLength() throws IOException, InterruptedException;
/**
* 获取存储该分片的数据所在的节点位置.
*/
public abstract String[] getLocations() throws IOException, InterruptedException;
}
源码中Split内有Location信息,利于数据局部化。
- RecordReader
将InputSplit拆分成一个个<key,value>对给Map处理。
注意问题
大量小文件如何处理?
CombineFileInputFormat可以将若干个Split打包成一个,目的是避免过多的Map任务(因为Split的数目决定了Map的数目,大量的Mapper Task 创建销毁开销将是巨大的)
怎么计算split的?
通常一个split就是一个block,这样做的好处是使得Map可以在存储有当前数据的节点上运行本地的任务,而不需要通过网络进行跨节点的任务调度。
通过mapred.min.split.size, mapred.max.split.size, block.size来控制拆分的大小。
如果mapred.min.split.size大于block size,则会将两个block合成到一个split,这样有部分block数据需要通过网络读取。
如果mapred.max.split.size小于block size,则会将一个block拆成多个split,增加了Map任务数。

遇到这种拆分,Hadoop有一套自己的处理方式:
通常Hadoop使用的InputSplit是FileSplit,一个FileSplit主要存储了三个信息<path, start, 分片length>。假设根据设置分片大小为100,那么一个250字节大小的文件切分之后,我们会得到如下的FileSplit:
<path, 0, 100>
<path, 100, 100>
<path, 200, 50>
因此,事实上,每个MapReduce程序得到的只是类似<path, 0, 100>的信息。当MapReduce程序开始执行时,会根据path构建一个FSDataInputStream,定位到start,然后开始读取数据。在处理一个FileSplit的最后一行时,当读取到一个FileSplit的最后一个字符时,如果不是换行符,那么会继续读取下一个FileSplit的内容,直到读取到下一个FileSplit的第一个换行符。这样子就保证我们不会得到一个不完整的行了。
那么当MapReduce在处理下一个FileSplit的时候,怎么知道上一个FileSplit有没有已经处理了这个FileSplit的第一行内容?
我们只需要检查一下前一个FileSplit的最后一个字符是不是换行符,如果是,那么当前Split的第一行还没有被处理,如果不是,表示当前Split的第一行已经被处理,我们应该跳过。