教程目录
0x00 教程内容
- Kafka的获取
- 上传安装包到集群
- 安装Kafka集群
- Kafka集群校验
0x01 Kafka的获取
1. 官网下载
a. 为了统一,此处下载HBase1.2.6版本 :
http://archive.apache.org/dist/kafka/1.0.0/
选择1.0.0/kafka_2.11-1.0.0.tgz进行下载
2. 添加微信:shaonaiyi888
3. 关注公众号:邵奈一
a. 回复kafka获取
0x02 上传安装包到集群
1. 上传安装包到虚拟机

PS:如果不是docker部署的集群,则直接上传到虚拟机即可,因为,每台虚拟机就是一个节点。
2. 复制安装包到master节点
docker cp kafka_2.11-1.0.0.tgz hadoop-master:/root
sh ~/master.sh
0x03 安装Kafka集群
1. 解压Kafka
a. 解压安装包(-C为指定解压到/usr/local路径)
tar -zxvf kafka_2.11-1.0.0.tgz -C /usr/local
2. 配置Kafka
a. 修改配置文件server.properties($KAFKA_HOME/config):
可查看解压后的文件夹:ll /usr/local/

cd /usr/local/kafka_2.11-1.0.0/config
vi server.properties
- 修改日志路径:
log.dirs=/root/logs/kafka-logs - 修改zookeeper的连接节点(非编辑模式下输入/zookeeper.con可进行查找):

zookeeper.connect=hadoop-master:2181,hadoop-slave1:2181,hadoop-slave2:2181
b. 创建日志路径目录
mkdir -p /root/logs/kafka-logs
c. 配置环境变量(可看到docker生成节点时默认配好的其他环境变量)
vi /etc/profile
export KAFKA_HOME=/usr/local/kafka_2.11-1.0.0
export PATH=$PATH:$KAFKA_HOME/bin

使配置生效(echo一下有内容输入,说明已经配好)
source /etc/profile
3. 在同步Kafka到slave1、slave2
a. 将kafka_2.11-1.0.0拷贝到slave1和slave2上
scp -r /usr/local/kafka_2.11-1.0.0 root@hadoop-slave1:/usr/local/
scp -r /usr/local/kafka_2.11-1.0.0 root@hadoop-slave2:/usr/local/
如果你的windows系统睡眠或者关机了,要在slave1、slave2启动一下ssh(没报错则忽略):
/etc/init.d/ssh start
b. 修改slave1、slave2 配置文件的broker.id:
vi /usr/local/kafka_2.11-1.0.0/config/server.properties
slave1的为:broker.id=1

slave2的为:broker.id=2

c. 配置slave1、slave2的环境变量,记得要source一下
0x04 Kafka集群校验
1. 确保ZK集群已经启动
a. 查看进程(如有zk进程,则不需执行b.c.步):
~/jps_all.sh
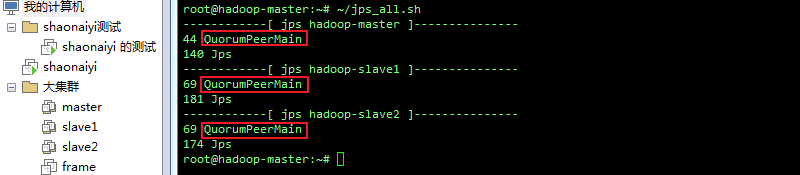
b. 三个节点上启动zk:
source /etc/profile
zkServer.sh start
ps:执行完b步后再查看进程,发现ZK进程都有了
如果zkServer.sh start无法执行,请先source一下环境变量
2. 启动Kafka集群
a. 三个节点均执行(后台启动命令)
kafka-server-start.sh -daemon $KAFKA_HOME/config/server.properties
b. 查看进程(有则表示启动成功)
~/jps_all.sh

ps:也可以这样启动(了解即可):
分别在master、slave1、slave2上执行:
cd /usr/local/kafka_2.11-1.0.0
mkdir logs
nohup bin/kafka-server-start.sh config/server.properties >/usr/local/kafka_2.11-1.0.0/logs/server.log 2>&1 &
0xFF 总结
- 花了很大的力气,终于将大数据常用的组件全部安装好,当然期间肯定还会存在一些小问题,但是问题不大,跟着我的步骤操作下来,一定能够搭建出来的,后期我会一步一步进行优化。而且会出优化及整理文章,请大家留意。
- 后期我会将此环境上传到仓库(->待补充链接),供大家学习使用。
作者简介:邵奈一
大学大数据讲师、大学市场洞察者、专栏编辑
公众号、微博、CSDN:邵奈一
本系列课均为本人:邵奈一原创,如转载请标明出处