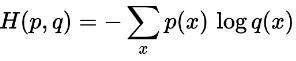信息论
信息论(Information Theory)是概率数理统计分支,我们主要看信息论在人工智能中的应用,所以目前只关注相关的信息。例如基于信息增益的决策树,最大熵模型, 特征工程中特征选取时用到的互信息,模型损失函数的交叉熵(cross-entropy)。信息论中log默认以2为底。
基础
1.熵
直观来说熵就是表示事情不确定性的因素度量,熵越大不确定性就越大,而不确定性越大,带来的信息则越多,所以在熵越高,带来的信息越多,不确定性越强。但是确定的东西,带来的不确定性很小,信息也很少,所以熵很低。熵=不确定性=信息量。他们三个成正比例。例如太阳东升西落,熵就为0。一枚质地均匀的硬币,正反面的出现,熵就为1。
公式
设X为离散随机变量,概率分布:
P ( X = xi ) = pi, i = 1,2,3,…,n
则随机变量X的熵为:
H(p) = -∑ pi * log pi
由上式可以得出,太阳东升西落、硬币正反面的熵运算。
2.条件熵
信息增益理解之前我们要理解一下条件熵,信息增益字面理解,信息增加后对最后的目标结果有多大的益处。也就是说通过选择合适的X特征作为判断信息,让Y的不确定性减少的程度越大,则选择出的X越好。而条件熵H(Y|X)表达就是给定X后,Y的不确定性是多少。
H ( Y | X ) = -∑ pi * H ( Y | X = xi )
这里 pi = P( X = xi ) ,i = 1,2,…,n
熵和条件熵中的概率如果通过估计得到,例如极大似然估计,则熵和条件熵将会,变名字经验熵和经验条件熵。
交叉熵
交叉熵被设置为模型的损失函数,表示的两个概率分布的相似程度,交叉熵越小代表预测的越接近真实。