今天给大家推荐一个Python做的简单文字识别小程序,很简单,你应该能一学就会。
数字识别
需求不多数,直接讲思路吧,每次进入特定界面后,截图并且进行文字识别,计算出剩余时间,然后开启倒计时线程,倒计时结束后进行切换游戏角色的操作。
图像识别需要在代码中引入pytesseract模块,并下载安装tesseract-ocr-setup,安装过程中可以根据需要下载语言包(如简体中文、繁体中文),安装完毕后需在环境变量中将tesseract-ocr的安装目录分别添加到path和TESSDATA_PREFIX(新建)中。

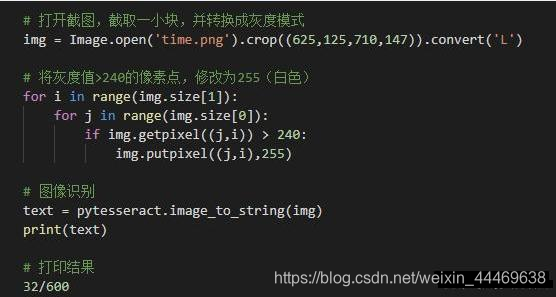
代码很简单,打开图片并截取,然后识别成数字,总共只需要两行代码。但是意外情况还是发生了,32/600被识别成了327600,讲道理数字如此清晰,tesseract-ocr不可能犯这么低级的错误。我将截图放大到800%时发现了玄机:截图的背景不是纯色,而是由灰白相间的横条组成,字符“/”的上段有两条灰色横条导致“/”被识别成了数字7。问题的根源找到了,解决起来就简单了,先将截图转换成灰度模式,然后用两层for循环将取每个像素点的灰度值,将大于240的灰度值改成255。改完之后再进行图像识别,搞定!
文字识别
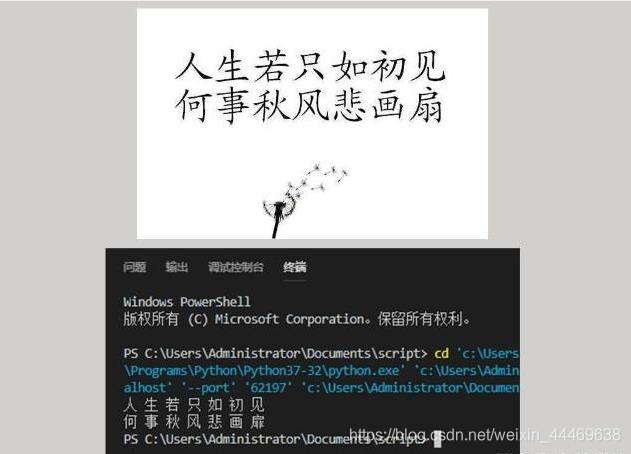
tesseract-ocr不仅能从图像中识别数字,还能识别文字(默认语言包为英文),在下载了中文语言包后识别中文也是6到不行。识别简体中文只需要添加一个参数lang:pytesseract.image_to_string(img,lang=‘chi_sim’)。下图上边是从网上找的一个图片,代码运行之后结果在下边。总共14个字,正确识别13个,其中“扇”被识别成了“扉”,这个识别结果并不能让人满意,试想如果是人手写的汉字,识别率恐怕会惨不忍睹。为了进一步提高识别率,还需要做很多工作,比如图像的灰度、模糊、去噪、二值化等等。
以上是一部分,更重要的是tesseract-ocr,能通过不断训练增强识别能力。
必须得有的福利
如果需要的话,可以随手转发之后,添加Python技术资料分享群123345949,就可以免费领取的,都是很基础很实用的Python资源。
推荐阅读:
https://blog.csdn.net/weixin_44469638/article/details/88727217
哈佛大学Python老师,推荐五本Python入门的书籍,附赠相应电子版