逻辑回归
之前写过逻辑回归,是sklearn的方法,基本一样
https://blog.csdn.net/weixin_44510615/article/details/88608831
补充一个概念:
交叉商损失函数
交叉商是实际输出概率于期望输出概率的距离,也就是交叉商的值越小,两个概率分布就越接近。
假设概率分布p为期望输出,概率分布q是实际输出,H(p,q)为交叉商,则:
H(p,q)=−∑p(x)logq(x)
l2是均方差损失函数
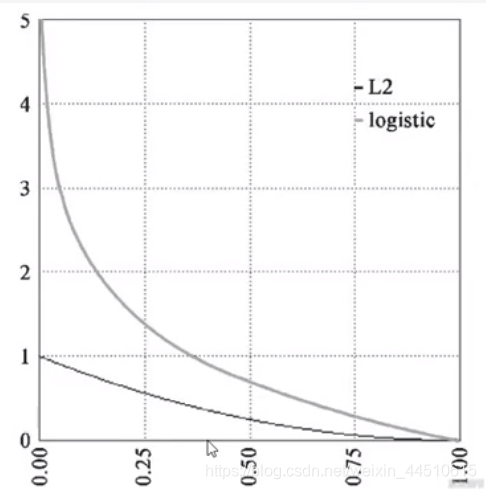
在keras交叉熵中,我们使用binary_crossentropy来计算二元交叉熵
对数几率回归解决的是二分类问题,对于多分类问题我们可以使用softmax分类函数,它是对数几率在N个可能不同的值上的推广
softmax分类
神经网络的原始输出不是一个概率值没实际上知识输入的数值做了复杂的加权和与非线性处理智慧的一个值而已,那么如何将这个输出变为概率分布呢
这就是 softmax层的作用

- softmax个样本分量之和为1
- 当只用两个分类是,于对数几率回归完全相同
在keras里,对于多分类问题我们使用categorical_crossentropy和
sparse_categorical_crossentropy来计算softmax交叉熵
实战
泰坦尼克数据集
介绍:
RMS泰坦尼克号的沉没是历史上最臭名昭着的沉船之一。1912年4月15日,在首次航行期间,泰坦尼克号撞上冰山后沉没,2224名乘客和机组人员中有1502人遇难。这场轰动的悲剧震撼了国际社会,并导致了更好的船舶安全条例。

用上面特征来判断是非获救
数据预处理
import pandas as pd
import numpy as np
import keras
data = pd.read_csv('train.csv')
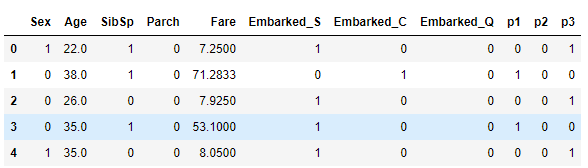
print(data.head())

用Survived作为y,x为[‘Pclass’, ‘Sex’, ‘Age’, ‘SibSp #是否姐妹兄弟陪行’, ‘Parch是否父母陪行’, ‘Fare’, ‘Embarked’}因为name和Cabin 船舱编码有太多缺失值
data.info()
OUT:
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 891 entries, 0 to 890
Data columns (total 12 columns):
PassengerId 891 non-null int64
Survived 891 non-null int64
Pclass 891 non-null int64
Name 891 non-null object
Sex 891 non-null object
Age 714 non-null float64
SibSp 891 non-null int64
Parch 891 non-null int64
Ticket 891 non-null object
Fare 891 non-null float64
Cabin 204 non-null object
Embarked 889 non-null object
dtypes: float64(2), int64(5), object(5)
memory usage: 83.6+ KB
x,y赋值,看下x中Embarked(船舱位置)中的唯一值
y = data.Survived
x = data[['Pclass', 'Sex', 'Age', 'SibSp', 'Parch', 'Fare', 'Embarked']]
print(x.Embarked.unique())
OUT:
['S' 'C' 'Q' nan]
为什么要特别要注意Embarked(船舱位置),因为不是数值
独热编码就来解决问题
['S' 'C' 'Q' nan]我用[0,0,1]来表示’Q’
解决方法
x['Embarked_S'] = (x.Embarked == 'S').astype('int')
# 这次用loc方法,我觉得还是上面的好点
x.loc[:, 'Embarked_C'] = (x.Embarked == 'C').astype('int')
x.loc[:, 'Embarked_Q'] = (x.Embarked == 'Q').astype('int')
#删掉Embarked这一行
x.drop(['Embarked'],axis =1,inplace=True )
还有性别
# 男为1 ,女为0
x['Sex'] = (x.Sex == 'male').astype('int')
在看下x.info(),发现age有缺失值
x.info()
OUT:
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 891 entries, 0 to 890
Data columns (total 9 columns):
Pclass 891 non-null int64
Sex 891 non-null int32
Age 714 non-null float64
SibSp 891 non-null int64
Parch 891 non-null int64
Fare 891 non-null float64
Embarked_S 891 non-null int32
Embarked_C 891 non-null int32
Embarked_Q 891 non-null int32
dtypes: float64(2), int32(4), int64(3)
memory usage: 48.8 KB
```那么用平均值来代替
x[‘Age’] = x.Age.fillna(x.Age.mean())
还有个票级的处理,因为Pclass是序列值
x['p1'] = (x.Pclass == 1).astype('int')
x['p2'] = (x.Pclass == 2).astype('int')
x['p3'] = (x.Pclass == 3).astype('int')
x.drop(['Pclass'],axis =1,inplace=True )
模型训练
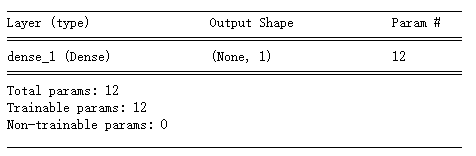
model = keras.Sequential()
from keras import layers
model.add(layers.Dense(1, input_dim=11, activation='sigmoid')) #y_pre = (w1*x1 + w2*x2 + ... + w11*x11 + b)
model.summary()
model.compile(optimizer='adam',
loss='binary_crossentropy', # 二分类问题 用`binary_crossentropy` 可以看下上面
metrics=['acc']) # metrics方法我们可以在训练的时候看到准确率acc
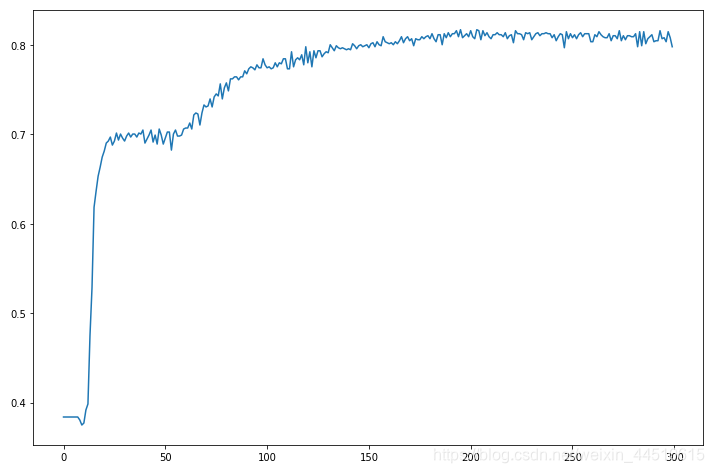
history = model.fit(x, y, epochs=300)
history.history.keys()
OUT:
dict_keys(['loss', 'acc'])

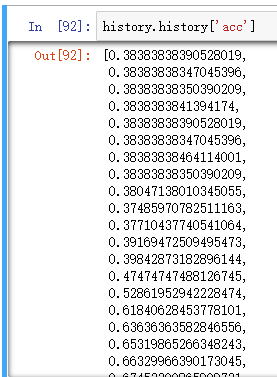
这次画下图
import matplotlib.pyplot as plt
%matplotlib inline
plt.plot(range(300), history.history.get('loss'))
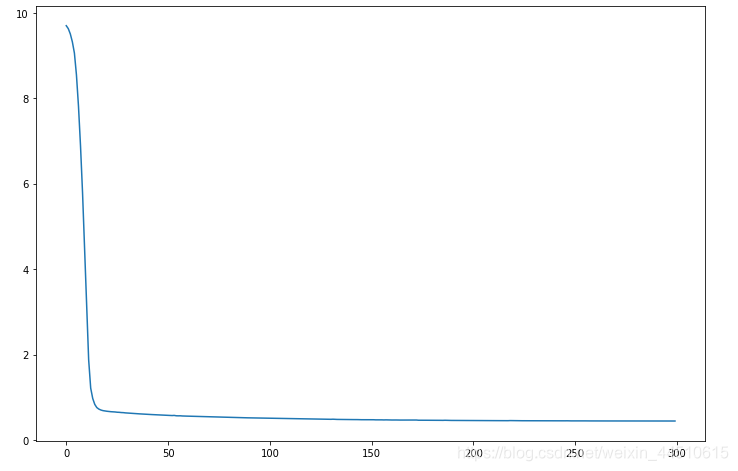
plt.plot(range(300), history.history.get('acc'))