上次讲了二分类的实例,今天来探究多分类的问题
实战
iris数据集的介绍
iris数据集是常用的分类实验数据集,由Fisher, 1936收集整理。Iris也称鸢尾花卉数据集,是一类多重变量分析的数据集。数据集包含150个数据集,分为3类,每类50个数据,每个数据包含4个属性。可通过花萼长度,花萼宽度,花瓣长度,花瓣宽度4个属性预测鸢尾花卉属于(Setosa,Versicolour,Virginica)三个种类中的哪一类。
这里有个iris.csv 文件
读取文件
import keras
from keras import layers
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
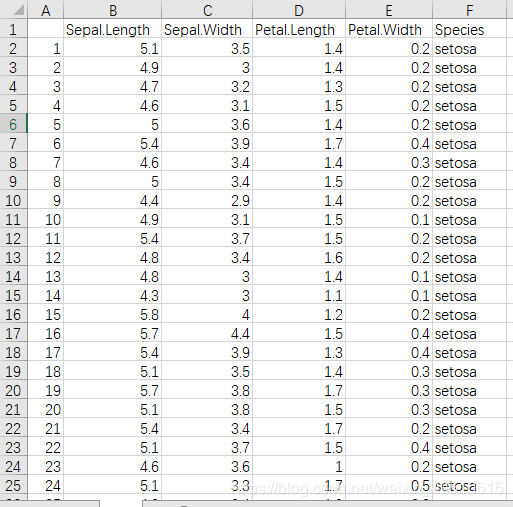
data = pd.read_csv('../dataset/iris.csv')
data.head()
data.info()
OUT:
Unnamed: 0 Sepal.Length Sepal.Width Petal.Length Petal.Width Species
0 1 5.1 3.5 1.4 0.2 setosa
1 2 4.9 3.0 1.4 0.2 setosa
2 3 4.7 3.2 1.3 0.2 setosa
3 4 4.6 3.1 1.5 0.2 setosa
4 5 5.0 3.6 1.4 0.2 setosa
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 150 entries, 0 to 149
Data columns (total 6 columns):
Unnamed: 0 150 non-null int64
Sepal.Length 150 non-null float64
Sepal.Width 150 non-null float64
Petal.Length 150 non-null float64
Petal.Width 150 non-null float64
Species 150 non-null object
dtypes: float64(4), int64(1), object(1)
memory usage: 7.1+ KB
数据预处理
数据没有缺失值,但是要处理种类,因为是文本数据
data.Species.unique()
OUT:
array(['setosa', 'versicolor', 'virginica'], dtype=object)
——————————
# 上次独热编码很复杂,这次用高级的方法
data = data.join(pd.get_dummies(data.Species))
# get_dumnies直接将创建三列['setosa', 'versicolor', 'virginica']
data.drop(['Species'],axis=1,inplace=True)
print(data.head())
x和y 赋值
x = data.iloc[:,1:-3]
y = data.iloc[:,-3:]
在搞乱顺序
index = np.random.permutation(len(data))
data = data.iloc[index]
训练模型
model = keras.Sequential()
model.add(layers.Dense(3, input_dim=4, activation='softmax'))
这里出现小插曲:
TypeError: softmax() got an unexpected keyword argument ‘axis’ 解决办法:
将tensorflow_backend.py中第3149行中axis=axis改成dim=axis即可解决问题。原因:安装的keras库可能跟TensorFlow库不兼容,还可以回退keras 版本pip install keras==2.1
model.compile(optimizer='adam',
loss='categorical_crossentropy',
metrics=['acc']
)
# 目标数据做度热编码,用 categorical_crossentropy 来计算softmax交叉熵
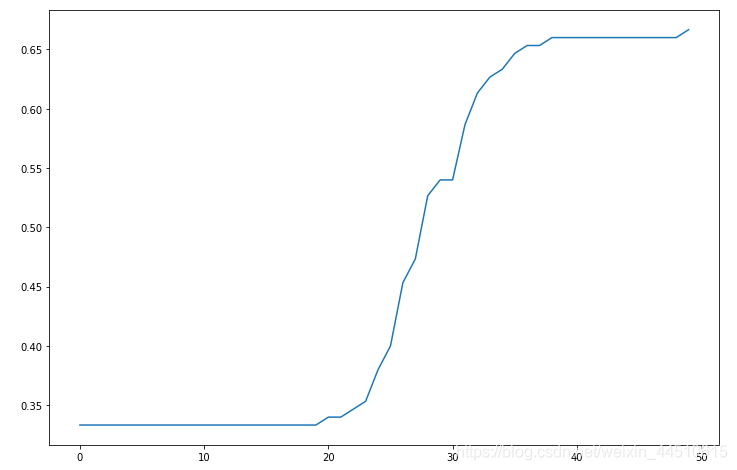
history = model.fit(x, y, epochs=50)
plt.plot(range(50), history.history.get('loss'))
plt.plot(range(50), history.history.get('acc'))
loss
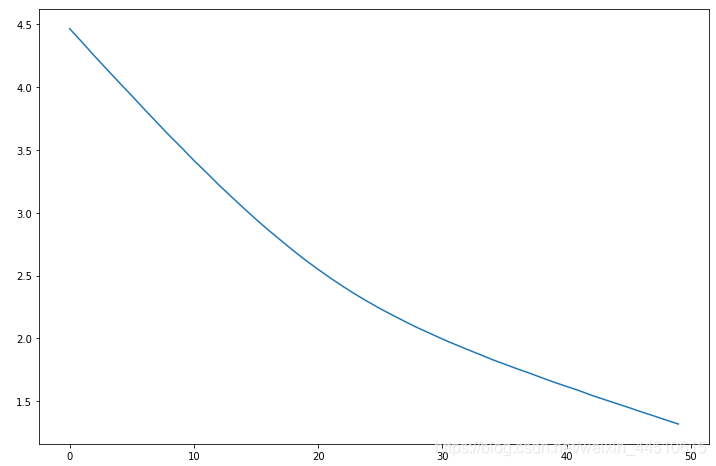
acc