前言
对于一张网页,我们往往希望它是结构良好,内容清晰的,这样搜索引擎才能准确地认知它。
而反过来,又有一些情景,我们不希望内容能被轻易获取,比方说电商网站的交易额,教育网站的题目等。因为这些内容,往往是一个产品的生命线,必须做到有效地保护。这就是爬虫与反爬虫这一话题的由来。
但是世界上没有一个网站,能做到完美地反爬虫。如果页面希望能在用户面前正常展示,同时又不给爬虫机会,就必须要做到识别真人与机器人。因此工程师们做了各种尝试,这些策略大多采用于后端,也是目前比较常规但有效的手段,比如:
后端与反爬虫
1、User-Agent
2、账号及Cookie验证
3、验证码
4、IP限制频率
前端与反爬虫
1、FONT-FACE拼凑式
实例:猫眼电影
猫眼电影里,对于票房数据,展示的并不是纯粹的数字。页面使用了font-face定义了字符集,并通过Unicode取映射展示。也就是说,除去图像识别,必须同时爬取字符集才能识别出数字。

扫描二维码关注公众号,回复:
5637987 查看本文章

2、元素定位覆盖式
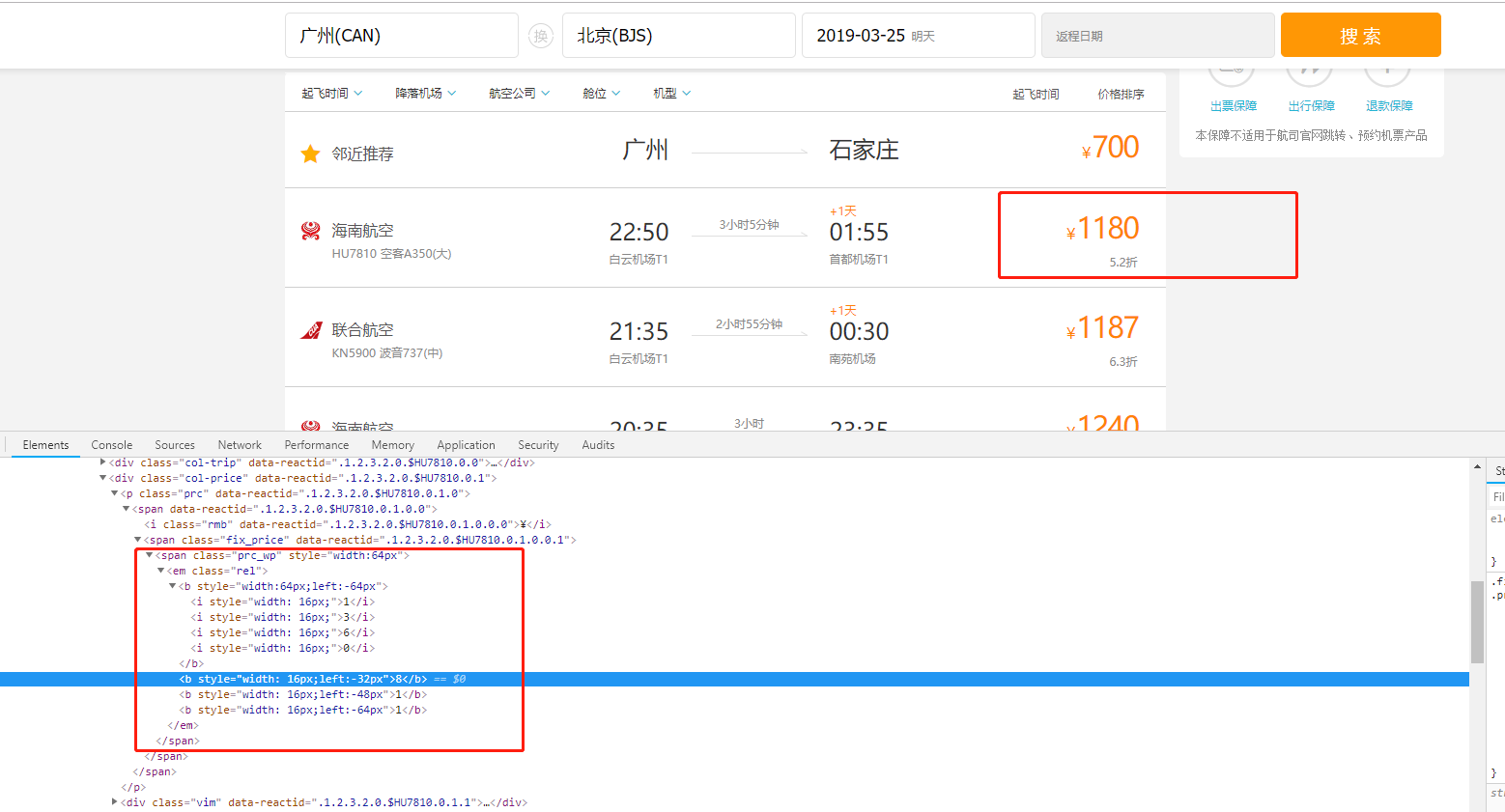
实例:去哪网
对于一个4位数字的机票价格,先用四个i标签渲染,再用b标签取绝对定位偏移量,覆盖展示错误的i标签,形成视觉上正确的价格。
3、字符分割式
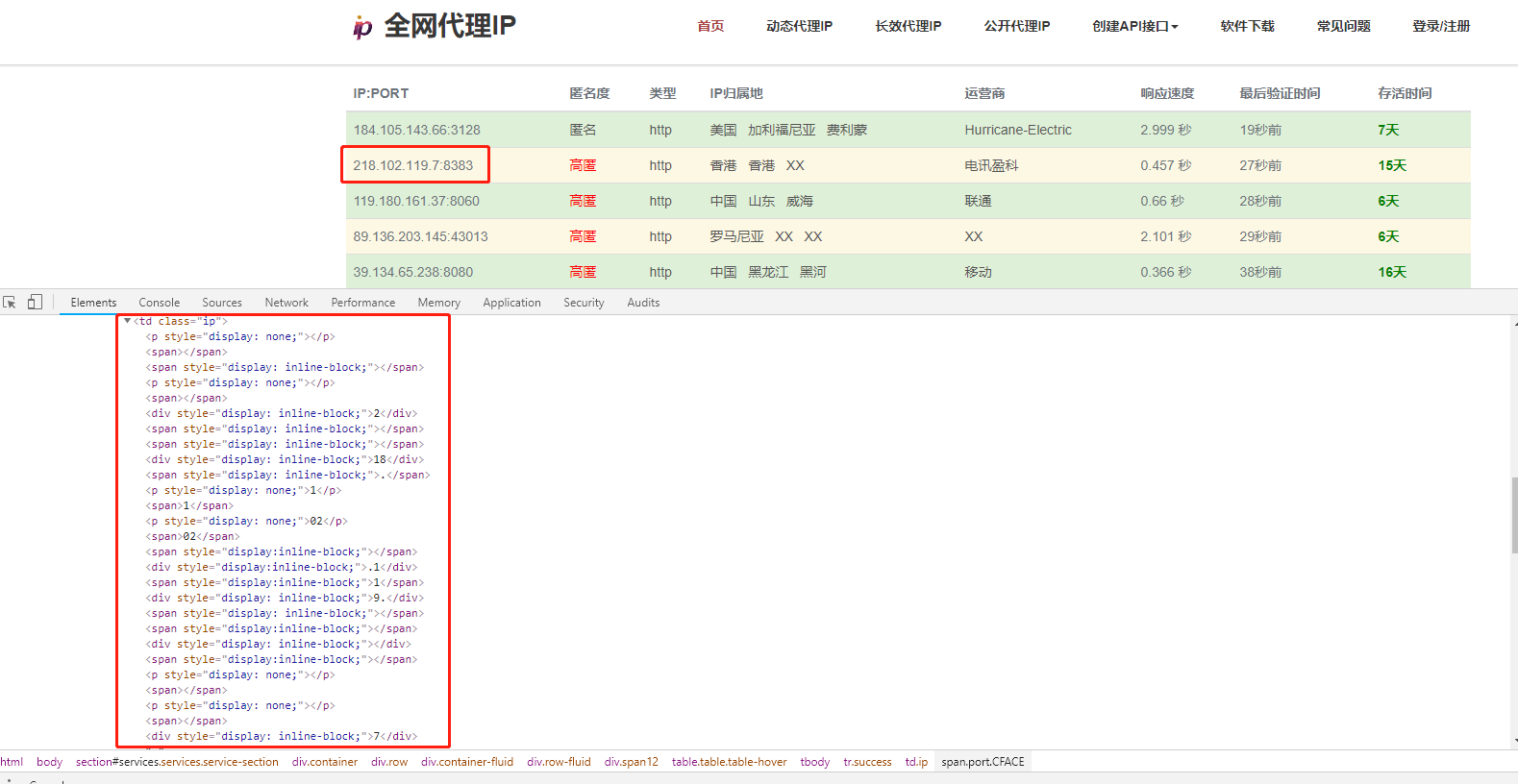
实例:全网代理IP
在展示代理IP信息的页面
4、字符穿插式
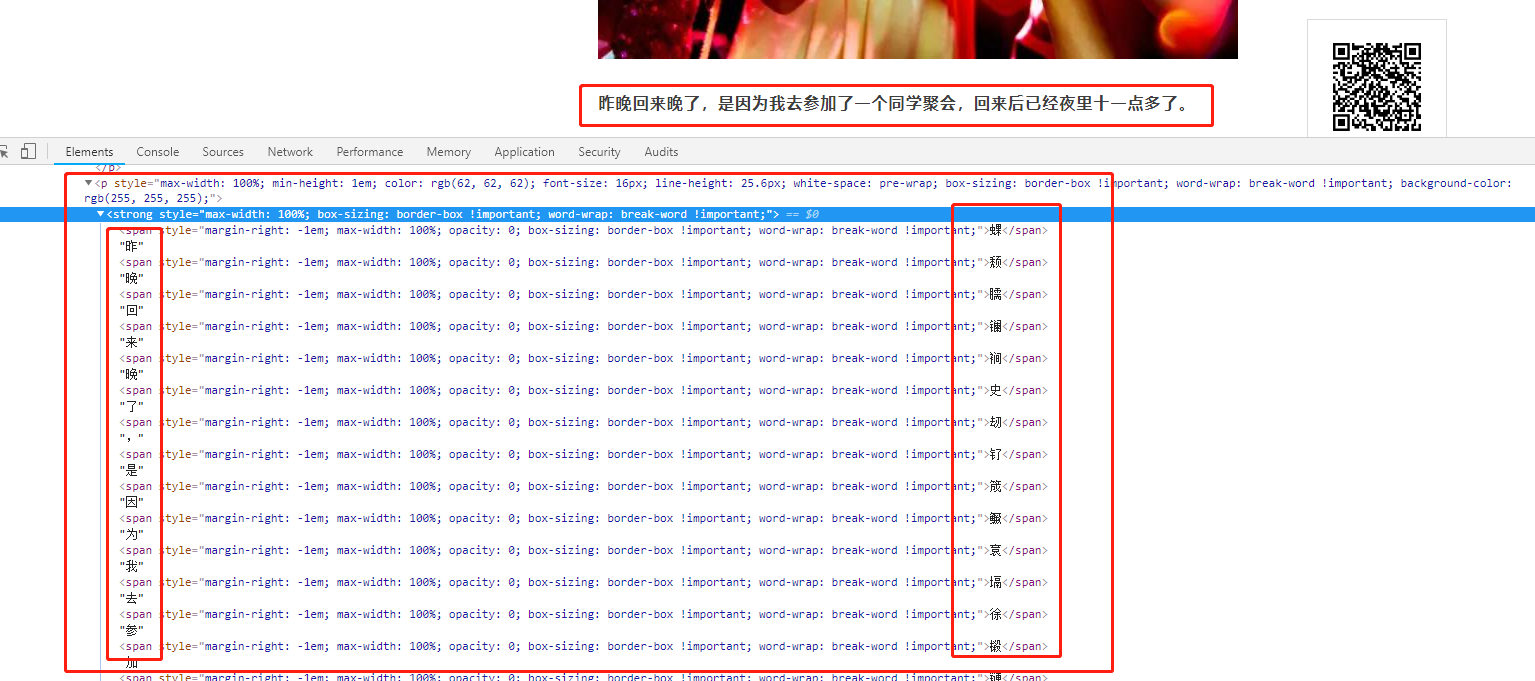
实例:微信公众号文章
在某些微信公众号的文章里,穿插了各种谜之字符,通过样式把这些字符隐藏掉。
5、background拼凑式
展示的数字其实是图片,根据不同的background偏移,展示出不同的字符
6、伪元素隐藏式
把关键的信息放到伪元素的content里面。爬取网页时必须得解析css拿到伪元素的content。
7、字符集替换式
HTML代码里明明写的是3211,视觉上展示的却是1233,重新定义字符集,将3和1 的顺序调换。