前言
我们紧接着上节ArrayList 线程安全问题讲下HashMap的线程安全问题.
之前看书,书中经常会提及.HashTable是线程安全的,HashMap是线程非安全的.在多线程的情况下, HashMap会出现死循环的情况.此外,还会推荐使用新的JUC类 ConcurrentHashMap.
今天,我们就将这些幺蛾子一网打尽. 本章, 将主要描述"为什么HashMap是非线程安全的? HashMap在多线程的情况下为什么会出现死循环?"
正文 - 准备工作
在讲解HashMap类的非线程安全问题之前, 我们需要对于HashMap的数据结构要有所了解.
通过Eclipse的outline视图,我们瞄一瞄HashMap的源码内的对象.
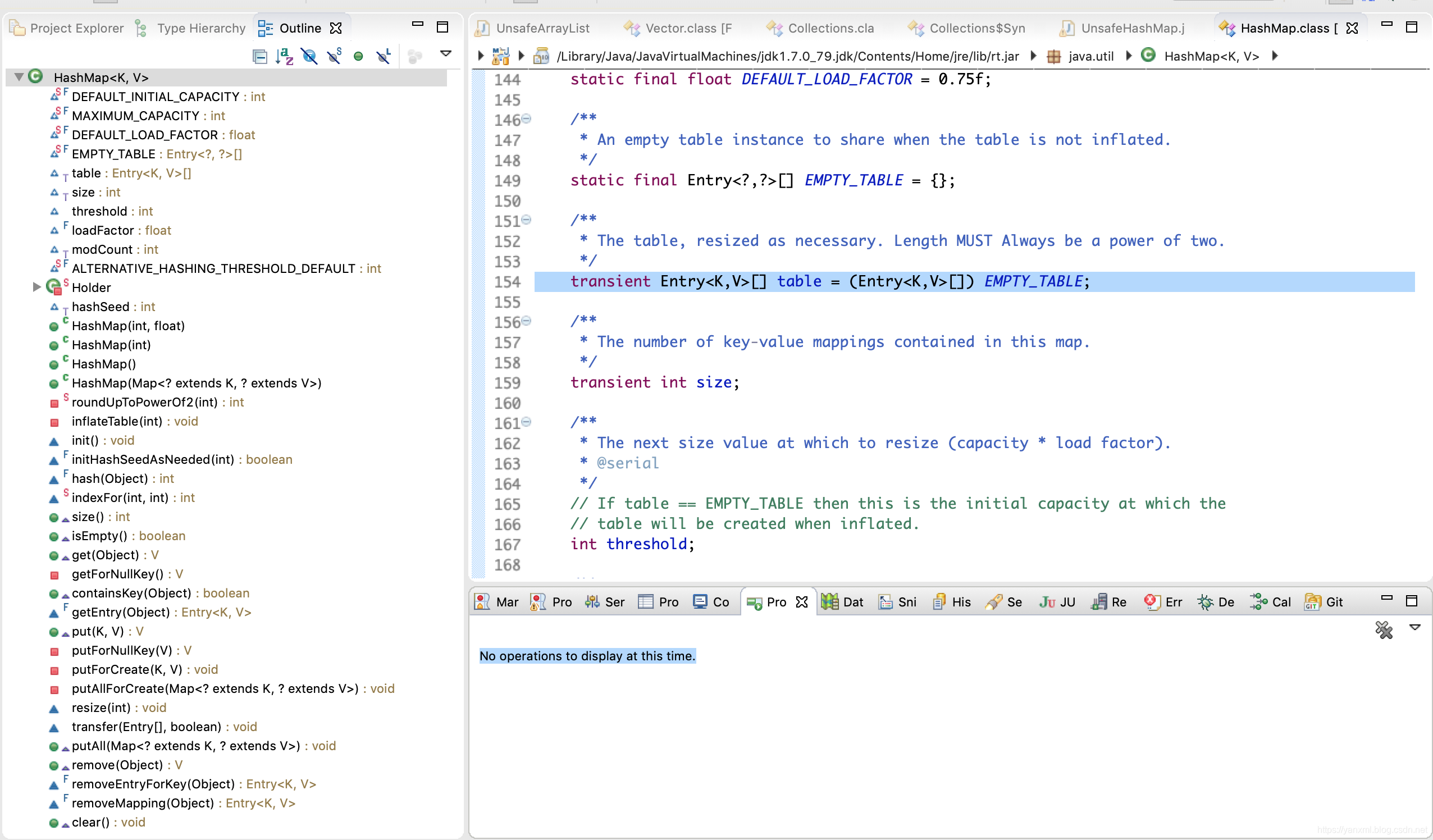
通过观察,我们可以发现.HashMap主要是维护了一个Enrty类型的数组来存储变量.
即transient Entry<K,V>[] table = (Entry<K,V>[]) EMPTY_TABLE;,其中transient是用于表示不需要序列化的标示,我们不用管他.
static class Entry<K,V> implements Map.Entry<K,V> {
final K key;
V value;
Entry<K,V> next;
int hash;
}
我们在看下Entry类的源码.通过上述的Entry源码,我们可以发现它主要包括几个部分:key/value/hash/next.
在JDK1.7中的HashMap结构大致如下:
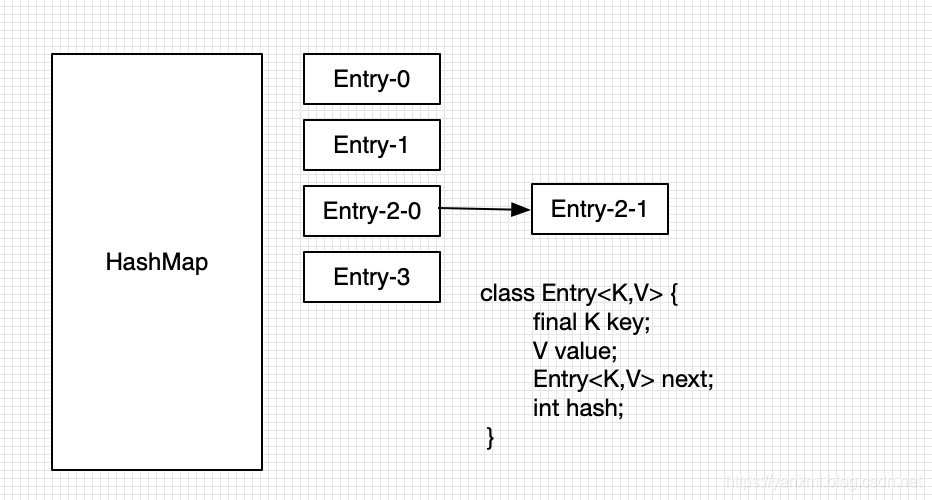
其中的每一块值,是一个Entry类型的链表.(在JDK1.8 之后,当Entry链表的长度多于一定的值的时候,会将其转换为红黑树. PS: 为了在O(log2N)的时间内获取到结点的值. 在JDK1.8内的红黑树也是使用链表进行实现的,不必过于在意.)
单线程resize操作
首先, 与ArrayList类一样, 我们先瞄一瞄HashMap的put方法.
public V put(K key, V value) {
if (table == EMPTY_TABLE) {
// 如果table为空的table,我们需要对其进行初始化操作.
inflateTable(threshold);
}
if (key == null)
// 如果key为null的话 我们对其进行特殊操作(其实是放在table[0])
return putForNullKey(value);
// 计算hash值
int hash = hash(key);
// 根据hash值获取其在table数组内的位置.
int i = indexFor(hash, table.length);
// 遍历循环链表(结构图类似上图)
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
// 如果找到其值的话,将原来的值进行覆盖(满足Map数据类型的特性.)
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
// 如果都没有找到相同都key的值, 那么这个值是一个新值.(直接进行插入操作.)
modCount++;
addEntry(hash, key, value, i);
return null;
}
跟随其后,我们深入addEntry(hash, key, value, i);方法一探究竟吧.
void addEntry(int hash, K key, V value, int bucketIndex) {
if ((size >= threshold) && (null != table[bucketIndex])) {
// 如果其大小超过threshold 并且table[index]的位置不为空
// 扩充HashMap的数据结果为原来的两倍
resize(2 * table.length);
hash = (null != key) ? hash(key) : 0;
bucketIndex = indexFor(hash, table.length);
}
createEntry(hash, key, value, bucketIndex);
}
PS: mountCount/size/threshold的联系与区别?
紧随其后,进入人们经常说的resize()方法.
void resize(int newCapacity) {
Entry[] oldTable = table;
int oldCapacity = oldTable.length;
if (oldCapacity == MAXIMUM_CAPACITY) {
//capacity 容量
threshold = Integer.MAX_VALUE;
return;
}
// 创建一个新的对象
Entry[] newTable = new Entry[newCapacity];
// 将旧的对象内的值赋值到新的对象中
transfer(newTable, initHashSeedAsNeeded(newCapacity));
table = newTable;
// 重新赋值新的临界点
threshold = (int)Math.min(newCapacity * loadFactor, MAXIMUM_CAPACITY + 1);
}
void transfer(Entry[] newTable, boolean rehash) {
// 新table的长度
int newCapacity = newTable.length;
for (Entry<K,V> e : table) {
while(null != e) {
Entry<K,V> next = e.next;
if (rehash) {
e.hash = null == e.key ? 0 : hash(e.key);
}
int i = indexFor(e.hash, newCapacity);
e.next = newTable[i];
newTable[i] = e;
e = next;
}
}
}
这么一看,主要的resize()方法的转换操作都在transfer()方法内.我们详细的画图了解下这个循环.
for (Entry<K,V> e : table) {}外层循环,循环遍历旧table的每一个值.这不难理解,因为要将旧table内的值拷贝进新table.- 链表拷贝操作.主要是四行代码.
e.next = newTable[i]; newTable[i] = e; e = next;这个操作一下子比较难懂,我们画图了解一下.
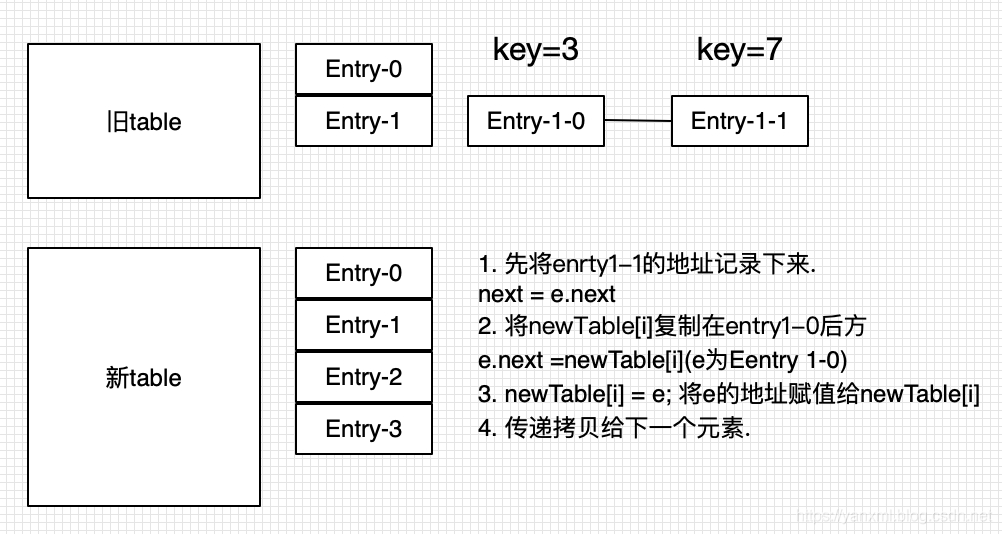
这个图还是有点抽象 我们再将细节进行细分.

1 next = e.next,目的是记录下原始的e.next的地址.图上为Entry-1-1.
2 e.next = newTable[i],也就是将newTable[3]替代了原来的entry1-1.目的是为了记录原来的newTable[3]的链表头.
3 newTable[i] = e,也就死将entry1-0替换成新的链表头.
4. e = next;,循环遍历指针.将e = entry1-1.开始处理entry1-1.
将步骤细分后,我们可以得到如下:

由上述的插入过程,我们可以看出.这是一个倒叙的链表插入过程.
(比如 1-0 -> 1-1 ->1-2 插入后将变为 1-2 -> 1-1 -> 1-0)
多线程操作 - 分析线程安全?线程非安全?
因为倒叙链表插入的情况,导致HashMap在resize()的情况下,导致链表出现环的出现.一旦出现了环那么在while(null != p.next){}的循环的时候.就会出现死循环导致线程阻塞.那么,多线程的时候,为什么会出现环状呢?让我们看下面的例子:
首先有2个线程,由上一节我们知道,在resize()的过程中,一共有如下四个步骤:
Entry<K,V> next = e.next;e.next = newTable[i];newTable[i] = e;e = next;
我们有两个线程,线程A与线程B.线程A在执行Entry<K,V> next = e.next;之后,也就是第一个步骤之后,线程阻塞停止了.线程B之间进行了重排序的操作.此时的HashMap内部情况如下所示:
- 初始(A阻塞 B运行完毕)
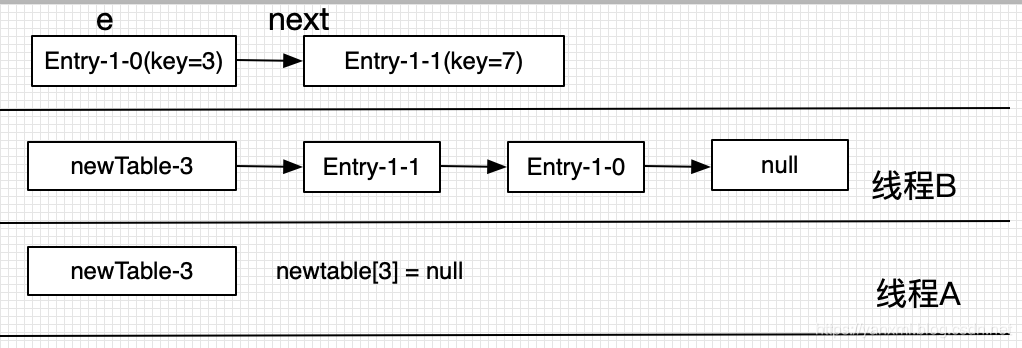
- A唤醒 e=key(3)
A的执行步骤如下:- 线程阻塞前记录 next = key(7)
- 线程唤醒后执行 newTable[3]=null; key(3).next=null;
- newTable[3]=key(3);
- e=next; 即 e = key(7);
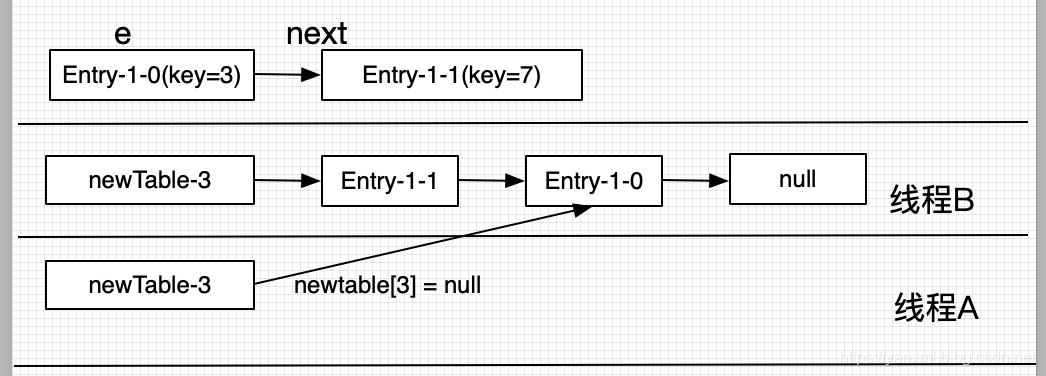
- A唤醒 e=key(7)
- next = key(3)
- newTable[3]=key(3); key(7).next=key(3);
- newTable[3]=key(7);
- e=next; 即 e = key(3);
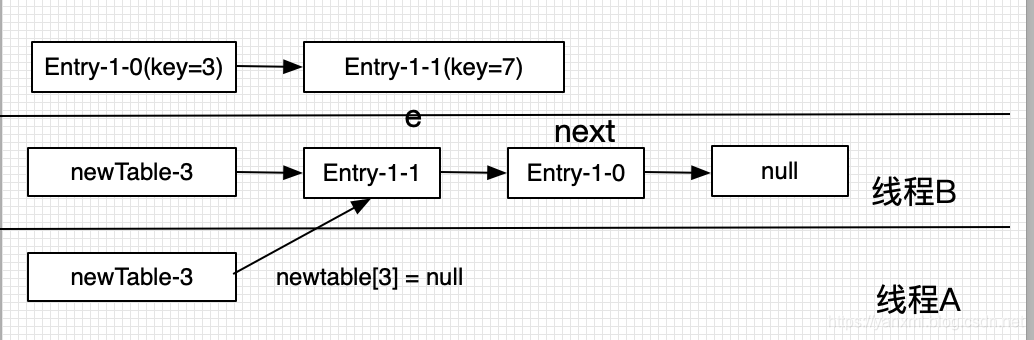
- A唤醒 e=key(3)
- next = key(3).next; 即 next = null;
- newTable[3]=key(7); key(3).next=key(7);
- newTable[3]=key(3);
- e=next; 即 e = null; 循环结束.但是此时已经形成了环路.
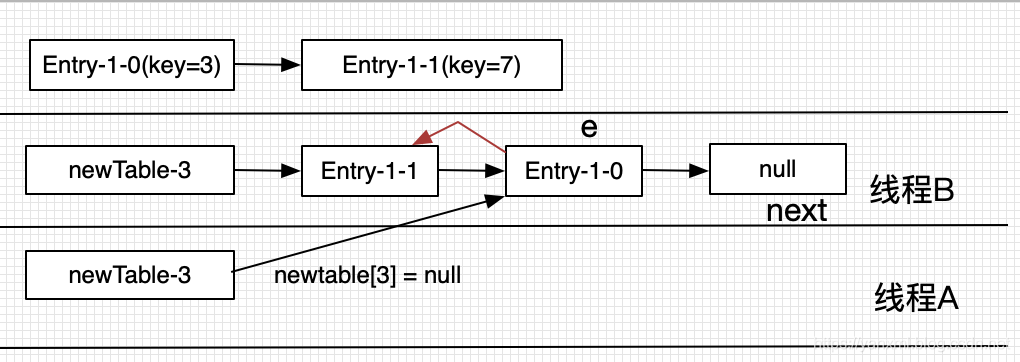
Tips
链表出现环?
快,慢指针方法.判断链表中是否有环 ----- 有关单链表中环的问题
size、capacity、threshold与loadFactor?
- size为hashMap内的链表结点数目.即
Entry对象的个数(包括链表内).- capacity为桶的数目.(即Enrty<k,v> []table的长度)
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16- loadFactor 过载因子
static final float DEFAULT_LOAD_FACTOR = 0.75f;- threshold 边界值.高于边界值,则HashMap进行
resize操作.The next size value at which to resize (capacity * load factor).定义int threshold;
Reference
[1]. HashMap 在 JDK 1.8 后新增的红黑树结构
[2]. (1)美团面试题:Hashmap的结构,1.7和1.8有哪些区别,史上最深入的分析
[3]. Java7/8 中的 HashMap 和 ConcurrentHashMap 全解析
[4]. HashMap?面试?我是谁?我在哪
[5]. JDK7与JDK8中HashMap的实现
[6]. 谈谈HashMap线程不安全的体现
[7]. ConcurrentHashMap源码分析(JDK1.7和JDK1.8)
[8]. HashMap中capacity、loadFactor、threshold、size等概念的解释