前言
大家好,这里是BASE上海、从事消费金融数据风控的小强,转岗数据监控的半年里,一直在补足可视化、推断统计、机器学习这方面的知识。最新由于实际的业务需求,又开始学习并成功部署了爬虫,因此特地想跟大家分享一下整个一个流程跟我的学习办法。
项目背景:公司把客户流量导买给三方机构,业务先行完成,数据返回的接口尚未开发完毕,而领导层需要数据报表支持。因此,由数据分析师通过三方机构的CRM系统导出数据进行操作,但是CRM查询速度慢,且导出数据量存在限制,需要分段导出,给数据分析师的日常工作添加了极大的负担。
项目目标:通过python爬虫实现访问CRM—提交账号密码模拟登陆—抛出查询请求,解析json数据—本地留存—报表制作。
学习过程
什么是爬虫?通俗的来讲,爬虫就是利用计算机的执行效率模拟人工浏览器操作获取互联网数据。既然是模拟人工浏览器去获取数据,那势必先理清楚浏览器是怎么访问互联网获取数据的。
以豆瓣网(https://www.douban.com/)为例,大家都知道https://www.douban.com/是豆瓣的域名,但前面的https是什么意思呢,其实是一种协议,可以理解为大家相互约定说话的方式,比如我说“江浙沪白完”,那你肯定知道这个词专门指向的内容,这就是一种约定。以chrome浏览器为例,浏览器是客户端,豆瓣网是服务端,那么在打开豆瓣网的这个过程其实就是一次请求豆瓣把门打开给我看看你们家有啥宝贝,那么为了让豆瓣开门,我就向豆瓣提供了一个请求文(request),其中包括了
请求行(request line 必须)== 请问这里是豆瓣嘛?
请求头(request headers 必须) == 我是XXX啊!
请求体(message body 可选) == 我是来看宝贝的


上图就是我去豆瓣的一次“敲门”(基于fiddler工具抓包)
第一行就是基于http/1.1协议使用了get方式去敲了https://www.douban.com/这户人家的门。
第二行直到底就是我这次的请求头,咱们一行一行来读,HOST主机地址,类似门牌号,防止走错了; CONNECTION链接方式,keep-alive告诉豆瓣你别回了一次就不理我了,我还有事找你呢; UPGRADE-INSECURE-REQUESTS协议升级,1说明从http升级为https,类似于你别整天从我家后门进出,不管事,走正门安全着呢。顺便一提,https跟http对于爬虫基本没有影响,主要区别点在于能让我访问对的网站,防止钓鱼网站诈骗; USER-AGENT使用类型,显示的我是使用chrome浏览器去访问的,主要用来确认访问的方式,如果把chrome、Firefox这些认为是花式按门铃访问,那么python、java这些爬虫就是拿着大榔头使劲砸门了; ACCEPT接受类型,告诉服务端我们客户端这些可以看那种数据格式; REFERER访问来源,用来告诉服务端我们是从哪里知道你们家的地址的,上图就是告知从百度检索跳转的;ACCEPT-ENCODING/LANGUAGE 接受压缩语言类型,基本上都是跟上图一样可压缩数据、使用中文。
细心的同学可能会发现还有一个请求体呢,诶,这个东西是可选的,我们通常在用post方式请求时,使用请求体携带一些数据交给服务端。
那么在我敲了豆瓣的门之后,肯定需要豆瓣回应我,甚至给我开门的,咱们来看看豆瓣咋回应我的吧。
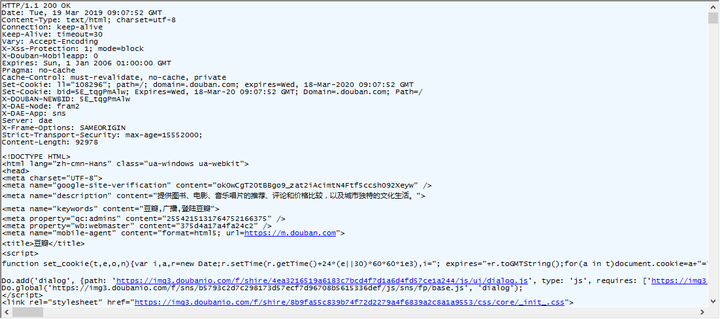
有些同学是不是发现有些眼熟呢,没错,服务端回应客户端的格式没有变,也是回应行(response line)、回应头(response headers)、回应体(response message body)。其中比较重要的内容有如下:
回应行中在http/1.1这个协议之后的百位数,这个是指服务端响应的状态,200意为成功访问,其他释义请百度百科“http状态码”;
回应头中的Set-Cookie,作用是提供一个标准格式数据让我组合成一个标准的临时身份证明,有了这个证明之后,我在一定时间内访问时可以被服务端识别出来,在keep-alive时就不用因为认不出是之前来过的人而出现访问异常。
说完了http协议的双方交互方式内容之后,接下来就要提下在实际写爬虫的过程中最重要的东西,即对网页的分析解读。
网页分析
以小强公司合作的三方机构CRM为例,点击网址访问后跳转到登录页面,打开chrome开发者工具,选择NETWORK选项,并刷新页面,发现主文件HTML文档(http://XXXX.XXXX.com)及若干JS文件、IMG图片、CSS文件,其中JS文件用于实现登录页面的渲染、提交数据、加载动态验证码等功能,IMG用于填充LOGO、跳转等UI设计,CSS文件配合HTML组合前二者文件加强网页渲染效果。因爬虫专注于获取服务端数据,故只需通过HTML文档实现访问登录页即可。回到正文,点击开发者工具里面的HTML文档,右边出现HEADERS、 PREVIEW、 RESPONSE、 COOKIES、 TIMING选项,先点击HEADERS,有GENERAL、 RESPONSE HEADERS、 REQUEST HEADERS三类。GENNERAL中需要关注URL作为爬虫请求的地址,METHOD 中的GET说明使用get方法提交访问。Request Headers中的内容为之前介绍过的内容,只需把爬虫的请求文伪装成chrome的请求文即可。Response Headers中最重要的一条即Set-Cookie:acw_tc=fw12312tfwe12451325tefdsAYH464; path=/; HttpOnly; max_age=2678401。前面提到过cookies是种客户端的临时身份证明,而服务端在第一次被访问无法识别对方身份的情况下抛出了Set-Cookie,说明服务端在告诉我们需要用它返回的Set-Cookie按标准制作一张Cookie,并在后续的访问中提供给服务端做身份识别。
再次顺着登录页面填写了账号、密码、验证码,提交之后登陆成功跳转到CRM首页,同时NETWORK中新增了巨多文件,那么怎么识别本次操作需要关注的主文件呢,很简单,只需要对新增的每个文件点击,查看右边的Response栏目下的内容。最终确定了password这个XHR文件,其响应了登录账号名、账号名称、账号当前状态、登录结果。那么确定需要关注的主文件之后,点击Headers栏目,发现这次多出来一个Request Payload, 点开发现是一个JSON数据,里面赫然保存着我们登录时的用户名与密码,再查看General,Method方法果然是之前我们提到的POST方式,说明爬虫在模拟登录的时候需要模拟浏览器使用POST抛出请求,并且在请求报文中在请求体栏中带上我们的用户名、密码实现模拟登录。
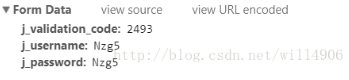
Bingo!那么一定有细心的同学会发现,我们浏览器在登录的时候明明还输入了反爬虫的验证码啊?没错,通常意义上,如果网页登录有验证码反爬虫措施时需要在post的请求体中带上输入验证码、账号、密码三个数据。如下图所示
并且在开发者工具里的Elements栏目里,可以找到对应验证码的URL。对于这种登录方式,我们可以建立一个合并请求(专业名称叫Session),先请求验证码获取图片,解析后本地保存并在屏幕上打印出来,人工或者机器学习识别后输入正确答案并连同账号密码做成json数据提交给登录URL。回归主题,password这个文件里面并没有提交验证码数据?那么同时去Elements里面去找找问题,发现对于控制验证码的区块并没有URL,这下子连小强都蒙了,怎么办?遇事不决问百度,终于找到一个说法,理论上如果有cookie+账号密码可以实现无需验证码登录,当然这种说法靠不靠谱另说,之后咱么代码实践出真知。再来看password里面的Request Headers,发现新增了很多条,除了Cookie以外的条目我们可以利用之前建立的Headers字典增删改即可,而这里出现的Cookie即为按照之前服务端给的数据制作而成,制作的方法咱们后面再提。再看看Response Headers,发现一大堆我们看不懂的条目,没关系看不懂咱们就跳过。
接下来进入最后一步,CRM上的查询功能,点击上面的查询开始结束日期,发现新增了一个很明显query的XHR文件,发现该文件里返回了需要查询的数据,那么整个爬虫环节到此为止了,只需要对其进行分析就完成了。
先看看Request Payload,发现带了一个嵌套的Json数据,最重要的内容是“createtimeFrom”和“createtimeTo”两个Key及其对应Value。
再看看Request Headers,怎么突然比登录时多了“Merchant-Portal-Token”条目,value是一堆类似Cookie的乱七八糟的数据,怎么肥事?不要怕,之前没有,这次突然新增了,那咱们回到上一次模拟登录时的Response Headers看看,果不其然发现了一个“Merchant-Portal-Token”,把两个key对应的value在python里面做成STR进行对比,返回True,那看来这个条目应该是类似于三方机构自己做的一个二次临时身份证明,用于在登录后的页面进行安全认证,只需要把Response的条目数据获取并添加到Request Headers就可以咯,嘻嘻嘻,我可真是个小天才呢。
看到这里,咱们就完成了整个访问主页—模拟登录—数据查询的流程分析了呢,确定下来主要针对http://xxxx.xxxxx.com,password,query三个文件的内容进行访问即可。那么整个伪代码如下:
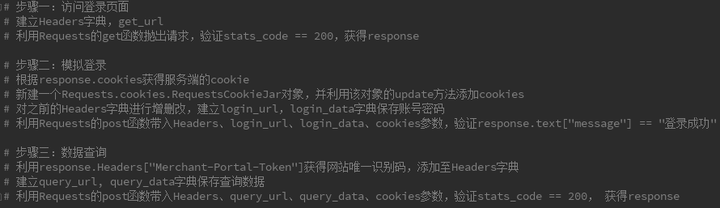
铛铛铛,怎么样,是不是感觉爬虫其实是个很简单的活呢。其中爬虫最难得是反反爬手段,最重要的是对网页的分析解读,获得爬虫需要的信息。长路漫漫,任重而道远,大家一起在python数据科学的路上前行吧哈哈哈哈哈!