版权声明:版权声明: 笔者博客文章主要用来作为学习笔记使用,内容大部分来自于自互联网,并加以归档整理或修改,以方便学习查询使用,只有少许原创,如有侵权,请联系博主删除! https://blog.csdn.net/qq_42642945/article/details/88637037
文件读取与存储
我们的数据大部分存在于文件当中,所以pandas会支持复杂的IO操作,pandas的API支持众多的文件格式,如CSV、SQL、XLS、JSON、HDF5。
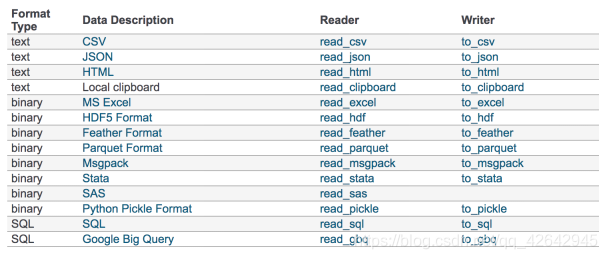
注:最常用的HDF5和CSV文件
文件读取与存储
-
CSV读取与存储
- pd.read_csv()
- usecols参数用于选择部分列,而不是全部
- pd.to_csv()
- columns用于选择需要写出的列
- header控制是否写出列的名字
- index控制是否写出行的名字
- pd.read_csv()
-
HDF5读取与存储
- HDF5是一种容器,一个HDF5文件中可以存放多份DataFrame/Series数据,不同的数据用不同的Key来区分。
- pd.read_hdf(),如果文件中只有一个key,则可以不指定
- pd.to_hdf(),必须得指定key
-
CSV与HDF5对比
- 写效率:HDF5高
- 读效率:HDF5高
- 占空间:HDF5少
-
如何获取HDF5文件中的key?
- store = pd.HDFStore(‘high.h5’)
- store.keys()
-
JSON读取与存储
- pd.read_json()
- orient:文件的结构,这里的参数的值必须与文件的结构相符
- index,以行为单位
- columns,以列为单位
- records,以记录为单位
不同的参数值只影响文件的结构,不影响实际的数据 - lines: 也要和文件的结构相符,之在orient='records’才有意义
-
pd.to_json()
CSV
读取csv文件-read_csv
- pandas.read_csv(filepath_or_buffer, sep =’,’ , delimiter = None)
- filepath_or_buffer:文件路径
- usecols:指定读取的列名,列表形式

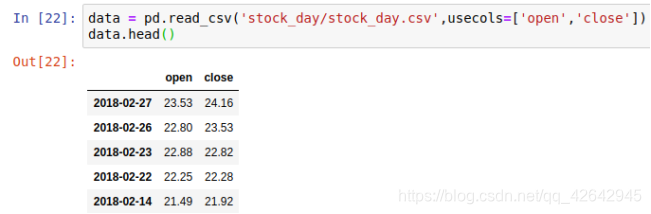
读取之前的股票的数据,并且指定只获取’open’, 'close’指标
import pandas as pd
# 读取文件,并且指定只获取'open', 'close'指标
data = pd.read_csv('./stock_day.csv',usecols = ['open','close'])
data.head()
写入csv文件-to_csv
- DataFrame.to_csv(path_or_buf=None, sep=’, ’, columns=None, header=True, index=True, index_label=None, mode=‘w’, encoding=None)
- path_or_buf :string or file handle, default None
- sep :character, default ‘,’
- columns :sequence, optional
- mode:‘w’:重写, ‘a’ 追加
- index:是否写进行索引
- header :boolean or list of string, default True,是否写进列索引值
- Series.to_csv(path=None, index=True, sep=’, ‘, na_rep=’’, float_format=None,header=False, index_label=None, mode=‘w’, encoding=None,compression=None, date_format=None, decimal=’.’)
Write Series to a comma-separated values (csv) file
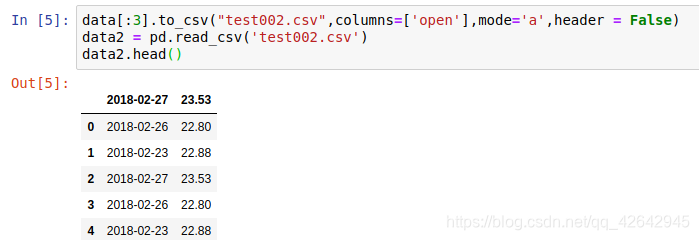
data[:3].to_csv("test002.csv",columns=['open'],mode='a',header = False)
data2 = pd.read_csv('test002.csv')
data2.head()
案例
- 保存’open’列的数据
# 选取10行数据保存,便于观察数据
data[:10].to_csv("./test.csv", columns=['open'])
data2 = pd.read_csv('test.csv')
data2.head()
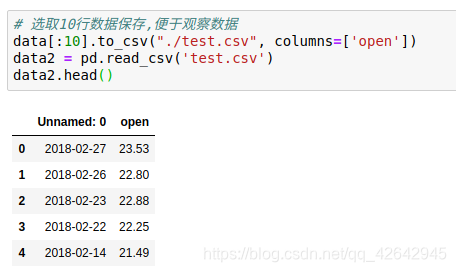
会发现将索引存入到文件当中,变成单独的一列数据。如果需要删除,可以指定index参数,删除原来的文件,重新保存一次。
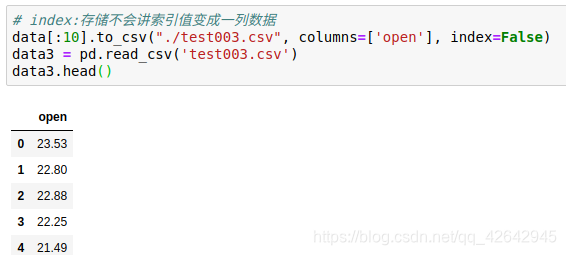
# index:存储不会讲索引值变成一列数据
data[:10].to_csv("./test003.csv", columns=['open'], index=False)
data3 = pd.read_csv('test003.csv')
data3.head()
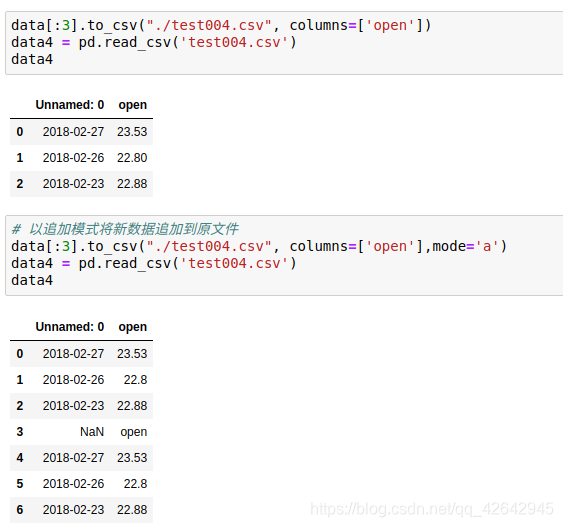
- 指定追加方式
追加数据时,又存进了一个列名,所以当以追加方式添加数据的时候,一定要去掉列名columns,指定header=False
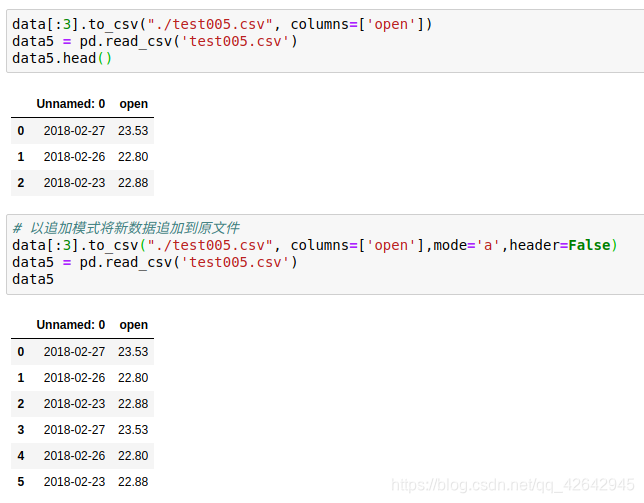
HDF5
read_hdf与to_hdf
HDF5文件的读取和存储需要指定一个键,值为要存储的DataFrame
pandas.read_hdf(path_or_buf,key =None,** kwargs)从h5文件当中读取数据- path_or_buffer:文件路径
- key:读取的键
- mode:打开文件的模式
- return:Theselected object
- DataFrame.to_hdf(path_or_buf, key, \kwargs)
案例
准备数据:
链接:https://pan.baidu.com/s/10H4DM24u2GyLEZtP4XGb1w
提取码:nb8c
- 读取文件
day_high = pd.read_hdf("./stock_data/day/day_high.h5")
如果读取的时候出现以下错误
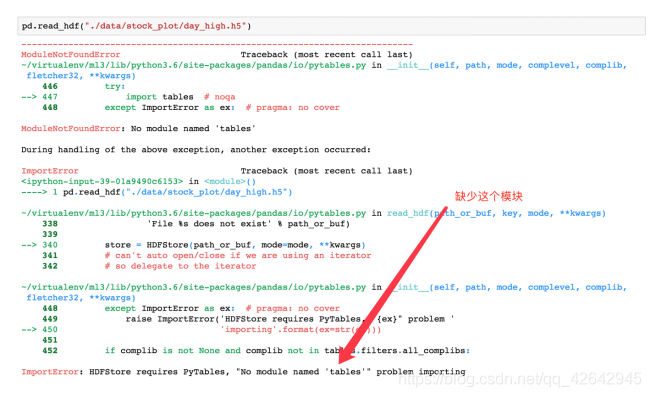
需要安装安装tables模块避免不能读取HDF5文件
pip install tables

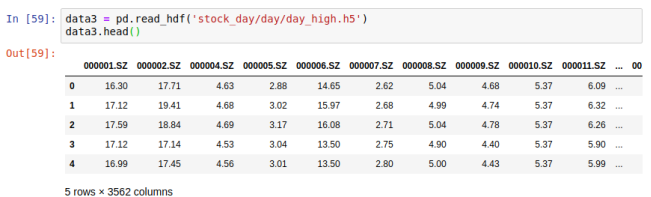
- 存储文件
day_high.to_hdf("./test.h5", key="day_high")
再次读取的时候, 需要指定键的名字
new_high = pd.read_hdf("./test.h5", key="day_high")
JSON
Json是我们常用的一种数据交换格式,前面在前后端的交互经常用到,也会在存储的时候选择这种格式。所以我们需要知道Pandas如何进行读取和存储JSON格式。
read_json
- pandas.read_json(path_or_buf=None, orient=None, typ=‘frame’, lines=False)
- 将JSON格式准换成默认的Pandas DataFrame格式
- orient : string,Indication of expected JSON string format.
- ‘split’ : dict like {index -> [index], columns -> [columns], data -> [values]}
- ‘records’ : list like [{column -> value}, … , {column -> value}]
- ‘index’ : dict like {index -> {column -> value}}
- ‘columns’ : dict like {column -> {index -> value}},默认该格式
- ‘values’ : just the values array
- orient:文件的结构,这里的参数的值必须与文件的结构相符,index,以行为单位; columns,以列为单位;records,以记录为单位; * 不同的参数值只影响文件的结构,不影响实际的数据
- lines : boolean, default False
- 按照每行读取json对象,lines: 也要和文件的结构相符,之在orient='records’才有意义
- typ : default ‘frame’, 指定转换成的对象类型series或者dataframe
数据准备
链接:https://pan.baidu.com/s/1rJjjPaXGICnkNLhAPGsaiQ
提取码:8rw0
案例
- 数据介绍
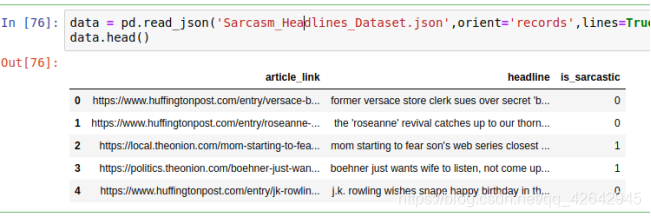
这里使用一个新闻标题讽刺数据集,格式为json。is_sarcastic:1讽刺的,否则为0;headline:新闻报道的标题;article_link:链接到原始新闻文章。存储格式为:
{"article_link": "https://www.huffingtonpost.com/entry/versace-black-code_us_5861fbefe4b0de3a08f600d5", "headline": "former versace store clerk sues over secret 'black code' for minority shoppers", "is_sarcastic": 0}
{"article_link": "https://www.huffingtonpost.com/entry/roseanne-revival-review_us_5ab3a497e4b054d118e04365", "headline": "the 'roseanne' revival catches up to our thorny political mood, for better and worse", "is_sarcastic": 0}
- 读取
orient指定存储的json格式,lines指定按行作为一个样本
to_json - DataFrame.to_json(path_or_buf=None, orient=None, lines=False)
- 将Pandas 对象存储为json格式
- path_or_buf=None:文件地址
- orient:存储的json形式,{‘split’,’records’,’index’,’columns’,’values’}
- lines:一个对象存储为一行
案例
- 存储文件
结果
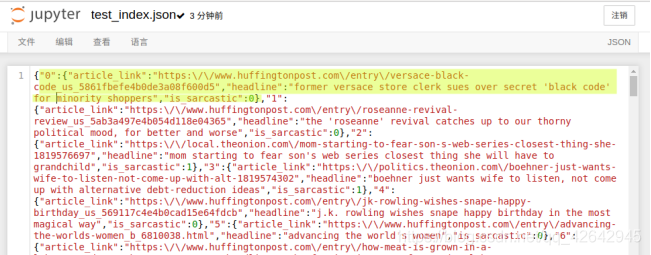
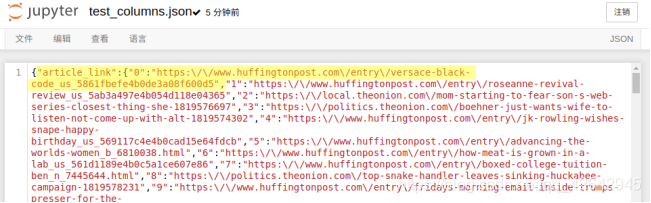
- 存储文件

结果
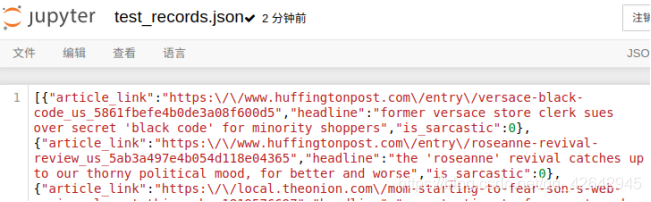
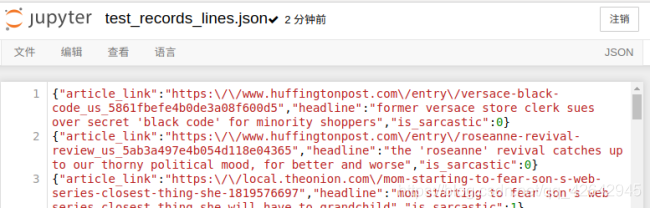
- 修改lines参数为True

结果
拓展
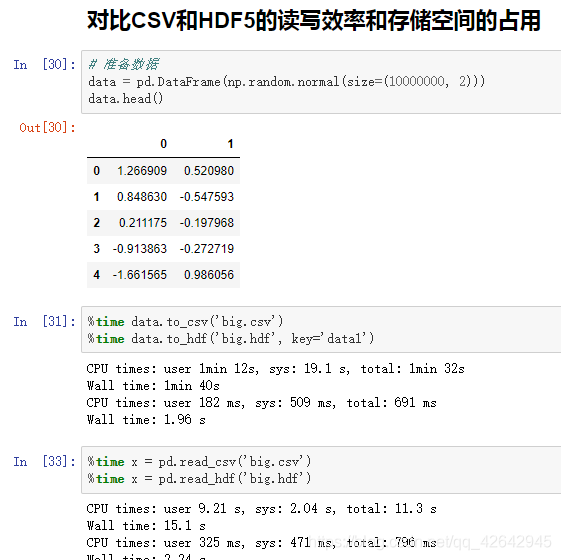
优先选择使用HDF5文件存储
- HDF5在存储的是支持压缩,使用的方式是blosc,这个是速度最快的也是pandas默认支持的
- 使用压缩可以提磁盘利用率,节省空间
- HDF5还是跨平台的,可以轻松迁移到hadoop 上面

版权声明:
笔者博客文章主要用来作为学习笔记使用,内容大部分整理自互联网,如有侵权,请联系博主删除!