功能:
数据卷:pod中容器之间共享数据,可以使用数据卷
应用程序健康检查:容器内服务可能进程堵塞无法处理请求,可以设置监控检查保证应用健壮性
复制应用程序实例:控制器维护着pod副本数量,保证一个pod或一组同类的pod数量始终可用
弹性伸缩:根据设定的指标(CPU利用率)自动缩放Pod副本数
服务发现:使用环境变量或DNS服务插件保证容器中程序发现Pod入口访问地址
负载均衡:一组Pod副本分配一个私有的集群IP地址,负载均衡转发请求到后端 容器,在集群内部其他Pod可通过这个ClusterIP访问应用
滚动更新:更新服务不中断,一次更新一个Pod,而不是同时删除整个服务
服务编排:通过文件描述部署服务,使得应用程序部署变得高效
资源监控:Node节点组件集成cAdvisor资源收集工具,可通过Heapster汇总整个集群节点资源数据,然后存储到InfkuxDB时序数据库,再由Grafana展示
提供认证和授权:支持角色访问控制(RBAC)认证授权等策略、
基本对象:
Pod:最小部署单元,一个Pod 有一个或多个容器组成,容器中共享存储和网络,在同一台docker主机上运行
Service:一个应用服务抽象,定义了Pod逻辑集合和访问这个Pod集合的策略
Volume:数据卷
Namespace
Lable:标签
基本对象更高层次抽象:
ReplicaSet:确保任何给定时间指定的Pod副本数量,并提供声明式更新等功能
Deployment:是一个更高层次的API对象,他管理RS和Pod,并提供声明式更新等功能
StatefulSet:适合持久性的应用程序,有唯一的网络标识符(IP),持久存储,有序的部署、扩展、删除和滚动更新。
DaemonSet:确保所有(或一些)节点运行同一个pod。当节点加入k8s集群中,Pod会调度到该节点上运行,当节点从集群中移除时,DaemonSet的Pod会被删除。删除DaemonSet会清理它所有创建的Pod
Job:一次性任务,运行完成后Pod销毁,不再重新启动新容器,还可以任务定时运行
核心组件:
etcd:保存了整个集群的状态
apiserver:提供了资源操作的唯一入口,并提供认证、授权、访问控制、API注册和发现等机制;
Controller manager:负责维护集群的状态,比如故障检测、自动扩展、滚动更新等;
scheduler:负责资源的调度,按照预定的调度策略将Pod调度到相应的机器上
kubelet:负责维护容器的生命周期,同时也负责Volume(CVI)和网络(CNI)的管理;
Container runtime:负责镜像管理以及Pod和容器的真正运行(CRI);
Kube-proxy:负责为Service提供cluster内部的服务发现和四层负载均衡
除了核心组件,还有一些推荐的Add-ons:
kube-dns负责为整个集群提供DNS服务
Ingress Controller为服务提供外网入口
Heapster提供资源监控
Dashboard提供GUI
Federation提供跨可用区的集群
Fluentd-elasticsearch提供集群日志采集、存储与查询
K8S API设计原则
1.所有API应该是声明式的
2.API对象是彼此互补而且可组合的。
3.高层API以操作意图为基础设计。
4.低层API根据高层API的控制需要设计。
5.尽量避免简单封装,不要有在外部API无法显式知道的内部隐藏的机制。
6.API操作复杂度与对象数量成正比
7.API对象状态不能依赖于网络连接状态
8.尽量避免让操作机制依赖于全局状态,因为在分布式系统中要保证全局状态的同步是非常困难的。
控制机制设计原则
1.控制逻辑应该只依赖于当前状态
2.假设任何错误的可能,并做容错处理。
3.尽量避免复杂状态机,控制逻辑不要依赖无法监控的内部状态
4.假设任何操作都可能被任何操作对象拒绝,甚至被错误解析。
5.每个模块都可以在出错后自动恢复。
6.每个模块都可以在必要时优雅地降级服务
Volume生命周期
Volume的生命周期包括5个阶段
1. Provisioning,即PV的创建,可以直接创建PV(静态方式),也可以使用StorageClass动态创建
2. Binding,将PV分配给PVC
3. Using,Pod通过PVC使用该Volume
4. Releasing,Pod释放Volume并删除PVC
5. Reclaiming,回收PV,可以保留PV以便下次使用,也可以直接从云存储中删除
根据这5个阶段,Volume的状态有以下4种
Available:可用
Bound:已经分配给PVC
Released:PVC解绑但还未执行回收策略
Failed:发生错误
整体架构:
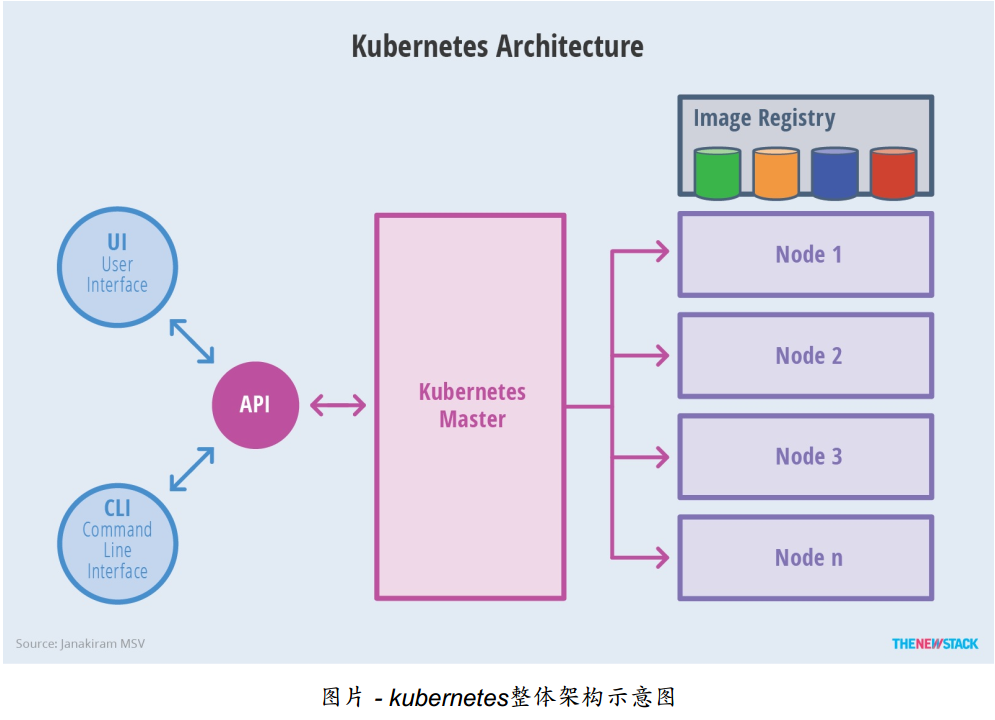
Master架构:

Node架构:
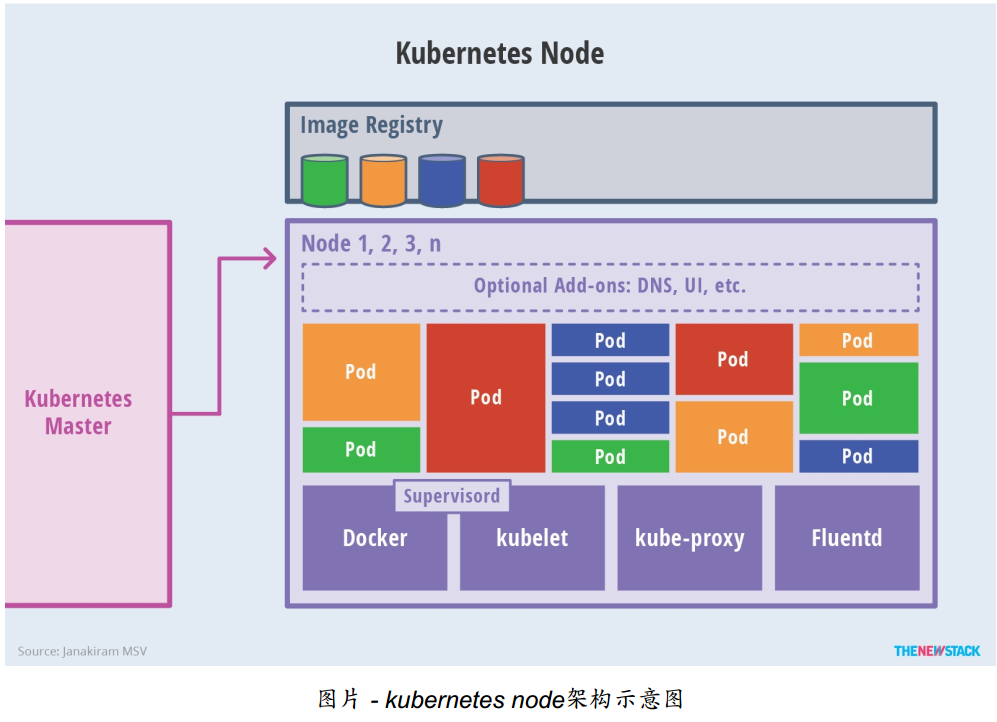
集群:
Master节点:
Master节点上面主要由四个模块组成,APIServer,schedule,controller-manager,etcd
APIServer: APIServer负责对外提供RESTful的kubernetes API的服务,它是系统管理指令的统一接口,任何对资源的增删该查都要交给APIServer处理后再交给etcd,如图,kubectl(kubernetes提供的客户端工具,该工具内部是对kubernetes API的调用)是直接和APIServer交互的。
schedule负责调度Pod到合适的Node上,如果把scheduler看成一个黑匣子,那么它的输入是pod和由多个Node组成的列表,输出是Pod和一个Node的绑定。 kubernetes目前提供了调度算法,同样也保留了接口。用户根据自己的需求定义自己的调度算法。
controller manager: 如果APIServer做的是前台的工作的话,那么controller manager就是负责后台的。每一个资源都对应一个控制器。而control manager就是负责管理这些控制器的,比如我们通过APIServer创建了一个Pod,当这个Pod创建成功后,APIServer的任务就算完成了。
etcd:etcd是一个高可用的键值存储系统,kubernetes使用它来存储各个资源的状态,从而实现了Restful的API。
Node节点:
每个Node节点主要由三个模板组成:kublet, kube-proxy
kube-proxy: 该模块实现了kubernetes中的服务发现和反向代理功能。kube-proxy支持TCP和UDP连接转发,默认基Round Robin算法将客户端流量转发到与service对应的一组后端pod。服务发现方面,kube-proxy使用etcd的watch机制监控集群中service和endpoint对象数据的动态变化,并且维护一个service到endpoint的映射关系,从而保证了后端pod的IP变化不会对访问者造成影响,另外,kube-proxy还支持session affinity。
kublet:kublet是Master在每个Node节点上面的agent,是Node节点上面最重要的模块,它负责维护和管理该Node上的所有容器,但是如果容器不是通过kubernetes创建的,它并不会管理。本质上,它负责使Pod的运行状态与期望的状态一致。
分层架构:
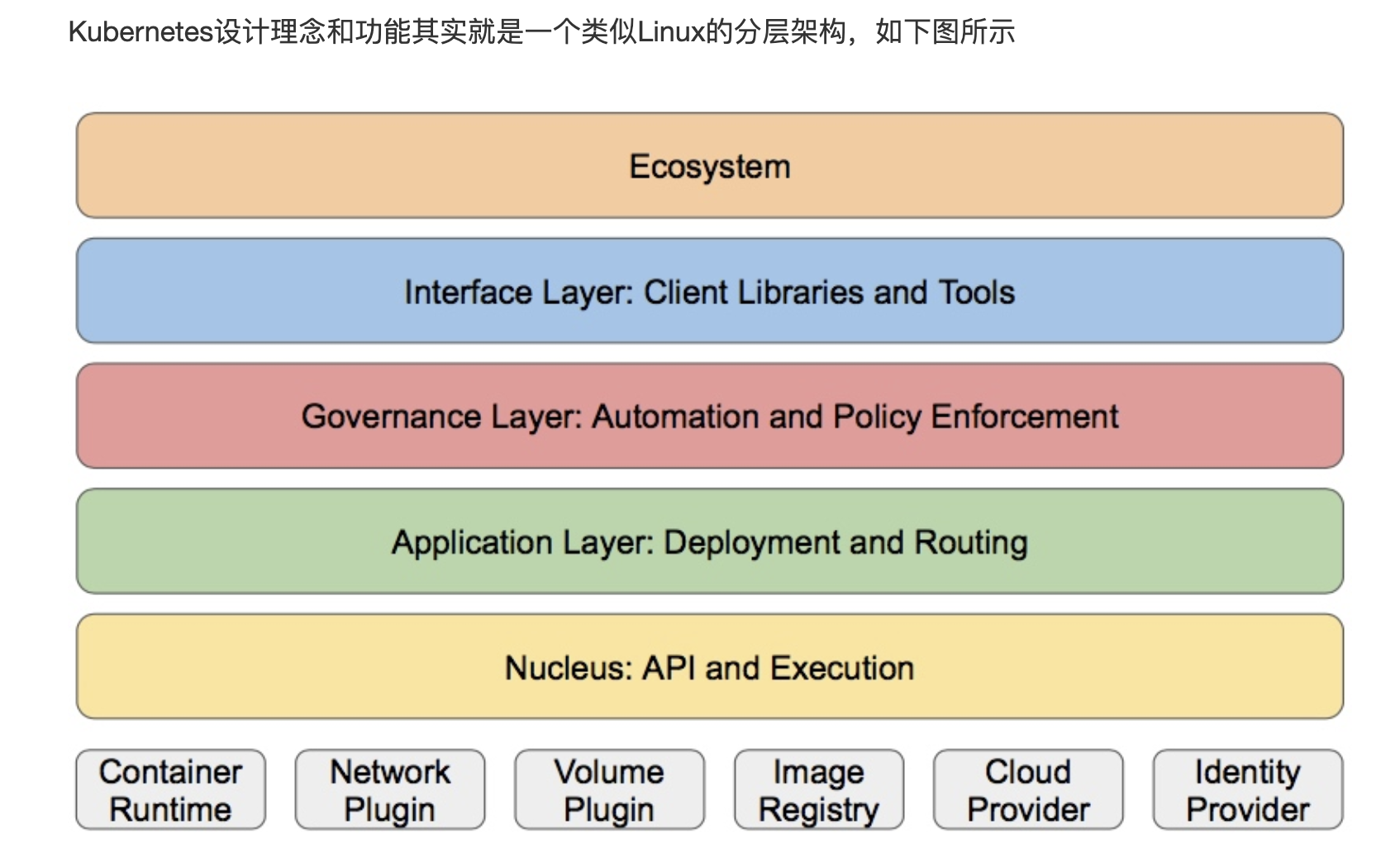
- 核心层:Kubernetes最核心的功能,对外提供API构建高层的应用,对内提供插件式应用执行环境
- 应用层:部署(无状态应用、有状态应用、批处理任务、集群应用等)和路由(服务发现、DNS解析等)
- 管理层:系统度量(如基础设施、容器和网络的度量),自动化(如自动扩展、动态Provision等)以及策略管理(RBAC、Quota、PSP、NetworkPolicy等)
- 接口层:kubectl命令行工具、客户端SDK以及集群联邦
- 生态系统:在接口层之上的庞大容器集群管理调度的生态系统,可以划分为两个范畴
-
- Kubernetes外部:日志、监控、配置管理、CI、CD、Workflow、FaaS、OTS应用、ChatOps等
- Kubernetes内部:CRI、CNI、CVI、镜像仓库、Cloud Provider、集群自身的配置和管理等