本次项目Github链接
一、需求分析
- 1.程序可读入任意英文文本文件,该文件中英文词数大于等于1个。
- 2.程序需要很壮健,能读取容纳英文原版《哈利波特》10万词以上的文章。
- 3.指定单词词频统计功能:用户可输入从该文本中想要查找词频的一个或任意多个英文单词,运行程序的统计功能可显示对应单词在文本中出现的次数和柱状图。
- 4.高频词统计功能:用户从键盘输入高频词输出的个数k,运行程序统计功能,可按文本中词频数降序显示前k个单词的词频及单词。
- 5.统计该文本所有单词数量及词频数,并能将单词及词频数按字典顺序输出到文件result.txt。
二、功能设计
- 基本功能:
- 产品介绍以及使用帮助
- 从本地文件中读入一个文本文件
- 统计每一个单词的出现次数
- 用户通过输入选项,可以查找大于输入的频数的单词
- 可以读出查询后的结果,包括全部的词汇和筛选出的词汇
- 扩展功能:
- 用户可以直观的看到总共的词汇量
- 操作界面干净美观
- 系统稳定
三、设计实现
1、整个程序在一个大的死循环中进行,只有在用户选择推出程序时才可以退出程序
2、定义k=1,当进入while循环中,只有退出系统的的命令为k=0
3、在操作页面排版时用到了windows自用的库函数
void SetPosition(int x,int y)
{
HANDLE winHandle; //句柄
COORD pos = {x,y};
winHandle = GetStdHandle(STD_OUTPUT_HANDLE);
//设置光标的坐标
SetConsoleCursorPosition(winHandle,pos);
}
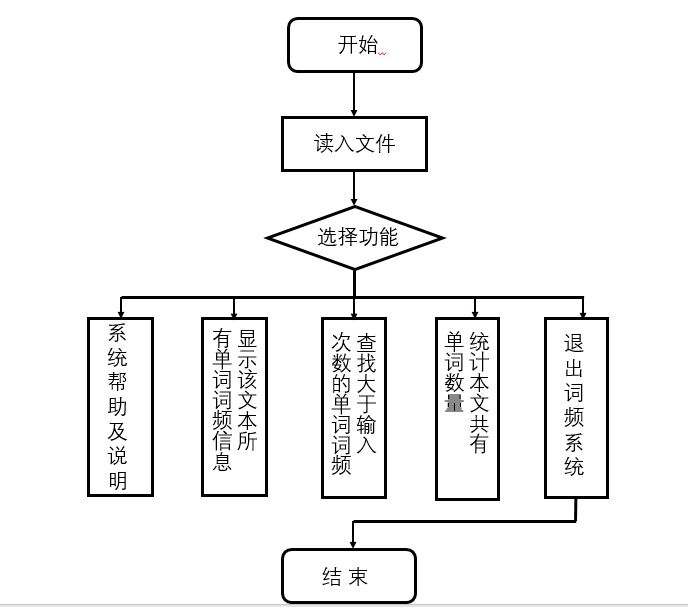
4、功能流程图
四、 测试运行
下图是刚进入程序时的操作界面
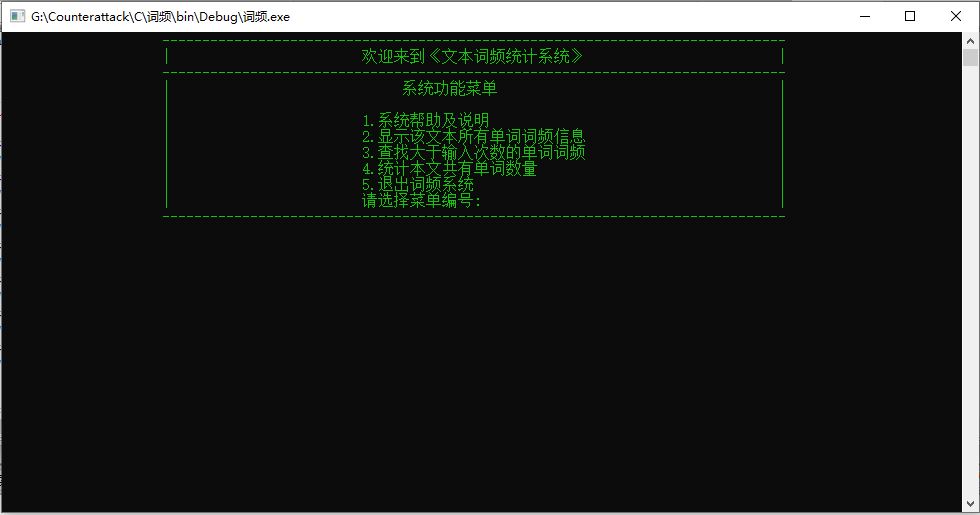
这是一个用户操作说明

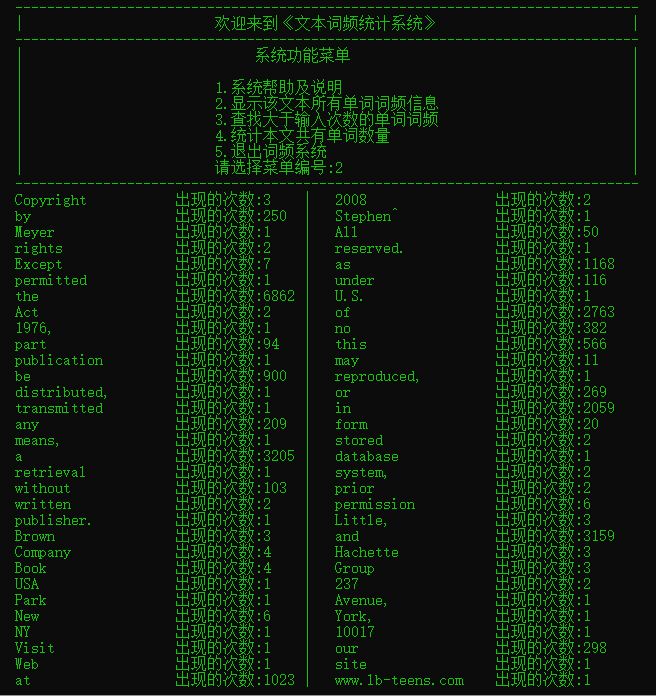
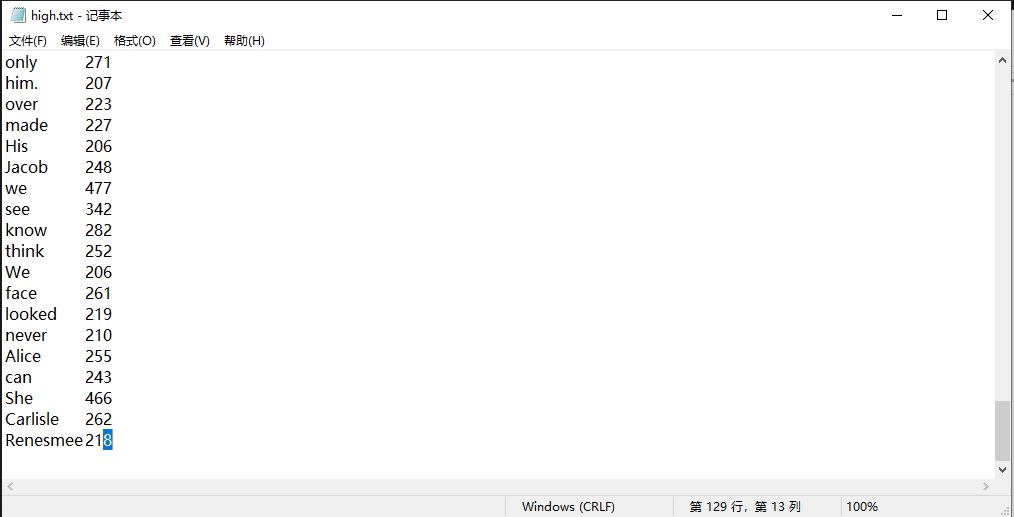
这是读取了一个19W单词的文本文件后显示所有单词的词频显示并读出到txt文件中
这是用户输入100后,系统筛选出该文本中词频数大于等于100的单词显示并读出到txt文件中

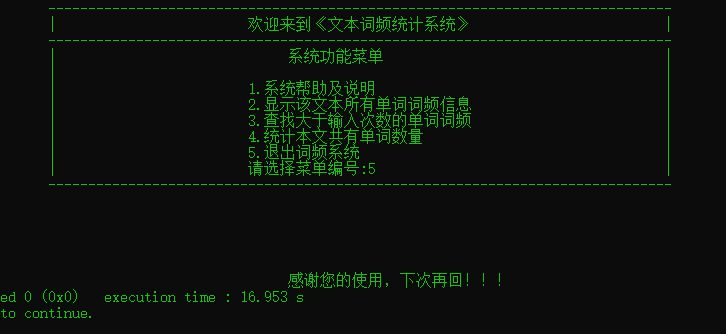
选择退出时的界面
这是显示该文本所有单词及其词频数后自动生成并保存的文本文件

这是显示帅选出的单词及其词频数后自动生成并保存的文本文件
五、代码展示
这段代码是自定义的一些变量,在后面的文本控制可以方便的使用和有效的节省时间
#include <windows.h>
#define SEP "------------------------------------------------------------------------------"//界面的总宽度
#define COL 78
#define MARGIN_X 20 //左边距
#define MAP_START_Y 3 //开始y轴坐标
#define MAP_END_Y 11 //结束y轴坐标
#define INFO_START_Y 12 //信息界面开始的Y坐标
#define INFO_END_Y 19 //信息界面结束的Y坐标
这些是自定义的一些函数,依旧是提高效率
void SetPosition(int x,int y);
/*从x行,y列开始清rowcount行*/
void Clear(int x,int y,int rowcount);
/*从第x列,y行开始,把第rowcount行输入空格*/
void SetColor(int froeColor,int bankColor);
/*设置文字的前景色,和背景色*/
void Clear(int x,int y,int rowcount)
{
//每行清除78个字符——每行打印78个空格
int i,j;
for(i=0;i<rowcount;i++)
{
SetPosition(x,y+i);
for(j=0;j<78;j++)
{
printf(" ");
}
}
}
void SetPosition(int x,int y)
{
HANDLE winHandle; //句柄
COORD pos = {x,y};
winHandle = GetStdHandle(STD_OUTPUT_HANDLE);
//设置光标的坐标
SetConsoleCursorPosition(winHandle,pos);
}
void SetColor(int foreColor,int bankColor)
{
HANDLE winHandle; //句柄
winHandle = GetStdHandle(STD_OUTPUT_HANDLE);
//设置文字颜色
SetConsoleTextAttribute(winHandle,foreColor+bankColor*0x10);
}
程序主函数,其中k为死循环的条件变量
char temp[WORD_LENGTH]; //临时存放单词的词组
int k=1; //用于while循环体,形成死循环
FILE *fp; //打开要读取的文件
if((fp=fopen("Breaking Dawn.txt", "r"))==NULL )
{
printf("Open file failed!!\n");
exit(1);
}
while( EOF != (fscanf(fp,"%s",temp)) )//循环读取文本中的内容
{
CountWord(temp);
}
fclose(fp); //关闭文件
while(k)
{
PrintResult(); //输出统计结果;
}
system("pause");
Release(); //释放内存,养成好习惯
利用指针来进行对文本的查询和统计
void CountWord(char *current)//单词统计
{
wordNode *pNode = NULL;
pNode = SearchWord(current);
if(NULL == pNode)
{
return;
}
else
{
pNode->iWordCount++;
}
}
wordNode * SearchWord(char *current)//查找单词所在节点
{
if( NULL == pHeader) //当链表为空的时候,也就统计第一个单词时
{
pHeader = new wordNode;
strcpy(pHeader->word, current);
pHeader->iWordCount = 0;
pHeader->pNext = NULL;
return pHeader;
}
//搜索现有的链表
wordNode *pCurr = pHeader;
wordNode *pPre = NULL;
while( (NULL != pCurr) && (0 != strcmp(pCurr->word, current)) )
{
pPre = pCurr;
pCurr = pCurr->pNext;
}
if(NULL == pCurr) //该单词不存在
{
pCurr = new wordNode;
strcpy(pCurr->word, current);
pCurr->iWordCount = 0;
pCurr->pNext = NULL;
pPre->pNext = pCurr;
}
return pCurr;
}
六、 总结
通过本项目,我对软件的PSP个人开发流程有了大致的了解,这种规范化的流程对比我以往的代码编写方法确实有许多的优点;比如大大减少了后期的修改和补充环节,在实现过程中可以按照需求分析和功能设计的去实现,而不是以前的想到什么写什么,我也学到了一些新知识,比如怎样在Github上发布软件项目,等整个项目完成之后感觉到更加充实和满足;不过,我也发现了自己还有许多不足之处,比如长时间没有编程,编程实现困难,前期的工作不充分,导致花了大量的时间去修改和补充。在本次项目开发中,我也有一点遗憾,一是没有实现区间筛选功能,二是因个人能力不足没有将指定单词的柱状图完全实现。
七、PSP展示
在整个项目中实现过程既是消耗时间做多的,也是预估和实践相差悬殊最大的环节,这说明自己的编程能力还是不够,有待加强,除了实现过程之外,在后期的代码复审和过程改进计划也浪费了很多的时间,这说明前期的做的工作还是不够,没有把需求分析和功能设计这两个环节做透。
