转载自http://www.visiondummy.com/2014/04/curse-dimensionality-affect-classification/
分类中的维度诅咒
介绍
在本文中,我们将讨论所谓的“维度诅咒”,并解释在设计分类器时它的重要性。在下面的章节中,我将提供这个概念的直观解释,由一个由于维数诅咒而过度拟合的明显例子说明。
考虑一个例子,其中我们有一组图像,每个图像描绘一只猫或一只狗。我们想创建一个能够自动区分狗和猫的分类器。为此,我们首先需要考虑可以用数字表示的每个对象类的描述符,这样数学算法(即分类器)可以使用这些数字来识别对象。例如,我们可以说猫和狗的颜色通常不同。区分这两个类的可能描述符可以由三个数组成; 正在考虑的图像的平均红色,平均绿色和平均蓝色。例如,一个简单的线性分类器可以线性地组合这些特征来决定类标签:
If 0.5*red + 0.3*green + 0.2*blue > 0.6 : return cat;
else return dog;
然而,这三种颜色描述数字,称为特征,显然不足以获得完美的分类。因此,我们可以决定添加一些描述图像纹理的特征,例如通过计算X和Y方向的平均边缘或梯度强度。我们现在有5个特征组合在一起,可以通过分类算法来区分猫和狗。
为了获得更准确的分类,我们可以根据颜色或纹理直方图,统计矩等添加更多功能。也许我们可以通过仔细定义几百个这些功能来获得完美的分类?这个问题的答案可能听起来有点违反直觉:不,我们不能!。事实上,在某一点之后,通过添加新功能来增加问题的维度实际上会降低分类器的性能。这由图1说明,并且通常被称为“维度的诅咒”。
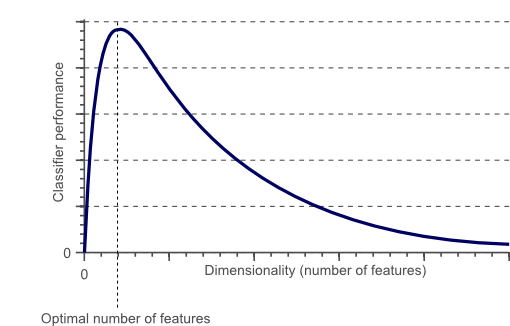
图1.随着维度的增加,分类器的性能会提高,直到达到最佳要素数。进一步增加维度而不增加训练样本的数量导致分类器性能的降低。
在接下来的部分中,我们将回顾上述原因是什么,以及如何避免维度的诅咒。
维度和过度拟合的诅咒
在早先介绍的猫和狗的例子中,我们假设有无数的猫和狗生活在我们的星球上。然而,由于我们有限的时间和处理能力,我们只能获得10张猫狗照片。然后,分类的最终目标是基于这10个训练实例训练分类器,该分类器能够正确地分类我们不了解的无限数量的狗和猫实例。
现在让我们使用一个简单的线性分类器,并尝试获得一个完美的分类。我们可以从一个特征开始,例如图像中的平均“红色”颜色:

图2.单个功能不会导致我们的训练数据完美区分。
图2显示,如果仅使用单个特征,则无法获得完美的分类结果。因此,我们可能决定添加另一个特征,例如图像中的平均“绿色”颜色:

图3.添加第二个特征仍然不会导致线性可分的分类问题:在此示例中,没有一条线可以将所有猫与所有狗分开。
最后,我们决定添加第三个特征,例如图像中的平均“蓝色”颜色,从而产生三维特征空间:

图4.在我们的示例中,添加第三个特征会导致线性可分的分类问题。存在一种将狗与猫完美分开的平面。
在三维特征空间中,我们现在可以找到一个完美地将狗与猫分开的平面。这意味着可以使用这三个特征的线性组合来获得10幅图像的训练数据的完美分类结果:
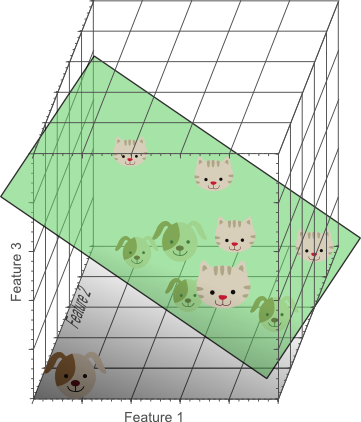
图5.我们使用的特征越多,我们成功区分类的可能性就越高。
上面的插图似乎表明,在获得完美的分类结果之前增加特征的数量是训练分类器的最佳方式,而在引言中,如图1所示,我们认为情况并非如此。但是,请注意当我们增加问题的维数时,训练样本的密度如何呈指数下降。
在1D情况下(图2),10个训练实例覆盖了完整的1D特征空间,其宽度为5个单位间隔。因此,在1D情况下,样品密度为10/5 = 2个样品/间隔。然而,在二维情况下(图3),我们仍然有10个训练实例,现在覆盖了一个面积为5×5 = 25个单位正方形的2D特征空间。因此,在2D情况下,样品密度为10/25 = 0.4个样品/间隔。最后,在3D情况下,10个样本必须覆盖5x5x5 = 125个单位立方体的特征空间体积。因此,在3D情况下,样品密度为10/125 = 0.08个样品/间隔。
如果我们继续添加特征,则特征空间的维度会增长,并变得更稀疏和稀疏。由于这种稀疏性,找到可分离的超平面变得更加容易,因为当特征的数量变得无限大时,训练样本位于最佳超平面的错误侧的可能性变得无限小。但是,如果我们将高维分类结果投影回较低维空间,则与此方法相关的严重问题变得明显:

图6.使用太多特征会导致过度拟合。分类器开始学习特定于训练数据的异常,并且在遇到新数据时不能很好地概括。
图6显示了投影到2D特征空间的3D分类结果。尽管数据在3D空间中是线性可分的,但在较低维度的特征空间中却不是这种情况。实际上,添加第三维以获得完美的分类结果,简单地对应于在较低维特征空间中使用复杂的非线性分类器。因此,分类器学习我们的训练数据集的特例和异常。因此,生成的分类器将在真实世界数据上失败,包括通常不遵守这些异常的无限量的看不见的猫和狗。
这个概念被称为过度拟合,是维度诅咒的直接结果。图7显示了仅使用2个特征而不是3个特征训练的线性分类器的结果:

图7.尽管训练数据未被完美分类,但该分类器在看不见的数据上比图5中的数据获得更好的结果。
虽然图7中显示的具有决策边界的简单线性分类器似乎比图5中的非线性分类器表现更差,但是这个简单的分类器更好地概括了看不见的数据,因为它没有学习仅在我们的训练数据中的特定异常。巧合。换句话说,通过使用较少的特征,避免了维数的诅咒,使得分类器不会过度拟合训练数据。
下面的解释非常经典
图8以不同的方式说明了上述内容。假设我们想要仅使用一个值为0到1的单个特征来训练分类器。让我们假设这个特征对于每只猫和狗都是唯一的。如果我们希望我们的训练数据覆盖此范围的20%,那么所需的训练数据量将占整个猫狗数量的20%。现在,如果我们添加另一个特征,生成2D特征空间,事情会发生变化; 为了覆盖20%的2D特征范围,我们现在需要在每个维度中获得猫和狗总数的45%(0.45 ^ 2 = 0.2)。在3D情况下,这变得更糟:要覆盖20%的3D特征范围,我们需要在每个维度中获得总数的58%(0.58 ^ 3 = 0.2)。
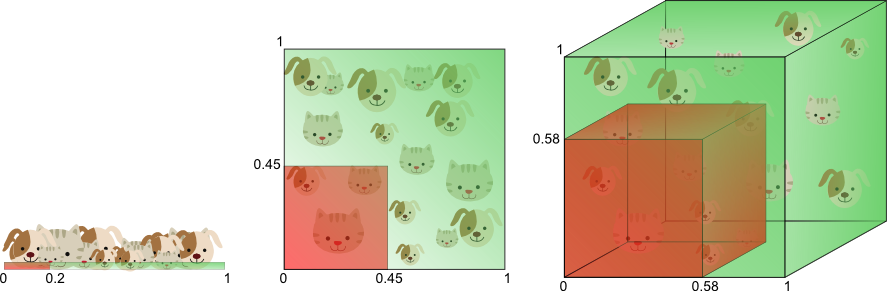
图8.覆盖20%特征范围所需的训练数据量随着维度的数量呈指数增长。
换句话说,如果可用的训练数据量是固定的,那么如果我们继续添加维度就会发生过度拟合。另一方面,如果我们不断增加维度,训练数据量需要以指数级增长,以保持相同的覆盖范围并避免过度拟合。
在上面的例子中,我们展示了维度的诅咒引入了训练数据的稀疏性。我们使用的特征越多,数据就越稀疏,因此准确估计分类器的参数(即其决策边界)变得更加困难。维度诅咒的另一个影响是,这种稀疏性不是均匀分布在搜索空间上。实际上,原点周围的数据(在超立方体的中心)比搜索空间的角落中的数据要稀疏得多。这可以理解如下:
想象一个代表2D特征空间的单位正方形。特征空间的平均值是该单位正方形的中心,距离该中心单位距离内的所有点都在一个单位圆内,该单位圆内接单位正方形。不属于该单位圆的训练样本更靠近搜索空间的角落而不是其中心。这些样本难以分类,因为它们的特征值差异很大(例如,单位正方形的相对角上的样本)。因此,如果大多数样本落在内接单位圆内,则分类更容易,如图9所示:

图9.位于单位圆外的训练样本位于特征空间的角落,并且比特征空间中心附近的样本更难分类。
现在一个有趣的问题是,当我们增加特征空间的维数时,圆(超球面)的体积如何相对于正方形(超立方体)的体积发生变化。尺寸d的单位超立方体的体积总是1 ^ d = 1. 尺寸d和半径0.5 的内切超球体的体积可以计算为:
(1) 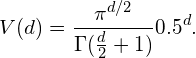
图10显示了当维度增加时,这个超球体的体积如何变化:
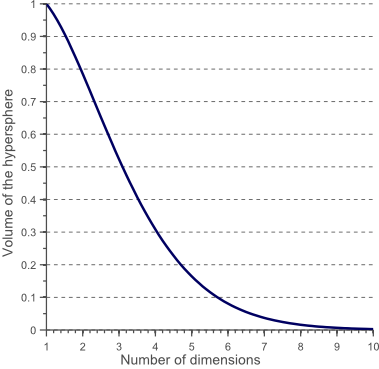
图10.随着维数的增加,超球面的体积趋向于零。
则

这表明,当维数趋于无穷大时,超球体的体积倾向于零,而周围超立方体的体积保持不变。这种令人惊讶且相当反直觉的观察部分地解释了与分类中的维度诅咒相关的问题:在高维空间中,大多数训练数据驻留在定义特征空间的超立方体的角落中。如前所述,特征空间角落中的实例比超球面质心周围的实例更难分类。这由图11示出,其示出了2D单位正方形,3D单位立方体以及具有2 ^ 8 = 256个角的8D超立方体的创造性可视化:
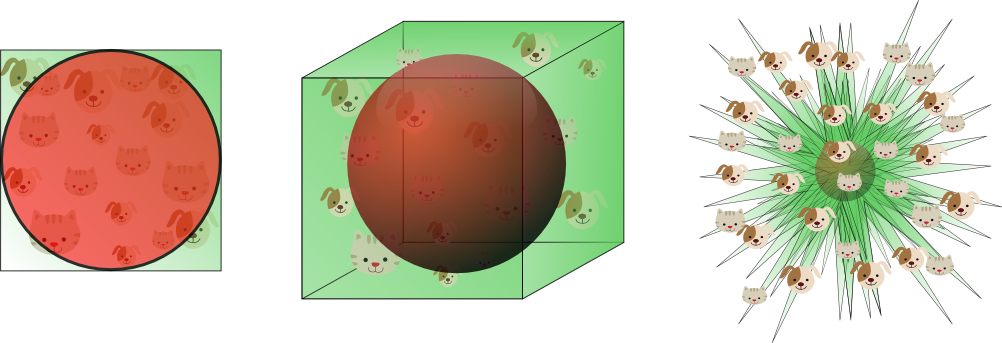
图11.随着维度的增加,更大比例的训练数据驻留在要素空间的角落中。
对于8维超立方体,大约98%的数据集中在其256个角上。因此,当特征空间的维数变为无穷大时,从样本点到质心的最小和最大欧几里得距离的差值与最小距离本身的比率趋向于零:
(2) 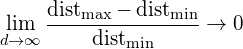
因此,距离测量开始失去其在高维空间中测量不相似性的有效性。由于分类器依赖于这些距离测量(例如欧几里德距离,马哈拉诺比斯距离,曼哈顿距离),因此在较低维空间中分类通常更容易,其中较少特征用于描述感兴趣对象。类似地,高斯似然性在高维空间中变为平坦且重尾的分布,使得最小和最大似然之间的差异与最小似然本身的比率趋于零。
如何避免维数的诅咒?
图1显示,当问题的维数变得太大时,分类器的性能会降低。那么问题是“太大”意味着什么,以及如何避免过度拟合。遗憾的是,没有固定的规则来定义在分类问题中应该使用多少特征。实际上,这取决于可用的训练数据量(特征的数量和样本数量有关),决策边界的复杂性以及所使用的分类器的类型。
如果理论无限数量的训练样本可用,则维度的诅咒不适用,我们可以简单地使用无数个特征来获得完美的分类。训练数据的大小越小,应使用的特征越少。如果N个训练样本足以覆盖单位区间大小的1D特征空间,则需要N ^ 2个样本来覆盖具有相同密度的2D特征空间,并且在3D特征空间中需要N ^ 3个样本。换句话说,所需的训练实例数量随着使用的维度数量呈指数增长。
此外,倾向于非常准确地模拟非线性决策边界的分类器(例如,神经网络,KNN分类器,决策树)不能很好地推广并且易于过度拟合。因此,当使用这些分类器时,维度应该保持相对较低。如果使用易于推广的分类器(例如朴素贝叶斯线性分类器),那么所使用的特征的数量可以更高,因为分类器本身不那么具有表现力(less expressive)。图6显示在高维空间中使用简单分类器模型对应于在较低维空间中使用复杂分类器模型。
因此,当在高维空间中估计相对较少的参数时,以及在较低维空间中估计大量参数时,都会发生过度拟合。例如,考虑高斯密度函数,由其均值和协方差矩阵参数化。假设我们在3D空间中操作,使得协方差矩阵是由3个独特元素组成的3×3对称矩阵(对角线上的3个方差和非对角线上的3个协方差)。与分布的三维均值一起,这意味着我们需要根据训练数据估计9个参数,以获得表示数据可能性的高斯密度。在1D情况下,仅需要估计2个参数(均值和方差),而在2D情况下需要5个参数(2D均值,两个方差和协方差)。我们再次可以看到,要估计的参数数量随着维度的数量而增长。
在前面的文章中,我们表明,如果要估计的参数数量增加(并且如果估计的偏差和训练数据的数量保持不变),参数估计的方差会增加。这意味着,由于方差的增加,如果维数上升,我们的参数估计的质量会降低。分类器方差的增加对应于过度拟合。
另一个有趣的问题是应该使用哪些特征。给定一组N个特征; 我们如何选择M个特征的最佳子集,使得M <N?一种方法是在图1所示的曲线中搜索最优值。由于为所有特征的所有可能组合训练和测试分类器通常是难以处理的,因此存在几种尝试以不同方式找到该最佳值的方法。这些方法称为特征选择算法,并且通常采用启发式(贪婪方法,最佳优先方法等)来定位最佳数量和特征组合。
另一种方法是用一组M个特征替换N个特征的集合,每个特征是原始特征值的组合。试图找到原始特征的最佳线性或非线性组合以减少最终问题的维度的算法称为特征提取方法。一种众所周知的降维技术是主成分分析(PCA),它产生原始N特征的不相关的线性组合。PCA试图找到较低维度的线性子空间,以便保持原始数据的最大方差。但是,请注意,数据的最大差异不一定代表最具辨别力的信息。
最后,在分类器训练期间用于检测和避免过度拟合的宝贵技术是交叉验证。交叉验证方法将原始训练数据分成一个或多个训练子集。在分类器训练期间,一个子集用于测试所得分类器的准确度和精度,而其他子集用于参数估计。如果用于训练的子集的分类结果与用于测试的子集的结果大不相同,则过度拟合正在发挥作用。如果只有有限数量的训练数据可用,则可以使用几种类型的交叉验证,例如k折交叉验证和留一交叉验证。

结论
在本文中,我们讨论了特征选择,特征提取和交叉验证的重要性,以避免由于维度的诅咒而过度拟合。通过一个简单的例子,我们回顾了维度诅咒在分类器训练中的重要影响,即过度拟合。