文章大纲
- 介绍
- 决策树
- 如何构建决策树
- 树木构建算法
- 分类问题中裂缝的其他质量标准
- 决策树如何与数字特征一起工作
- 关键树参数
- 类
DecisionTreeClassifier在Scikit学习 - 回归问题中的决策树
3.最近邻法
- 真实应用中最近邻方法
- 类
KNeighborsClassifier在Scikit学习
4.选择模型参数和交叉验证
5.应用实例和复杂案例
- 客户流失预测任务中的决策树和最近邻法
- 决策树的复杂案例
- MNIST手写数字识别任务中的决策树和k-NN
- 最近邻法的复杂案例
6.决策树的优缺点和最近邻法
7.作业#3
8.有用的资源
以下材料最好用Jupyter notebook 阅读,如果您克隆course repository,可以使用Jupyter在本地复制。
1.简介
在我们深入研究本周文章的材料之前,让我们先谈谈我们要解决的问题类型以及它在激动人心的机器学习领域的地位。T. Mitchell的书“ 机器学习”(1997)给出了机器学习的经典定义如下:
A computer program is said to learn from experience E with respect to some class of tasks T and performance measure P, if its performance at tasks in T, as measured by P, improves with experience E.。
在各种问题设置中,T,P和E可以指代完全不同的事物。在机器学习中一些最流行的任务是以下几种:
- 根据其特征将实例分类到其中一个类别;
- 回归 - 基于实例的其他特征预测数值目标特征;
- 聚类 - 根据这些实例的特征识别实例的分组,以便组内的成员彼此更相似,而不是其他组中的成员;
- 异常检测 - 搜索与样本的其余部分或某些实例组“非常不同”的实例;
- 等等。
“深度学习”中的“机器学习基础”一章提供了很好的概述(Ian Goodfellow,Yoshua Bengio,Aaron Courville,2016)。
经验E指的是数据(没有它我们就不能去任何地方)。机器学习算法可以分为监督或无监督训练的算法。在无监督的学习任务中,人们有一组由一组特征描述的实例组成。在监督学习问题中,还有一个目标变量,这是我们希望能够预测的,对于训练集中的每个实例都是已知的。
例
分类和回归是监督学习问题。例如,作为信贷机构,我们可能希望根据客户累积的数据预测贷款违约。在这里,经验E是可用的训练数据:一组实例(客户),每个特征的集合(例如年龄,工资,贷款类型,过去的贷款违约等)和目标变量(是否他们拖欠贷款)。这个目标变量只是贷款违约的事实(1或0),所以请记住这是一个(二元)分类问题。如果您反而预测贷款支付的时间是多久,这将成为一个回归问题。
最后,机器学习定义中使用的第三个术语是算法性能评估P的度量。这些指标因各种问题和算法而异,我们将在研究新算法时对它们进行讨论。现在,我们将 在测试集上引用分类算法的简单度量,正确答案的比例 - 准确度。
让我们来看看两个监督的学习问题:分类和回归。
2.决策树
我们从最受欢迎的方法之一开始概述分类和回归方法 - 决策树。决策树用于日常生活决策,而不仅仅用于机器学习。流程图实际上是决策树的可视化表示。例如,高等经济学院发布信息图表,使员工的生活更轻松。以下是在Institution门户网站上发布论文的一小段说明。

在机器学习方面,人们可以将其视为一种简单的分类器,根据内容(书籍,小册子,论文),期刊类型,原始出版物类型(科学期刊,会议记录)等确定适当的出版形式(书籍,文章,书籍章节,预印本,出版物)。
决策树通常是专家经验的概括,是分享特定过程知识的一种手段。例如,在引入可扩展机器学习算法之前,银行业的信用评分任务由专家解决。授予贷款的决定是基于一些直观(或经验)衍生的规则,可以表示为决策树。

在我们的下一个案例中,我们以“年龄”,“房屋所有权”,“收入”和“教育”为由解决了二元分类问题(批准/拒绝贷款)。
作为机器学习算法的决策树与上面所示的图基本相同; 我们合并类似“特征a的值小于x和特征b的值小于y ... => 分类1”形式的逻辑规则流到树状数据结构。该算法的优点是它们易于解释。例如,使用上述方案,银行可以向客户解释为什么他们被拒绝贷款:例如,客户没有房子,她的收入少于5,000。
正如我们稍后将看到的,许多其他模型虽然更准确,但没有这个属性,可以被视为更多的“黑盒子”方法,在这种方法中,更难以解释输入数据如何转换为输出。由于这种“可理解性”和人类决策的相似性(您可以轻松地向您的老板解释您的模型),决策树已经获得了极大的普及。C4.5,是分类方法的代表,甚至位列10个最佳的数据挖掘算法列表(“十大算法在数据挖掘”,知识和信息系统,2008 PDF)。
如何构建决策树
早些时候,我们看到放贷款的决定是根据年龄,资产,收入和其他变量做出的。但首先要看哪个变量?让我们讨论一个简单的例子,其中所有变量都是二进制的。
回想一下“20个问题”的游戏,这在引入决策树时经常被引用。你可能已经玩过这个游戏 - 一个人想到一个名人,而另一个人试图通过只问“是”或“否”问题来猜测。猜测者首先会问什么问题?当然,他们会问那个最多缩小剩余选项数量的人。询问“这是安吉丽娜朱莉吗?”,如果是否定的回应,将除了一个名人之外的所有人留在可能的范围内。相比之下,问“名人是女人吗?”会将可能性减少到大约一半。也就是说,“性别”功能将名人数据集分离得比“安吉丽娜朱莉”,“西班牙语”或“热爱足球”等其他功能更好。这种推理对应于基于熵的信息增益概念。
熵
Shannon的熵是针对具有N种可能状态的系统定义的,如下所示:
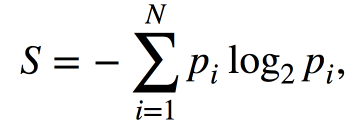
其中Pi是在第i个状态中找到系统的概率。这是物理学,信息论和其他领域中使用的一个非常重要的概念。熵可以描述为系统中的混沌程度。熵越高,系统的有序性越差,反之亦然。这将有助于我们进行“有效数据分离”,我们在“20个问题”的背景下提到了这一点。
玩具示例
为了说明熵如何帮助我们确定构建决策树的好特征,让我们来看一个玩具示例。我们将根据其位置预测球的颜色。

来源(俄文)
有9个蓝色球和11个黄色球。如果我们随机抽出一个球,那么它将是蓝色,概率为p1 = 9/20,黄色概率为p2 = 11/20,这给了我们一个熵S0 = -9/20 log2(9/20) - 11 / 20 log2(11/20)≈1。这个值本身可能不会告诉我们太多,但让我们看看如果我们将球分成两组,值如何变化:位置小于或等于12且大于12。
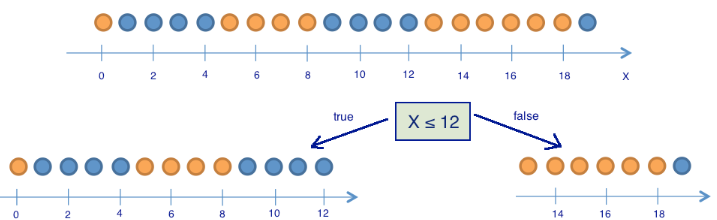
来源(俄文)
左组有13个球,8个蓝色和5个黄色。该组的熵是S1 = -5 / 13log2(5/13) - 8/13 log2(8/13)≈0.96。右侧组有7个球,1个蓝色和6个黄色。右组的熵是S2 = -1 / 7log2(1/7) - 6/7 log2(6/7)≈0.6。正如您所看到的,两组中的熵都有所下降,右侧组则更多。由于熵实际上是系统中的混沌程度(或不确定性),因此熵的减少称为信息增益。形式上,基于变量Q的分割的信息增益(IG)(在该示例中,它是变量“ x≤12”)被定义为
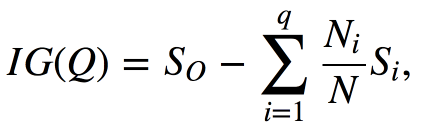
其中q是分割后的组数,Ni是样本中的对象数,其中变量Q等于第i个值。在我们的例子中,我们的分裂产生了两组(q = 2),一组有13个元素(N1 = 13),另一组有7个(N2 = 7)。因此,我们可以将信息增益计算为

事实证明,通过在“坐标小于或等于12”上分裂将球分成两组,这给了我们一个更有序的系统。让我们继续将它们分成小组,直到每组中的球都是相同的颜色。
对于正确的组,我们可以很容易地看到我们只需要使用“坐标小于或等于18”的额外分区。但是,对于左派,我们还需要三个。注意,所有球是相同颜色的组的熵等于0(log2(1)= 0)。
我们已成功构建了一个决策树,可根据其位置预测球的颜色。如果我们添加任何球,这个决策树可能不会很好,因为它完全适合训练集(最初的20个球)。如果我们想在这种情况下做得好,那么具有较少“问题”或分裂的树将更准确,即使它不完全适合训练集。我们稍后会讨论过度拟合的问题。
决策树构建算法
我们可以确保前一个例子中构建的树是最优的:只需要5个“问题”(以变量x为条件)就可以将决策树完美地拟合到训练集中。在其他分割条件下,生成的树会更深,即需要更多“问题”才能得到答案。
决策树构造的流行算法(如ID3或C4.5)的核心在于信息增益的贪婪最大化原则:在每一步,算法选择在分裂时提供最大信息增益的变量。然后递归地重复该过程,直到熵为零(或者一些小的值来解释过度拟合)。不同的算法使用不同的启发法来“提前停止”或“切断”以避免构造过度拟合的树。

分类问题中裂缝的其他质量标准
我们讨论了熵如何允许我们在树中形式化分区。但这只是一种启发式方法; 还有其他方式。
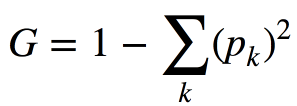
基尼系数不确定性(基尼杂质)
最大化此标准可以解释为同一子树中同一类对象的数量最大化(不要与Gini索引混淆)。
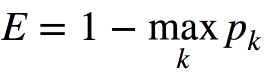
错误分类错误
在实践中,几乎从不使用错误分类错误,并且基尼系数不确定性和信息增益的工作方式类似。
对于二进制分类,熵和基尼不确定性采用以下形式:

其中(p +是具有标签+的对象的概率)。
如果我们根据参数p +绘制这两个函数,我们将看到熵图非常接近基尼不确定性的图,加倍。因此,在实践中,这两个标准几乎相同。

例
让我们考虑将决策树拟合到一些合成数据中。我们将从两个类生成样本,包括正态分布但具有不同的均值。
# first class
np.random.seed(17)
train_data = np.random.normal(size=(100, 2))
train_labels = np.zeros(100)
# adding second class
train_data = np.r_[train_data, np.random.normal(size=(100, 2), loc=2)]
train_labels = np.r_[train_labels, np.ones(100)]
view raw
让我们绘制数据。非正式地,在这种情况下的分类问题是建立一些将两个类别分开的“好”边界(红点与黄色)。这种情况下的机器学习归结为选择一个良好的分离边界。直线太简单,而每个红点的一些复杂曲线蜿蜒过于复杂,会导致我们在新样本上出错。直观地,一些平滑的边界,或者至少是直线或超平面,可以很好地用于新数据。
plt.rcParams['figure.figsize'] = (10,8)
plt.scatter(train_data[:, 0], train_data[:, 1], c=train_labels, s=100,
cmap='autumn', edgecolors='black', linewidth=1.5);
plt.plot(range(-2,5), range(4,-3,-1));

让我们尝试通过训练Sklearn决策树来分离这两个类。我们将使用max_depth限制树深度的参数。让我们可视化的产生分离边界。
from sklearn.tree import DecisionTreeClassifier
# Let’s write an auxiliary function that will return grid for further visualization.
def get_grid(data):
x_min, x_max = data[:, 0].min() - 1, data[:, 0].max() + 1
y_min, y_max = data[:, 1].min() - 1, data[:, 1].max() + 1
return np.meshgrid(np.arange(x_min, x_max, 0.01), np.arange(y_min, y_max, 0.01))
clf_tree = DecisionTreeClassifier(criterion='entropy', max_depth=3,
random_state=17)
# training the tree
clf_tree.fit(train_data, train_labels)
# some code to depict separating surface
xx, yy = get_grid(train_data)
predicted = clf_tree.predict(np.c_[xx.ravel(),
yy.ravel()]).reshape(xx.shape)
plt.pcolormesh(xx, yy, predicted, cmap='autumn')
plt.scatter(train_data[:, 0], train_data[:, 1], c=train_labels, s=100,
cmap='autumn', edgecolors='black', linewidth=1.5);

树本身看起来如何?我们看到树将“空间”切割成8个矩形,即树有8个叶子。在每个矩形内,树将根据其中对象的多数标签进行预测。
# use .dot format to visualize a tree
from ipywidgets import Image
from io import StringIO
import pydotplus #pip install pydotplus
from sklearn.tree import export_graphviz
dot_data = StringIO()
export_graphviz(clf_tree, feature_names=['x1', 'x2'],
out_file=dot_data, filled=True)
graph = pydotplus.graph_from_dot_data(dot_data.getvalue())
Image(value=graph.create_png())
view raw

我们怎样才能“读”这样一棵树?
最初,有200个样本(实例),每个类100个。初始状态的熵是最大的,S = 1。然后,通过将x2的值与1.211 进行比较,将样本的第一个分区分成2组(在上图中找到边界的这一部分)。由此,左右组的熵减少。该过程持续到深度3.在该可视化中,第一类的样本越多,顶点的橙色越暗; 第二类的样本越多,蓝色的颜色越深。开始时,来自两个类的样本数相等,因此树的根节点是白色的。
决策树如何与数字特征一起工作
假设我们有一个数字特征“Age”,它有很多独特的值。决策树将通过检查诸如“Age <17”,“Age <22.87”等二进制属性来寻找最佳(根据一些信息增益标准)。但如果年龄范围很大怎么办?或者,如果另一个量化变量“薪水”也可以在很多方面“削减”呢?在树构造期间,在每个步骤中将有太多二进制属性可供选择。为解决此问题,通常使用启发式方法来限制我们比较定量变量的阈值数。
让我们考虑一个例子。假设我们有以下数据集:
data = pd.DataFrame({'Age': [17,64,18,20,38,49,55,25,29,31,33],
'Loan Default': [1,0,1,0,1,0,0,1,1,0,1]})
# Let's sort it by age in ascending order.
data.sort_values('Age')

age_tree = DecisionTreeClassifier(random_state=17)
age_tree.fit(data['Age'].values.reshape(-1, 1), data['Loan Default'].values)
dot_data = StringIO()
export_graphviz(age_tree, feature_names=['Age'],
out_file=dot_data, filled=True)
graph = pydotplus.graph_from_dot_data(dot_data.getvalue())
Image(value=graph.create_png())

我们看到树使用以下5个值来评估年龄:43.5,19,22.5,30和32年。如果你仔细观察,这些正是目标类从1到0或0到1的年龄之间的平均值。为了进一步说明,43.5是38和49年的平均值; 一名38岁的客户未能退还贷款,而这位49岁的客户却没有。树查找目标类将其值切换为“切割”定量变量的阈值的值。
鉴于这些信息,为什么你认为考虑像“年龄<17.5”这样的功能是没有意义的?
让我们通过添加“薪水”变量(每年数千美元)来考虑一个更复杂的例子。
data2 = pd.DataFrame({'Age': [17,64,18,20,38,49,55,25,29,31,33],
'Salary': [25,80,22,36,37,59,74,70,33,102,88],
'Loan Default': [1,0,1,0,1,0,0,1,1,0,1]})
data2.sort_values('Age')

如果按年龄排序,目标类(“贷款默认值”)将切换(从1到0或反之亦然)5次。如果我们按工资排序,它会切换7次。树现在如何选择功能?让我们来看看。
age_sal_tree = DecisionTreeClassifier(random_state=17)
age_sal_tree.fit(data2[['Age', 'Salary']].values, data2['Loan Default'].values)
dot_data = StringIO()
export_graphviz(age_sal_tree, feature_names=['Age', 'Salary'],
out_file=dot_data, filled=True)
graph = pydotplus.graph_from_dot_data(dot_data.getvalue())
Image(value=graph.create_png())

我们看到树由工资和年龄划分。此外,特征比较的阈值分别为43.5和22.5岁,每年95k和30.5k。再次,我们看到95是88到102之间的平均值; 工资88k的个人证明是“坏”,而102k的个人是“好”。同样适用于30.5k。也就是说,只搜索了几个按年龄和工资进行比较的值。树为什么选择这些功能?因为他们给出了更好的分区(根据基尼的不确定性)。
结论:在决策树中处理数字特征的最简单的启发式方法是按升序对其值进行排序,并仅检查目标变量值发生变化的阈值。
此外,当数据集中存在大量数字特征时,每个特征具有许多唯一值,仅选择上述阈值的前N个,即仅使用提供最大增益的前N个。该过程是构建深度为1的树,计算熵(或基尼不确定性),并选择最佳阈值进行比较。
为了说明,如果我们按“工资≤34.5”分割,则左子组的熵为0(所有客户端均为“坏”),右侧子组的熵为0.954(3“坏”和5“良好) “,你可以自己检查,因为它将成为任务的一部分)。信息增益大约为0.3。如果我们用“Salary≤95”分割,则左子组的熵为0.97(6“bad”和4“good”),右边的熵为0(一组只包含一个对象)。信息增益约为0.11。如果我们以这种方式计算每个分区的信息增益,我们可以在构建大树之前选择用于比较每个数字特征的阈值(使用所有特征)。
更多数字特征离散化的例子可以在这样或这样的帖子中找到。关于该主题的最着名的科学论文之一是“关于在决策树生成中处理连续值属性”(UM Fayyad.KB Irani,“Machine Learning”,1992)。
关键树参数
从技术上讲,您可以构建一个决策树,直到每个叶子只有一个实例,但这在构建单个树时实际上并不常见,因为它将过度拟合或过于调整到训练集,并且不会预测新数据的标签好。在树的底部,在一个很大的深度,将有不太重要的功能分区(例如客户是来自利兹还是纽约)。我们可以进一步夸大这个故事,发现所有四个来到银行贷款绿色裤子的客户都没有退还贷款。即使在培训中这是真的,我们也不希望我们的分类模型产生这样的特定规则。
有两种例外情况,树木被构建到最大深度:
- 随机森林(一组树)平均构建到最大深度的单个树的响应(稍后我们将讨论为什么要这样做)
- 修剪树木。在这种方法中,树首先被构造成最大深度。然后,从下到上,通过比较具有和不具有该分区的树的质量来移除树的一些节点(使用交叉验证进行比较,更多关于此在下面)。
下图是在过度装配树中构建的分隔边框的示例。
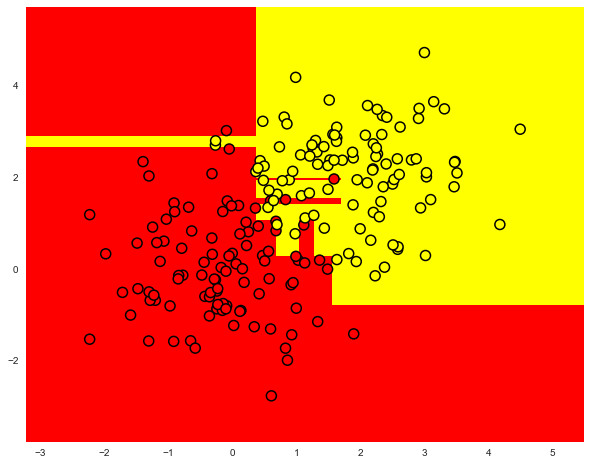
处理决策树中过度拟合的最常见方法如下:
- 人工限制叶子的深度或最小数量的样本:树的构造在某一点停止;
- 修剪树。
Scikit-learn中的类DecisionTreeClassifier
sklearn.tree.DecisionTreeClassifier该类的主要参数是:
max_depth- 树的最大深度;max_features- 用于搜索最佳分区的最大功能数量(这对于大量功能来说是必需的,因为搜索所有功能的分区是“昂贵的” );min_samples_leaf- 叶子中的最小样本数量。此参数可防止创建树,其中任何叶只有少数成员。
树的参数需要根据输入数据进行设置,通常通过交叉验证来完成,下面将详细介绍。
后续持续更新...
更多文章欢迎访问: http://www.apexyun.com
公众号:银河系1号
联系邮箱:[email protected]
(未经同意,请勿转载)