Stream流编程学习笔记
以下笔记内容均是在慕课网上学习流编程时所记录的,如有错误,欢迎指正。
概念
Stream其实就是一个高级的迭代器,它不是一个数据结构,不是一个集合,不会存放数据。它只关注怎么高效处理数据,把数据放入一个流水线中处理。
内部迭代和外部迭代
外部迭代
就是平时我们在对集合或者数组中的数据进行处理时,比如我们求一个数组中所有数字的和,那么我们需要先定义一个外部变量SUM,然后遍历数据,取出数组中的值加在SUM上面。
public static void main(String[] args) {
int[] nums = { 1, 2, 3 };
// 外部迭代
int sum = 0;
for (int i : nums) {
sum += i;
}
System.out.println(sum);
}
内部迭代
利用Stream流编程或者lambda表达式来进行迭代,相对于外部迭代,我们不需要关注它怎么样去处理数据,我们只需要给它数据,然后告诉它我们想要的结果就可以了。不要想外部迭代那样自己定义一些变量。
public static void main(String[] args) {
int[] nums = { 1, 2, 3 };
//内部迭代
int sum = IntStream.of(nums).sum();
System.out.println(sum);
}
两者的区别
1.内部迭代相对来说比较简短,不用关注那么多细节。
2.外部迭代是一个串行的操作,如果数据量过大,性能可能会受影响,这样我们可能就需要自己去做线程池,做拆分。内部迭代的话可以用并行流,达到并行操作,不用开发人员去关系线程的问题。
中间操作、终止操作和惰性求值
中间操作
中间操作就是返回stream流的操作,之前说过stream操作就像流水线一样,在流的整过操作过程中会不断返回一个流。
终止操作
终止操作返回的是一个结果,就是所有中间操作做完以后进行的一个操作,比如汇总,求和等等操作。
public static void main(String[] args) {
int[] nums = { 1, 2, 3 };
// map就是中间操作
//sum就是终止操作
int sum = IntStream.of(nums).map(i -> i + 2).sum();
System.out.println(sum);
}
惰性求值
惰性求值就是在不进行终止操作的情况下,中间操作是不会执行的。
测试如下
public class TestStream {
public static void main(String[] args) {
int[] nums = { 1, 2, 3 };
int sum = IntStream.of(nums).map(TestStream::addNum).sum();
System.out.println(sum);
System.out.println("惰性求值就是在不进行终止操作的情况下,中间操作是不会执行的");
IntStream.of(nums).map(TestStream::addNum);
}
private static int addNum(int i) {
System.out.println("执行了+2操作");
return i + 2;
}
}
结果
执行了+2操作
执行了+2操作
执行了+2操作
12
惰性求值就是在不进行终止操作的情况下,中间操作是不会执行的
可以看出我们在不进行sum这个终止操作,方法引用中的方法时不会执行的,即map中间操作不会执行。
流的创建
一般常规的完整流操作,包括创建流,中间操作,然后终止操作。以下是常见的几种流创建方式

示例
public static void main(String[] args) {
List<String> list = new ArrayList<>();
// 从集合创建流
list.stream();
list.parallelStream();
// 从数组创建
Arrays.stream(new int[] { 1, 2, 3 });
// 创建数字流
IntStream.of(1, 2, 3);
IntStream.range(1, 5);
IntStream.rangeClosed(1, 5);
// 创建无限流,无限流需要用limit控制大小,不然使用报错
new Random().ints().limit(10);
// Stream自己产生流
Stream.generate(() -> new ArrayList<>());
}
流的中间操作
流的中间操作包含两种,一类是无状态操作,一类是有状态操作。
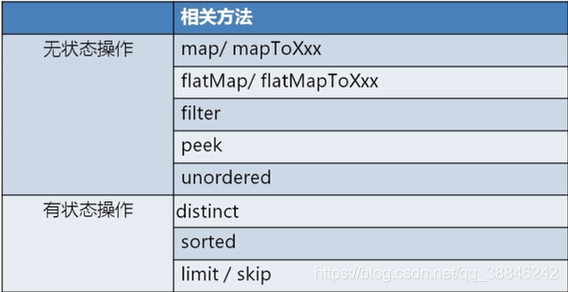
无状态操作
所谓无状态就是一次操作,不能保存数据,线程安全。流中的map,filter这类操作就是无状态,这些操作只是从输入流中获取每一个元素,并且在输出流中得到一个结果,元素和元素之间没有依赖关系,不需要存储数据。
map映射
将流中的元素映射成另外一种元素,接受一个Function类型的参数。
示例
public static void main(String[] args) {
Stream<String> strStream = Arrays.stream(new String[] { "my", "Name", "is", "Eric" });
// 将流中的元素全部转换成大写
strStream.map(str -> str.toUpperCase()).forEach(System.out::println);
}
MY
NAME
IS
ERIC
flatMap映射
flatMap是一种拉平映射,接受一个Function类型的参数,flatMap A->B属性(是一个集合),最终得到A元素中的所有B属性集合。
示例
public static void main(String[] args) {
Stream<String> strStream = Arrays.stream(new String[] { "my", "Name", "is", "Eric" });
// flatMap拉平映射:获取流中元素的字符集合
// 因为flatMap的参数Function的输出是一个Steam,但是String.chars()返回的是一个IntStream
// 而IntStream/LongStream并不是Stream的子类,所以要进行装箱boxed
strStream.flatMap(str -> str.chars().boxed()).forEach(i -> System.out.println((char) i.intValue()));
}
m
y
N
a
m
e
i
s
E
r
i
c
filter过滤
对流中的元素进行过滤操作,接受一个Predicate类型的参数
示例
public static void main(String[] args) {
Stream<String> strStream = Arrays.stream(new String[] { "my", "Name", "is", "Eric" });
// filter过滤出长度大于2的元素
strStream.filter(str -> str.length() > 2).forEach(System.out::println);
}
Name
Eric
peek 操作元素
它提供了一种对流中所有元素操作的方法,由于是中间操作,它不会把流消费掉,那么就可以进行流操作操作。而不像Foreach等终止操作,虽然也能操作流中的元素,但是会把流给消费掉。
Peek操作的参数是一个Consumer
示例
public static void main(String[] args) {
Stream<String> strStream = Arrays.stream(new String[] { "my", "Name", "is", "Eric" });
// peek操作,
strStream.peek(str -> {
System.out.println(str);
}).forEach(System.out::println);
}
my
my
Name
Name
is
is
Eric
Eric
unordered 无序化
unordered 操作不会执行任何操作来显式地对流进行排序。它的作用是消除了流必须保持有序的约束,从而允许后续操作使用不必考虑排序的优化。
在流有序时, 但用户不特别关心该顺序的情况下,使用 unordered 明确地对流进行去除有序约束可以改善某些有状态或终端操作的并行性能。
示例
public static void main(String[] args) {
Stream.of(5, 1, 2, 6, 3, 7, 4).unordered().forEach(System.out::println);
System.out.println("---------");
Stream.of(5, 1, 2, 6, 3, 7, 4).unordered().parallel().forEach(System.out::println);
}
5
1
2
6
3
7
4
---------
3
6
4
7
1
2
5
map与peek的区别
乍看一下map操作和peek操作差不多,其实有了解lambda表达式的就可以知道map和peek的参数是有差别的
map的参数是Function<? super T, ? extends R> mapper ,是一个Function函数,输入T返回R,所以对于map来说是有返回值得,即对流中元素进行操作后可以返回变化了的元素到流中。
peek的参数是Consumer<? super T> action,是一个Consumer函数,输入T而没有返回。所以peek操作没法改变流中的元素,只能做一些输出,外部处理操作。
示例
public static void main(String[] args) {
Stream<String> strStream1 = Arrays.stream(new String[] { "my", "Name", "is", "Eric" });
// map操作,
strStream1.map(str -> str.toUpperCase()).forEach(System.out::println);
System.out.println("---------------------------");
Stream<String> strStream2 = Arrays.stream(new String[] { "my", "Name", "is", "Eric" });
// peek操作,无法改变流中的元素
strStream2.peek(str -> str.toUpperCase()).forEach(System.out::println);
}
MY
NAME
IS
ERIC
---------------------------
my
Name
is
Eric
有状态操作
所谓有状态就是有数据存储功能,线程不安全。流中的sort、distinct、limit、skip这类操作就是有状态的,这些操作需要先知道先前的历史数据,而且需要存储一些数据,元素之间有依赖关系。
distinct去重
对流中的元素进行去重,无参数。
示例
public static void main(String[] args) {
Stream<String> strStream = Arrays.stream(new String[] { "my", "my", "Name", "is", "Eric" });
strStream.distinct().forEach(System.out::println);
}
my
Name
is
Eric
sorted排序
对流中的元素按照进行排序,不带参数的是按照自然顺序进行排序,带参数的会传一个Comparator类型的参数,作为比较规则。
Comparator是在jdk之前就存在的一个函数式接口,入参为两个要比较的元素,返回的是一个integer,负数标识第一个参数小于第二参数,0标识等于,正数标识大于。
示例
public static void main(String[] args) {
Stream<String> strStream = Arrays.stream(new String[] { "stream", "my", "Name", "is", "Eric" });
// 元素按长度从长到短排序
strStream.sorted((s1, s2) -> {
return s2.length() - s1.length();
}).forEach(System.out::println);
}
stream
Name
Eric
my
is
limit限流
获取流中前n个元素返回,在用无限流的时候可以起到限流的作用。
示例
public static void main(String[] args) {
Stream<String> strStream = Arrays.stream(new String[] { "stream", "my", "Name", "is", "Eric" });
// limit获取前2个元素
strStream.limit(2).forEach(System.out::println);
}
stream
my
skip跳过
跳过流中的前n个元素。
示例
public static void main(String[] args) {
Stream<String> strStream = Arrays.stream(new String[] { "stream", "my", "Name", "is", "Eric" });
// skip跳过前2个元素
strStream.skip(2).forEach(System.out::println);
}
Name
is
Eric
limit配合skip达成分页效果
对于不方便用分页插件和手写分页的情况,可以使用limit+skip的形式对结果集进行分页处理。
示例
public static void main(String[] args) {
Stream<String> strStream = Arrays.stream(new String[] { "stream", "my", "Name", "is", "Eric" });
// limit配合skip进行分页
long pageSize = 2;
long pageNumber = 2;
strStream.skip(pageSize*pageNumber).limit(pageSize).forEach(System.out::println);
}
Eric
流的终止操作
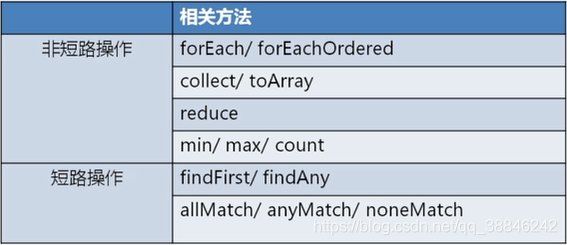
非短路操作
非短路操作可以批量处理数据,但是需要处理完全部元素才会返回结果
forEach/forEachOrdered
forEach用的很多了,就是遍历数据。forEachOrdered也一样,只是它一般在并行流时用,可以保持元素的顺序
示例
public static void main(String[] args) {
// 并行流
Arrays.stream(new String[] { "stream", "my", "Name", "is", "Eric" }).parallel()
.forEach(str -> System.out.println(str));
System.out.println("-------------------------------");
// 使用forEachOrdered保证在并行流的情况下元素的顺序
Arrays.stream(new String[] { "stream", "my", "Name", "is", "Eric" }).parallel()
.forEachOrdered(str -> System.out.println(str));
}
Name
stream
Eric
my
is
-------------------------------
stream
my
Name
is
Eric
collect/toArray
collect可以对流中元素执行一个可变汇聚操作,比如:将流中的元素放入到一个List集合当中,将流中的元素进行分组、分区,求和等等操作。接受一个收集器Collector对象
示例
public static void main(String[] args) {
// collect收集器
List<String> list = Arrays.stream(new String[] { "stream", "my", "Name", "is", "Eric" })
.collect(Collectors.toList());
System.out.println(list);
}
[stream, my, Name, is, Eric]
toArray相对来说比较简单,即将流中的数据收集成一个Object类型的数组
public static void main(String[] args) {
// toArray收集器
Object[] array = Arrays.stream(new String[] { "stream", "my", "Name", "is", "Eric" }).toArray();
System.out.println(array);
}
reduce
这个方法的主要作用是把 Stream 元素组合起来。它提供一个起始值(种子),然后依照运算规则(BinaryOperator),和前面 Stream 的第一个、第二个、第 n 个元素组合。从这个意义上说,字符串拼接、数值的 sum、min、max、average 都是特殊的 reduce。
示例
public static void main(String[] args) {
String string = "my name is eric";
// reduce
Optional<String> result = Stream.of(string.split(" ")).reduce((s1, s2) -> s1 + "|" + s2);
System.out.println(result.orElse(""));
}
my|name|is|eric
Optional是jdk8中新增的类,它对类简单封装。变量不存在时,缺失的值会被建模成一个“空”的Optional对象,由方法Optional.empty()返回。
我们在使用reduce时可以设置初始值,这样就不会返回Optional。
public static void main(String[] args) {
String string = "my name is eric";
// 带初始值的reduce
String result = Stream.of(string.split(" ")).reduce("", (s1, s2) -> s1 + "|" + s2);
System.out.println(result);
}
|my|name|is|eric
min、max、count
求最大值最小值,计算流中元素的个数。min、max的参数是一个Comparator,之前已经说过,其实就是一个比较器函数。
public static void main(String[] args) {
String string = "my name is eric";
// min
Optional<String> min = Stream.of(string.split(" ")).min((s1, s2) -> s1.length() - s2.length());
System.out.println(min.orElse(""));
// min
Optional<String> max = Stream.of(string.split(" ")).max((s1, s2) -> s1.length() - s2.length());
System.out.println(max.orElse(""));
}
my
name
短路操作
短路操作是指不用处理全部元素就可以返回结果。短路操作必须一个元素处理一次。
findFirst、 findAny
findFirst表示找到第一个元素。找到了就直接返回,不在遍历后面元素。
findAny表示找到任何一个元素就会返回。
anyMatch、 allMatch、 noneMatch
allMatch:Stream 中全部元素符合传入的 predicate,返回 true,只要有一个不满足就返回false
anyMatch:Stream 中只要有一个元素符合传入的 predicate,返回 true。否则返回false
noneMatch:Stream 中没有一个元素符合传入的 predicate,返回 true。只要有一个满足就返回false
public static void main(String[] args) {
String string = "my name is eric";
//allMatch 所有的字符串包含m就返回true,否则false
boolean allMatch = Stream.of(string.split(" ")).allMatch(i -> i.contains("m"));
System.out.println(allMatch);
//anyMatch 只要有一个字符串包含m就返回true
boolean anyMatch = Stream.of(string.split(" ")).anyMatch(i -> i.contains("m"));
System.out.println(anyMatch);
//noneMatch 没有一个字符串包含m就返回true,有一个包含就返回false
boolean noneMatch = Stream.of(string.split(" ")).noneMatch(i -> i.contains("m"));
System.out.println(noneMatch);
}
false
true
false
并行流
获取并行流
可以通过流的parallel()来获取一个并行流,对于获取并行流,有几点需要注意。
1.并行流需要环节支持,不然就算获取了并行流,反而运行效率会变低。
2.多次调用parallel()和sequential()(获取串行流),以最后一次为准。
并行流的线程池
流的并行操作的线程数默认是机器的CPU个数。默认使用的线程池是ForkJoinPool.commonPool线程池。
public class TestStream1 {
public static void main(String[] args) {
IntStream.range(1, 100).parallel().peek(TestStream1::debug).count();
}
public static void debug(int i) {
System.out.println(Thread.currentThread().getName() + "debug" + i);
try {
TimeUnit.SECONDS.sleep(3);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
ForkJoinPool.commonPool-worker-2debug87
ForkJoinPool.commonPool-worker-3debug13
ForkJoinPool.commonPool-worker-1debug31
maindebug62
ForkJoinPool.commonPool-worker-2debug88
ForkJoinPool.commonPool-worker-1debug32
ForkJoinPool.commonPool-worker-3debug14
maindebug63
使用自定义线程池
使用自己的线程池可以防止当前流操作被其他流操作的线程阻塞
public class TestStream {
public static void main(String[] args) {
ForkJoinPool pool = new ForkJoinPool(20);
pool.submit(() -> IntStream.range(1, 100).parallel().peek(TestStream::debug).count());
pool.shutdown();
// 让主线程不退出
synchronized (pool) {
try {
pool.wait();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
public static void debug(int i) {
System.out.println(Thread.currentThread().getName() + "debug" + i);
try {
TimeUnit.SECONDS.sleep(3);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
ForkJoinPool-1-worker-25debug62
ForkJoinPool-1-worker-18debug31
ForkJoinPool-1-worker-11debug87
ForkJoinPool-1-worker-4debug13
ForkJoinPool-1-worker-29debug43
ForkJoinPool-1-worker-22debug81
ForkJoinPool-1-worker-15debug93
收集器
对流中元素执行一个可变汇聚操作,是一个终止操作。比如:将流中的元素放入到一个List集合当中,将流中的元素进行分组、分区,求和等等操作。接受一个收集器Collector对象。
常用的收集器有以下几种
toList/toSet
收集成一个List集合/Set集合,当然也可以指定集合类型
public static void main(String[] args) {
List<Student> students = Arrays.asList(
new Student("小明", 10, Gender.MALE, Grade.ONE),
new Student("大明", 9, Gender.MALE, Grade.THREE),
new Student("小白", 8, Gender.FEMALE, Grade.TWO),
new Student("小黑", 13, Gender.FEMALE, Grade.FOUR),
new Student("小红", 7, Gender.FEMALE, Grade.THREE),
new Student("小黄", 13, Gender.MALE, Grade.ONE),
new Student("小青", 13, Gender.FEMALE, Grade.THREE),
new Student("小紫", 9, Gender.FEMALE, Grade.TWO),
new Student("小王", 6, Gender.MALE, Grade.ONE),
new Student("小李", 6, Gender.MALE, Grade.ONE),
new Student("小马", 14, Gender.FEMALE, Grade.FOUR),
new Student("小刘", 13, Gender.MALE, Grade.FOUR));
//收集成list
List<Integer> ageList = students.stream().map(Student::getAge).collect(Collectors.toList());
System.out.println("所有学生的年龄:"+ageList);
//收集成set
Set<Integer> ageSet = students.stream().map(Student::getAge).collect(Collectors.toSet());
System.out.println("所有学生的年龄-去重:"+ageSet);
//指定集合treeset
TreeSet<Integer> ageTreeSet = students.stream().map(Student::getAge).collect(Collectors.toCollection(TreeSet::new));
System.out.println("所有学生的年龄-去重-treeSet:"+ageTreeSet);
}
所有学生的年龄:[10, 9, 8, 13, 7, 13, 13, 9, 6, 6, 14, 13]
所有学生的年龄-去重:[6, 7, 8, 9, 10, 13, 14]
所有学生的年龄-去重-treeSet:[6, 7, 8, 9, 10, 13, 14]
summarizingInt/Double/Long
统计汇总信息
public static void main(String[] args) {
List<Student> students = Arrays.asList(
new Student("小明", 10, Gender.MALE, Grade.ONE),
new Student("大明", 9, Gender.MALE, Grade.THREE),
new Student("小白", 8, Gender.FEMALE, Grade.TWO),
new Student("小黑", 13, Gender.FEMALE, Grade.FOUR),
new Student("小红", 7, Gender.FEMALE, Grade.THREE),
new Student("小黄", 13, Gender.MALE, Grade.ONE),
new Student("小青", 13, Gender.FEMALE, Grade.THREE),
new Student("小紫", 9, Gender.FEMALE, Grade.TWO),
new Student("小王", 6, Gender.MALE, Grade.ONE),
new Student("小李", 6, Gender.MALE, Grade.ONE),
new Student("小马", 14, Gender.FEMALE, Grade.FOUR),
new Student("小刘", 13, Gender.MALE, Grade.FOUR));
IntSummaryStatistics ageSummaryStatistics = students.stream()
.collect(Collectors.summarizingInt(Student::getAge));
System.out.println("学生年龄汇总信息:"+ageSummaryStatistics);
}
学生年龄汇总信息:IntSummaryStatistics{count=12, sum=121, min=6, average=10.083333, max=14}
partitioningBy 分块
将数据按一定规则分成两块,输入参数是一个断言Predicate
public static void main(String[] args) {
List<Student> students = Arrays.asList(
new Student("小明", 10, Gender.MALE, Grade.ONE),
new Student("大明", 9, Gender.MALE, Grade.THREE),
new Student("小白", 8, Gender.FEMALE, Grade.TWO),
new Student("小黑", 13, Gender.FEMALE, Grade.FOUR),
new Student("小红", 7, Gender.FEMALE, Grade.THREE),
new Student("小黄", 13, Gender.MALE, Grade.ONE),
new Student("小青", 13, Gender.FEMALE, Grade.THREE),
new Student("小紫", 9, Gender.FEMALE, Grade.TWO),
new Student("小王", 6, Gender.MALE, Grade.ONE),
new Student("小李", 6, Gender.MALE, Grade.ONE),
new Student("小马", 14, Gender.FEMALE, Grade.FOUR),
new Student("小刘", 13, Gender.MALE, Grade.FOUR));
Map<Boolean, List<Student>> genders = students.stream()
.collect(Collectors.partitioningBy(s -> s.getGender() == Gender.MALE));
System.out.println("男女生列表:"+genders);
}
男女生列表 =
{
false = [Student [name=小白, age=8, gender=FEMALE, grade=TWO], Student [name=小黑, age=13, gender=FEMALE, grade=FOUR], Student [name=小红, age=7, gender=FEMALE, grade=THREE], Student [name=小青, age=13, gender=FEMALE, grade=THREE], Student [name=小紫, age=9, gender=FEMALE, grade=TWO], Student [name=小马, age=14, gender=FEMALE, grade=FOUR]]
true = [Student [name=小明, age=10, gender=MALE, grade=ONE], Student [name=大明, age=9, gender=MALE, grade=THREE], Student [name=小黄, age=13, gender=MALE, grade=ONE], Student [name=小王, age=6, gender=MALE, grade=ONE], Student [name=小李, age=6, gender=MALE, grade=ONE], Student [name=小刘, age=13, gender=MALE, grade=FOUR]]
}
groupingBy 分组
将数据按一定规则分成几组,相对于分块,分组要灵活很多,输入参数是一个Function。
public static void main(String[] args) {
List<Student> students = Arrays.asList(
new Student("小明", 10, Gender.MALE, Grade.ONE),
new Student("大明", 9, Gender.MALE, Grade.THREE),
new Student("小白", 8, Gender.FEMALE, Grade.TWO),
new Student("小黑", 13, Gender.FEMALE, Grade.FOUR),
new Student("小红", 7, Gender.FEMALE, Grade.THREE),
new Student("小黄", 13, Gender.MALE, Grade.ONE),
new Student("小青", 13, Gender.FEMALE, Grade.THREE),
new Student("小紫", 9, Gender.FEMALE, Grade.TWO),
new Student("小王", 6, Gender.MALE, Grade.ONE),
new Student("小李", 6, Gender.MALE, Grade.ONE),
new Student("小马", 14, Gender.FEMALE, Grade.FOUR),
new Student("小刘", 13, Gender.MALE, Grade.FOUR));
Map<Grade, List<Student>> grades = students.stream()
.collect(Collectors.groupingBy(Student::getGrade));
MapUtils.verbosePrint(System.out, "学生班级列表", grades);
}
学生班级列表 =
{
THREE = [Student [name=大明, age=9, gender=MALE, grade=THREE], Student [name=小红, age=7, gender=FEMALE, grade=THREE], Student [name=小青, age=13, gender=FEMALE, grade=THREE]]
ONE = [Student [name=小明, age=10, gender=MALE, grade=ONE], Student [name=小黄, age=13, gender=MALE, grade=ONE], Student [name=小王, age=6, gender=MALE, grade=ONE], Student [name=小李, age=6, gender=MALE, grade=ONE]]
FOUR = [Student [name=小黑, age=13, gender=FEMALE, grade=FOUR], Student [name=小马, age=14, gender=FEMALE, grade=FOUR], Student [name=小刘, age=13, gender=MALE, grade=FOUR]]
TWO = [Student [name=小白, age=8, gender=FEMALE, grade=TWO], Student [name=小紫, age=9, gender=FEMALE, grade=TWO]]
}
groupingBy 分组以后,可以看到每一组还是一个集合,这个集合也是可以进行收集操作的。groupingBy 有一个重载的方法
groupingBy(Function<? super T, ? extends K> classifier, Collector<? super T, A, D> downstream),第二个参数是一个Collector
public static void main(String[] args) {
List<Student> students = Arrays.asList(
new Student("小明", 10, Gender.MALE, Grade.ONE),
new Student("大明", 9, Gender.MALE, Grade.THREE),
new Student("小白", 8, Gender.FEMALE, Grade.TWO),
new Student("小黑", 13, Gender.FEMALE, Grade.FOUR),
new Student("小红", 7, Gender.FEMALE, Grade.THREE),
new Student("小黄", 13, Gender.MALE, Grade.ONE),
new Student("小青", 13, Gender.FEMALE, Grade.THREE),
new Student("小紫", 9, Gender.FEMALE, Grade.TWO),
new Student("小王", 6, Gender.MALE, Grade.ONE),
new Student("小李", 6, Gender.MALE, Grade.ONE),
new Student("小马", 14, Gender.FEMALE, Grade.FOUR),
new Student("小刘", 13, Gender.MALE, Grade.FOUR));
Map<Grade, Long> gradesCount = students.stream()
.collect(Collectors.groupingBy(Student::getGrade,Collectors.counting()));
MapUtils.verbosePrint(System.out, "班级学生个数列表", gradesCount);
}
班级学生个数列表 =
{
FOUR = 3
TWO = 2
ONE = 4
THREE = 3
}
Stream的运行机制
1.所有的操作都是链式调用,一个元素只迭代一次。
public static void main(String[] args) {
Stream.generate(() -> new Random().nextInt()).limit(10)
// 第一个无状态操作
.peek(s -> print("peek:" + s))
// 第二个无状态操作
.filter(s -> {
print("filter:" + s);
return s > 1000000;
})
// 终止操作
.count();
}
private static void print(String string) {
System.err.println(string);
}
先执行peek,再执行filter
peek:1371982675
filter:1371982675
peek:-1145718874
filter:-1145718874
peek:-878943922
filter:-878943922
peek:1584470948
filter:1584470948
peek:-1035083327
filter:-1035083327
peek:1305239996
filter:1305239996
peek:-521348180
filter:-521348180
peek:-707884835
filter:-707884835
peek:1158291746
filter:1158291746
peek:581375981
filter:581375981
2.每一个中间操作返回一个新的流, 每个流里面有一个属性sourceStage指向同一个地方-链表的头Head
3.在Head里面就会指向nextStage,head->nextStage->nextStage->…->null
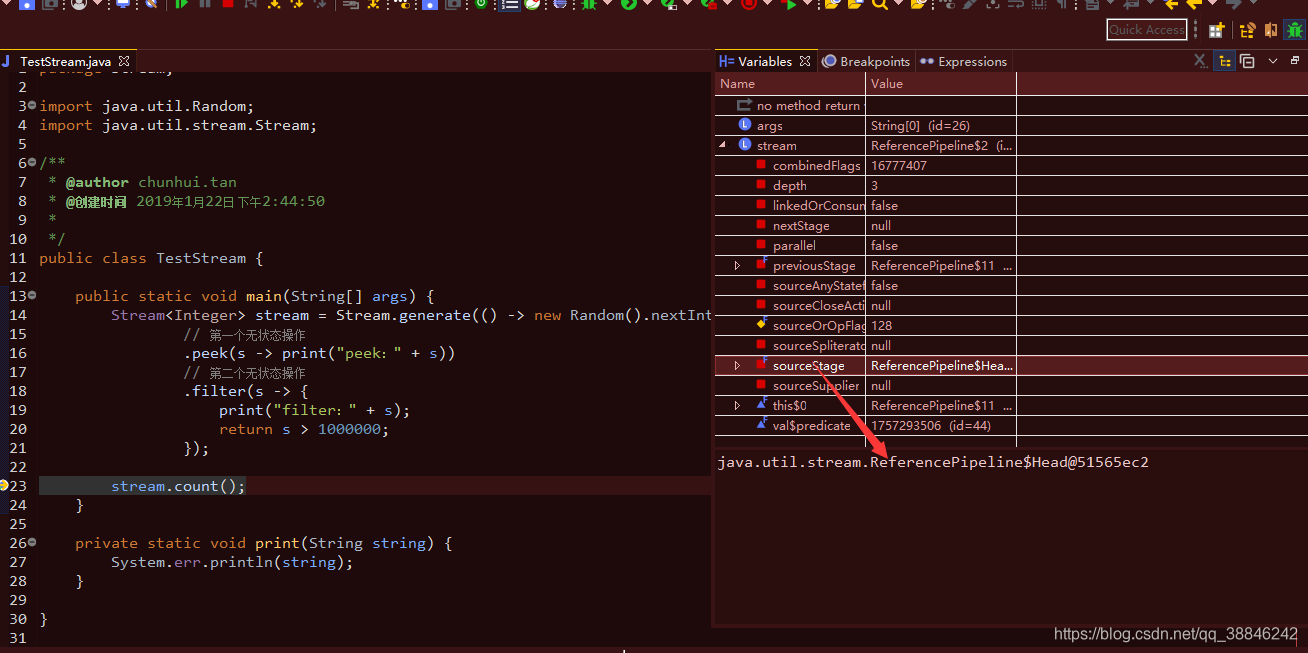
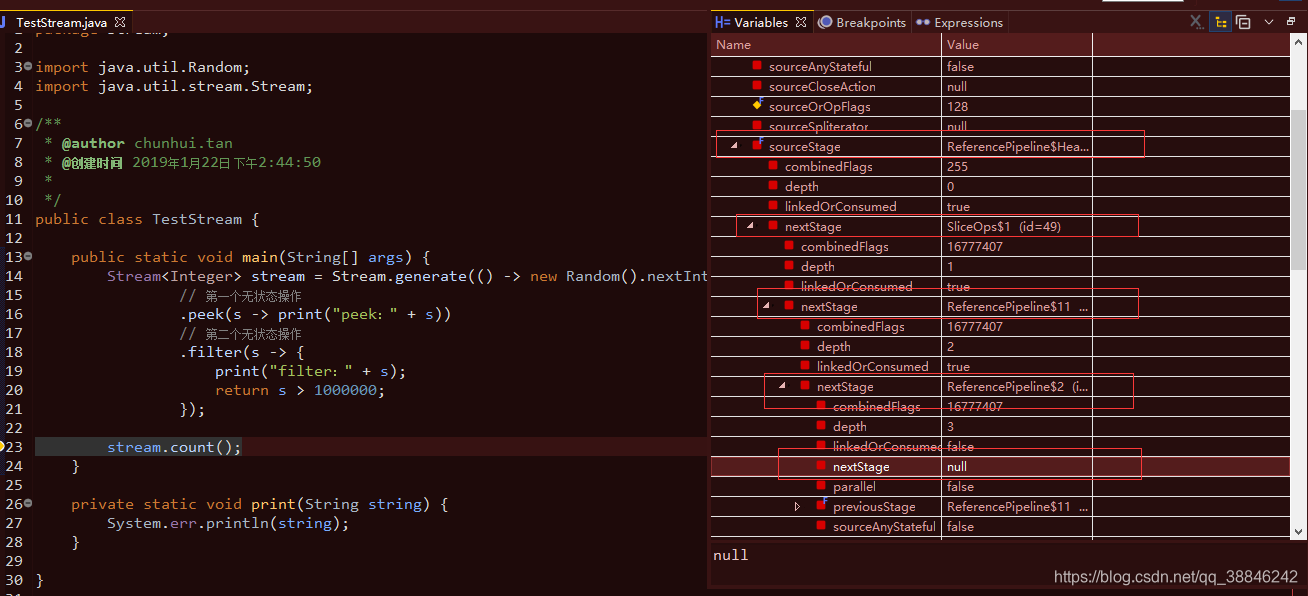
4.有状态操作会把无状态操作截断,单独处理。
public static void main(String[] args) {
Stream<Integer> stream = Stream.generate(() -> new Random().nextInt()).limit(10)
// 第一个无状态操作
.peek(s -> print("peek1:" + s))
// 第二个无状态操作
.filter(s -> {
print("filter:" + s);
return s > 1000000;
})
//有状态操作
.sorted((i1,i2)->{
print("排序:"+i1+","+i2);
return i1.compareTo(i2);
})
//又一个无状态操作
.peek(s->print("peek2:"+s));
stream.count();
}
private static void print(String string) {
System.err.println(string);
}
peek1:748653802
filter:748653802
peek1:-1773848762
filter:-1773848762
peek1:2087185768
filter:2087185768
peek1:-1655622749
filter:-1655622749
peek1:-402135935
filter:-402135935
peek1:205570662
filter:205570662
peek1:31204326
filter:31204326
peek1:1845977972
filter:1845977972
peek1:-1537361216
filter:-1537361216
peek1:784418248
filter:784418248
排序:2087185768,748653802
排序:205570662,2087185768
排序:205570662,2087185768
排序:205570662,748653802
排序:31204326,748653802
排序:31204326,205570662
排序:1845977972,748653802
排序:1845977972,2087185768
排序:784418248,748653802
排序:784418248,2087185768
排序:784418248,1845977972
peek2:31204326
peek2:205570662
peek2:748653802
peek2:784418248
peek2:1845977972
peek2:2087185768
5.并行环节下,有状态的中间操作不一定能并行操作,并且,被有状态操作隔断的之前的无状态操作也不一定能并行操作。如下,其中.parallel()在中间操作的最后加上和开始就加上,效果是一样的。
public static void main(String[] args) {
Stream<Integer> stream = Stream.generate(() -> new Random().nextInt()).limit(10)
// 第一个无状态操作
.peek(s -> print("peek1:" + s))
// 第二个无状态操作
.filter(s -> {
print("filter:" + s);
return s > 1000000;
})
//有状态操作
.sorted((i1,i2)->{
print("排序:"+i1+","+i2);
return i1.compareTo(i2);
})
//又一个无状态操作
.peek(s->print("peek2:"+s))
//并行
.parallel();
stream.count();
}
private static void print(String string) {
System.err.println(Thread.currentThread().getName()+"->"+string);
}
可以看到peek1和filter这两个无状态操作不是并行运行的,使用的是一个线程ForkJoinPool.commonPool-worker-3。排序是在main线程中执行的。
ForkJoinPool.commonPool-worker-3->peek1:-1579655556
ForkJoinPool.commonPool-worker-3->filter:-1579655556
ForkJoinPool.commonPool-worker-3->peek1:952457888
ForkJoinPool.commonPool-worker-3->filter:952457888
ForkJoinPool.commonPool-worker-3->peek1:-863671158
ForkJoinPool.commonPool-worker-3->filter:-863671158
ForkJoinPool.commonPool-worker-3->peek1:-399451653
ForkJoinPool.commonPool-worker-3->filter:-399451653
ForkJoinPool.commonPool-worker-3->peek1:1680077762
ForkJoinPool.commonPool-worker-3->filter:1680077762
ForkJoinPool.commonPool-worker-3->peek1:-395699073
ForkJoinPool.commonPool-worker-3->filter:-395699073
ForkJoinPool.commonPool-worker-3->peek1:769813179
ForkJoinPool.commonPool-worker-3->filter:769813179
ForkJoinPool.commonPool-worker-3->peek1:151702238
ForkJoinPool.commonPool-worker-3->filter:151702238
ForkJoinPool.commonPool-worker-3->peek1:2003058652
ForkJoinPool.commonPool-worker-3->filter:2003058652
ForkJoinPool.commonPool-worker-3->peek1:698152607
ForkJoinPool.commonPool-worker-3->filter:698152607
main->排序:1680077762,952457888
main->排序:769813179,1680077762
main->排序:769813179,1680077762
main->排序:769813179,952457888
main->排序:151702238,952457888
main->排序:151702238,769813179
main->排序:2003058652,952457888
main->排序:2003058652,1680077762
main->排序:698152607,952457888
main->排序:698152607,769813179
main->排序:698152607,151702238
ForkJoinPool.commonPool-worker-3->peek2:2003058652
main->peek2:952457888
ForkJoinPool.commonPool-worker-3->peek2:1680077762
ForkJoinPool.commonPool-worker-1->peek2:151702238
ForkJoinPool.commonPool-worker-2->peek2:698152607
main->peek2:769813179
6.parallel/sequetial这两个操作也是中间操作,但是他们不创建流,他们只修改流中Head的并行标志。
