scrapy框架使用学习笔记
scrapy 框架是python中最活跃、最著名、相对成熟的爬虫框架。像一个半成品的爬虫,已经为我们实现了工作队列、下载器、保存处理数据的逻辑,以及日志、异常处理等功能。使用scrapy框架更像做填空题,更多的工作是配置这个爬虫框架,针对具体要爬取的网站,编写相应的爬取规则,而诸如多线程下载、异常处理等,交给框架来实现即可。
1.scrapy框架的安装
scrapy框架安装Windows:
conda install scrapy
安装后查看是否成功安装:
scrapy version
2.scrapy框架下的项目创建
cd D:
cd py19
scrapy startproject project_name

上述创建的新的项目spider-test在D://py19/ 路径下,它的目录结构如下:
spider-test/
scrapy.cfg #项目配置文件,一般不用设置
spider-test/
__init__.py
items.py #定义爬取什么数据
middlewares.py #对所有发出的请求、收到的响应或者爬虫做全局性的自定义设置
pipelines.py#处理已爬取到的数据,如:items去重,或保存数据到数据库
settings.py #爬虫框架设置文件
spiders/ #文件下用于存放编写的爬虫代码,即主要的爬虫逻辑在这里面定义
__init__.py
使用 scrapy startproject spider-test 生成爬虫项目后,命令行下有以下提示:
cd spider-test #进入爬虫项目
scrapy genspider example example.com #生成爬虫文件
#其中,example表示爬虫名字;example.com表示爬虫网址
scrapy genspider baidu baidu.com
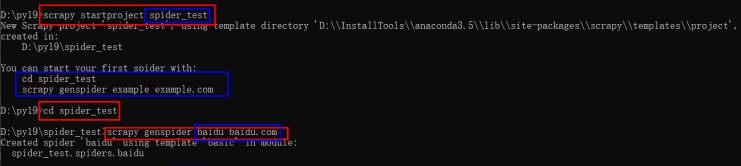
上面的命令执行完成后,在spiders文件夹下会生成一个名称为baidu.py的爬虫文件。
3.百度爬虫实现
假定要爬取百度首页右上角“新闻”链接的名称和它的URL。
(1)定义要爬取的数据:
items.py 是用于定义爬取数据的容器,定义要爬取哪些字段的数据,打开items.py 文件,看到如下默认代码:
import scrapy
class SpiderTestItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
pass
上述默认代码给人很好的提示,即使用类似来定义要提取的字段,此处需要提取两个字段,一个是栏目(title),另一个是栏目对应的url (title_url) ,因此将items.py的代码改成如下形式:
import scrapy
class SpiderTestItem(scrapy.Item):
# define the fields for your item here like:
title = scrapy.Field()
title_url = scrapy.Field()
(2)编写爬虫文件
打开soiders文件夹下的baidu.py 爬虫文件,将看到如下代码:
import scrapy
class BaiduSpider(scrapy.Spider):
name = 'baidu'
allowed_domains = ['baidu.com']
start_urls = ['https://baidu.com/']
def parse(self, response):
pass
上面为爬虫框架生成的爬虫文件模板,可在这个模板基础上增加具体的提取规则、解析方法等。具体修改完后的baidu.py代码如下所示:
import scrapy
from spider_test.items import SpiderTestItem #引入Item类
class BaiduSpider(scrapy.Spider):
name = 'baidu'
allowed_domains = ['baidu.com']
start_urls = ['https://baidu.com/']
def parse(self, response):
item = SpiderTestItem() #初始化Item类的数据容器
#提取新闻这个栏目名称
item['title'] = response.xpath('//*[@id="u1"]/a[1]/text()').extract()[0]
#提取新闻这个栏目名称对应的URL
item['title_url '] = response.xpath('//*[@id="u1"]/a[1]/@href').extract_first()
print(item['title'])
print(item['title_url'])
return item
***注:***items数据容器的使用语法类似Python字典。Scrapy爬虫框架为了提取真实的原文数据,需要调用extract() 序列化提取节点为unicode字符串,这样提取出来的是全部匹配元素的列表,因此提取第一个可写为extract()[0] 或 extract_first() ,二者等价。
至此,百度Scrapy爬虫框架已编写完成。再在命令行窗口定位到项目的根目录,使用如下命令运行这个爬虫:
#scrapy crawl example
scrapy crawl baidu
这是就运行了Scrapy百度爬虫,但是可能在屏幕上没有看到代码中的打印结果,而是发现类似Forbidden by robots.txt 这样的提示。这是因为新版本的Scrapy爬虫框架默认遵守robots协议,设置Scrapy爬虫框架的settings.py中的ROBOTSTXT_OBEY = True 为 ROBOTSTXT_OBEY = False即可。然后再次运行:scrapy crawl baidu
顺利的话,屏幕上会看到打印爬取结果,如下图所示:
