(本篇文章翻译自:https://www.kaggle.com/dansbecker/how-models-work)
介绍
我们先大概了解机器学习模型的工作方式和使用方法。如果你之前有做过统计建模或者机器学习方面的工作,可能会觉得这节课程很基础。别担心,我们将会很快建立强大的模型。
本节微课程将会让你在以下场景建立模型:
你表哥做了几百万美元的房地产投机买卖。因为你对数据科学感兴趣,他提出想和你成为商业伙伴。由他提供资金,你提供房屋价值预测模型。
你问你表哥他之前是怎么做房地产价值预测的,他说凭直觉。但更多的怀疑表表明,他已经从过去的交易中找到了价格模式,并利用这个模式对新的房屋进行预测。
机器学习的工作原理也是如此。我们将从决策树模型开始学习,虽然有其他更复杂的模型能提供更精确的预测,但决策树比较容易理解,它是数据科学中一些其他最佳模型的基础。
简单起见,我们从最简单的可能决策树开始。
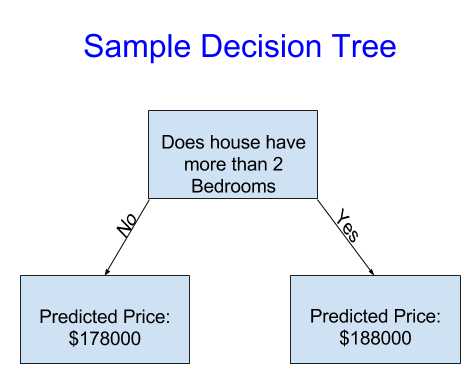
它把房屋分为两类,根据同类房屋的历史均价做出预测。
我们使用数据来决定如何将房屋分成两组,然后再确定每组的预测价格。从数据中获得模式的步骤,称为训练模型。用于训练模型的数据,称为训练数据。
训练模型的内部细节(例如怎样分隔数据)很复杂,我们以后再讨论。模型训练好之后,你可以将它运用到其他房屋价格的预测。
改进决策树
以下两个决策树,哪个更可能是通过训练房地产数据得到的?
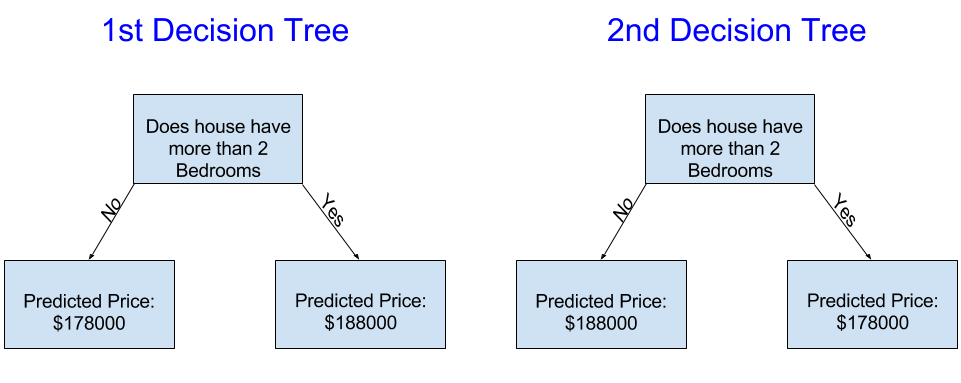
左侧的决策树(决策树1)可能更有意义,因为它捕捉到了这样一个事实,即房屋的卧室越多,其价格更高。这种模式最大的缺点是,它没有捕捉到影响房价的大多数因素,例如浴室数量、地块大小、位置等。
可以用更多分来支捕捉更多因素,这样的决策树更深。加入了房屋总面积的决策树如下:
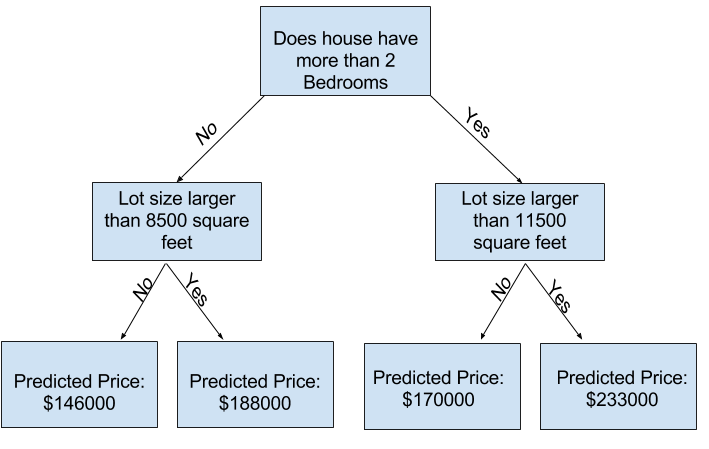
可以通过选择与房屋特征相对应的路径,来预测其他房屋的价格。房屋的预测价格在最底部,也叫叶子结点。
叶子的拆分和值,由数据决定。接下来我们开始检查和使用数据。
使用Pandas熟悉你的数据
任何机器学习项目的第一步都是熟悉数据,我们将用Pandas库来做这个。Pandas是科学家用来探索和操纵数据的主要工具,大部分人将它简称为pd。执行以下命令来导入Pandas库:
import pandas as pd
Pandas库重要的部分是数据框架,它保存你可能认为是表的数据类型。这类似于Excel中的工作表或SQL数据库中的表。
Pandas有各种强大的方法来处理数据。
例如,我们要查看澳大利亚墨尔本的房价数据。在练习中,你将对一个新的数据集应用相同的处理过程,该数据集有爱荷华州的房价。
示例(墨尔本)数据位于文件路径:
../input/melbourne-housing-snapshot/melb_data.csv
我们使用以下命令加载和浏览数据:
# save filepath to variable for easier access
melbourne_file_path = '../input/melbourne-housing-snapshot/melb_data.csv'
# read the data and store data in DataFrame titled melbourne_data
melbourne_data = pd.read_csv(melbourne_file_path)
# print a summary of the data in Melbourne data
melbourne_data.describe()
输出如下:
| Rooms | Price | Distance | Postcode | Bedroom2 | Bathroom | Car | Landsize | BuildingArea | YearBuilt | Lattitude | Longtitude | Propertycount | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| count | 13580.000000 | 1.358000e+04 | 13580.000000 | 13580.000000 | 13580.000000 | 13580.000000 | 13518.000000 | 13580.000000 | 7130.000000 | 8205.000000 | 13580.000000 | 13580.000000 | 13580.000000 |
| mean | 2.937997 | 1.075684e+06 | 10.137776 | 3105.301915 | 2.914728 | 1.534242 | 1.610075 | 558.416127 | 151.967650 | 1964.684217 | -37.809203 | 144.995216 | 7454.417378 |
| std | 0.955748 | 6.393107e+05 | 5.868725 | 90.676964 | 0.965921 | 0.691712 | 0.962634 | 3990.669241 | 541.014538 | 37.273762 | 0.079260 | 0.103916 | 4378.581772 |
| min | 1.000000 | 8.500000e+04 | 0.000000 | 3000.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 1196.000000 | -38.182550 | 144.431810 | 249.000000 |
| 25% | 2.000000 | 6.500000e+05 | 6.100000 | 3044.000000 | 2.000000 | 1.000000 | 1.000000 | 177.000000 | 93.000000 | 1940.000000 | -37.856822 | 144.929600 | 4380.000000 |
| 50% | 3.000000 | 9.030000e+05 | 9.200000 | 3084.000000 | 3.000000 | 1.000000 | 2.000000 | 440.000000 | 126.000000 | 1970.000000 | -37.802355 | 145.000100 | 6555.000000 |
| 75% | 3.000000 | 1.330000e+06 | 13.000000 | 3148.000000 | 3.000000 | 2.000000 | 2.000000 | 651.000000 | 174.000000 | 1999.000000 | -37.756400 | 145.058305 | 10331.000000 |
| max | 10.000000 | 9.000000e+06 | 48.100000 | 3977.000000 | 20.000000 | 8.000000 | 10.000000 | 433014.000000 | 44515.000000 | 2018.000000 | -37.408530 | 145.526350 | 21650.000000 |
数据解释
结果显示原始数据集中每列有8个数字。第一个数字count显示有多少未丢失数据行。
丢失数据有很多原因。例如,在测量只有一件卧室的房屋时,第二间卧室大小的值将缺失。
第二个值是平均值。在这种情况下,std就是标准差,它测量数值的分布情况。
要解释min、25%、50%、75%和max,请设想按每列数据从低到高排序。第一个(最小的)值是min。如果你浏览列表的四分之一,你会发现一个大于值的25%且小于值的75%的数字。这是25%的值(读作“25%”)。50%和75%的定义类似,最大值是最大的。
轮到你了
开始你的第一个编码练习。